
Dask(دسک) یک کتابخانه متن باز برای پردازش کلان داده (Big Data) و محاسبات موازی با استفاده از پایتون است. که محاسبات موازی کاربردی را بر روی ماشین های جداگانه با استفاده از پردازنده های چند هسته ای آنها و جریان کارآمد داده ها امکان پذیر می کند.در این مقاله قصد داریم به یک تعریف اولیه و آموزش نصب و راه اندازی dask بپردازیم .
Dask از دو قسمت تشکیل شده است .
۱.برنامه ریزی کارها به صورت دینامیک و پویا در محاسبات
۲.قسمت کلان داده یا bigdata که استقاده از آرایه های موازی ، دیتافریم ها و کتابخانه های رایج مانند NumPy ، Pandas یا Python iterators را برای محیط های بزرگتر از حافظه و محیط های توزیع شده امکان پذیر می کنند.

دسک چیست؟
در دهه گذشته ، پایتون به عنوان زبان غالب در علم داده و Data Science رشد کرده است. به لطف کتابخانه های قدرتمندی از قبیل NumPy ، Pandas و scikit-learn ، دانشمندان داده کار بسیار ساده تری در دستکاری و مصورسازی داده های خود داشته اند.
-در این زمینه می توانید مطلب استفاده از پایتون در علم داده را نیز مطالعه کنید
با این حال ، هر ساله که میزان داده ها به طور تصاعدی رشد می کند ، دانشمندان در اجرای همه این داده ها در کامپیوترهای خود با مشکل بیشتری مواجه می شوند. کتابخانه های قدرتمندی که معرفی کردیم ، یک مشکل بالقوه برای دانشمندان داده دارند. این کتابخانه ها برای کار با یک هسته طراحی شده اند. یعنی با داشتن چندین هسته پردازنده فقط یکی از این پردازنده ها مشغول به کار است.همچنین تمام داده هایی که ما با کد خود اجرا می کنیم به طور موقت روی RAM سیستم ما قرار می گیرند. در نتیجه ، اگر شروع به کار با مجموعه داده های بسیار بزرگ در سیستم خود کنیم ، به ناچار با مشکلات حافظه روبرو خواهیم شد.
راه حل این مشکلات دسک است و آموزش dask میتواند تا حدودی به شما در برطرف کردن مشکلات ناشی از محدودیت در منابع کمک کند.
دسک با توزیع داده ها در چندین پردازنده و ارائه روش هایی برای مقیاس بندی جریان های داده در Pandas ، Scikit-Learn و Numpy بدون آنکه نیاز به نوشتن کد های بیشتری داشته باشیم پردازش موازی را پشتیبانی می کند . Dask در هسته اصلی خود یک کتابخانه محاسباتی موازی دارد که با توزیع محاسبات بزرگتر و تقسیم آن به محاسبات کوچکتر کار می کند.
بدیهی است که کتابخانه های دیگری مانند PySpark وجود دارد که می تواند کار مشابهی را انجام دهد ، اما سهولت ادغام Dask در کد Python است که آن را بسیار عالی می کند. از آنجایی که زبان پایتون بهترین زبان برای علم داده است اهمیت یادگیری Dask بیش از پیش است. برای اطلاعات بیشتر می توانید این لینک را مطالعه کنید.
پردازش موازی چیست؟
محاسبات کامپیوتری شامل مفاهیم بسیار پیچیده ای است که در یک مقاله نمی توان به طور کامل توضیح داد. ما فقط تلاش می کنیم مفاهیم اساسی را درک کنیم تا نحوه کار دسک را بهتر بشناسیم. به زبان ساده ، پردازش موازی نوعی فرایند محاسباتی است که در آن چندین فرآیند برای پردازش همزمان داده ها استفاده می شود. این روش به ما این امکان را می دهد که کارها را خیلی سریعتر محاسبه کنیم زیرا به جای اینکه یک کار را انجام دهیم ، می توانیم چندین کار را همزمان انجام دهیم. در واقع پردازش موازی در مقابل پردازش سری قرار دارد.
