روش یولو که مخفف عبارت you only look once می باشد در سال2015 ارائه شده است با استفاده از ترکیب candidate box generation و طبقهبندی بر اساس رگرشن توانست پروسه تشخیص اجسام را در یک مرحله انجام دهد. ساختار این روش منجر به افزایش قابل ملاحظه سرعت در تشخیص اجسام شد به نحوی که با استفاده از آن امکان پردازش تصاویر با سرعت 45 فریم بر ثانیه محقق شد روش یولو3 که در پژوهش حاضر مورد بررسی قرار گرفته است در سال 2018 و با اعمال تغییراتی در راستای بهبود دقت مدلهای یولو1 و یولو 2 ارائه شده است.
سه مرحله اصلی در عموم روشهای تشخیص اجسام به صورت تک مرحلهای وجود دارد که این مراحل را میتوان در تصویر زیر مشاهده نمود. در گام نخست این مدلها تصویر وارد یک ساختار شبکه عصبی CNN میشود (backbone). این ساختار که معمولا یک مدل از پیش آموزش داده شده بر روی دیتاست ImageNet میباشد که وظیفه استخراج ویژگیهای تصویر را دارا میباشد. مدلهای مختلفی که به منظور تسکهای تقسیمبندی استفاده شدهاند میتوانند در انجام این وظیفه به کار گرفته شوند. در الگوریتم ورژن 3 مدل یولو از ساختار darcknet 52 به منظور استخراج ویژگیها استفاده شده است.