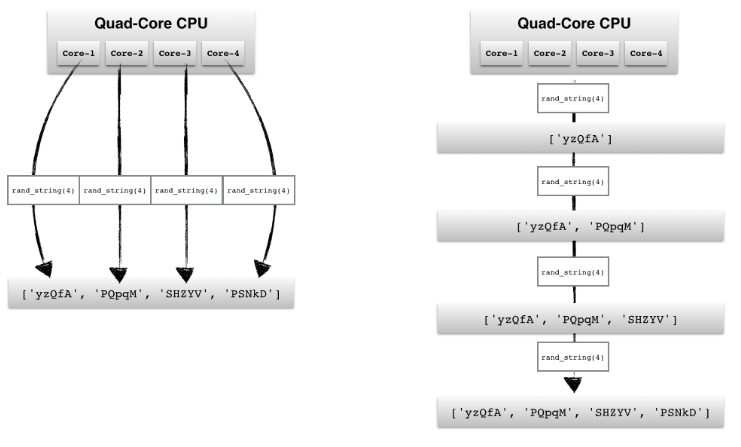
به همین ترتیب محاسبات خوشه ای(cluster computing) به فرایندی گفته می شود که در آن چندین کامپیوتر باهم و به صورت موازی عمل پردازش را انجام می دهند به طوری که همگی این سیستم ها با یکدیگر یک سیستم را تشکلیل بدهند.
محاسبات خوشه ای نوعی از پردازش موازی یا توزیع شده است که متشکل از کامپیوتر های مستقل و بهم پیوسته است که همه این کامپیوتر ها به عنوان یک منبع محاسباتی واحد و یکپارچه عمل می کنند. هر کدام از رایانه ها می تواند یک سیستم تک پردازنده یا چند هسته ای باشد. به هر کامپیوتر در سیستم محاسبات خوشه ای نود یا گره هم می گویند.
در دنیای محاسبات خوشه ای، معماری ها مختلفی برای تقسیم بندی وظایف بین کامپیوترها وجود دارد. برای فهمیدن ساختار معماری خوشه ای باید نگاهی به اجزای دسک بیاندازیم. دسک از سه بخش تشکیل شده است:
۱. یک برنامه ریز متمرکز ، که کارگران(worker) را مدیریت می کند و وظایفی را که باید توسط آنها انجام شود تعیین می کند.
۲. کارگران ، محاسبات را انجام می دهند ، نتایج را حفظ می کنند ، و
نتایج را به یکدیگر منتقل کنید.
۳. یک یا چند کلاینت ، که از طریق آن کاربران دستورات خود را برای اجرای کار ارسال می کنند.
کلاینت درخواست خود را ارسال می کند. برنامه ریز درخواست را دریافت می کند و نحوه انجام کار را تعیین کند و آن را ببین کارگران تقسیم می کند. در اخر کارگران عملیات محاسباتی را انجام می دهند.
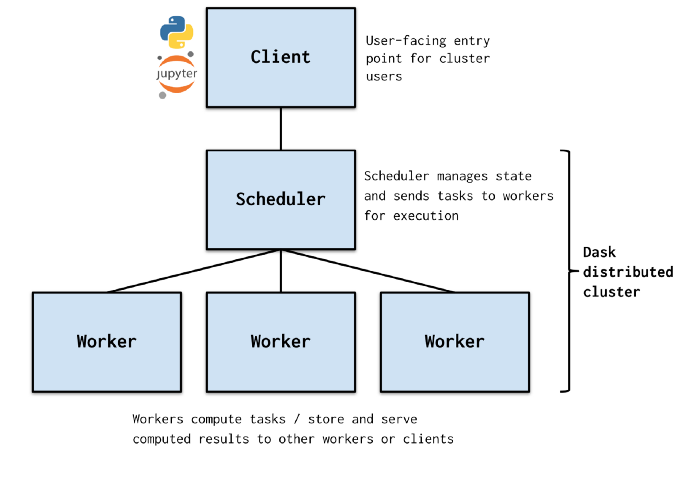
همانطور که مشاهده می کنید دسک محاسبات بزرگ و پیچیده را به بخش های کوچکتری تقسیم می کند. این کار کمک می کند سیستم های با پردازنده ضعیف تر هم بتوانند در عملیات محاسبات شرکت کنند و سرعت اجرای پردازش افزایش یابد.
عملیات پشت دسک بسیار پیچیده است. برای مطالعه بیشتر سایت اصلی آموزش دسک بهترین منبع است. اینجا می توانید مطالب بیشتر را مطالعه کنید.
آموزش dask دسک
دسک در دو سطح انجام می شود:
- سطح بالا: در این سطح دسک ارایه و Datafraim را شبیه سازی می کند. در سطح بالا دسک می تواند جایگزین کتابخانه های Pandas و numpy شود. یعنی تمام عملیات آن ها را به صورت موازی انجام دهد.
- سطح پایین: در این سطح دسک می تواند پردازش موازی را انجام دهد.
همانطور که قبلا گفتیم دسک می تواند به دو صورت اجرا شود. به صورت موزای روی یک سیستم و چند پردازنده یا روی چند سیستم به صورت توزیع شده.
آموزش نصب و راه اندازی dask
برای نصب دسک می توانیم از روش های زیر استفاده کنیم.
می توان دسک را از طریق محیط jupyter notebook یا pip نصب کرد.
|
1 |
conda install dask
|
یا
|
1 |
pip install dask
|
برای آنکه دسک اجرا شود اولین کاری که باید انجام دهیم این است که مشخص کنیم پردازش به صورت محلی(Local) است یا توزییع شده.
|
1
2
3
|
from dask.distributed import LocalCluster, Client
cluster = LocalCluster()
client = Client(cluster)
|
اگر بخواهید دسک به صورت توزیع شده بر روی چند کامیپوتر انجام شود تنظیمات پیچیده می شود. می توانید از طریق این لینک زیر نحوه این تنظیمات را ببینید.
دسک می تواند ارایه ای از ارایه های کوچک numpy ایجاد کند.
|
1
2
3
|
import dask.array as da
x = da.random.random((10000, 10000), chunks=(1000, 1000))
x
|
این کد یک آرایه تصادفی در ابعاد 10000 در 10000 ایجاد می کند. آرگومان chunks به شما امکان می دهد نحوه تجزیه آرایه را تعیین کنید. در این حالت ، می توان آرایه را به 10 قطعه تقسیم کرد ، هر قطعه در ابعاد 1000 در 1000. استفاده از اندازه قطعه مناسب برای بهینه سازی الگوریتم های پیشرفته بسیار مهم خواهد شد. یا اگر فضای رم کمی داشتید با تعیین مناسب پارامتر chunks می توان ارایه ای بیشتر از حجم RAM ایجاد کرد.

اطلاعات بیشتر مربوط به پارامتر chunks را اینجا بخوانید.
به همین ترتیب می توان با Dask DataFrame فرمت داده های pandas خواند یا ایجاد کرد. اگر حجم دیتا فریم ورودی از حجم حافظه اصلی بیشتر باشد یکی از بهترین روش ها استفاده از دسک است.
|
1
2
3
|
from dask import datasets
import dask.dataframe as dd
df = datasets.timeseries()
|
پیشنهاد می کنم حتما منبع اصلی آموزش دسک را در زمینه مطالب مربوط به آرایه و دیتا فریم را مطالعه کنید.
منبع:
نتیجه گیری
این مقاله مقدمه ای بود بر آموزش dask برای اشنایی و کار مقدماتی با بیگ دیتا و پردازش موازی.
در ادامه سعی خواهیم کرد گام به گام مراحل بعدی آموزش dask را نیز برای شما تهیه کنیم.
امیدوارم این مقاله توانسته باشد شما را با مفهوم دسک آشنا کرده باشد. چنانچه در مورد نصب و راه اندازی dask سوالی دارید می توانید در قسمت نظرات با ما مطرح کنید.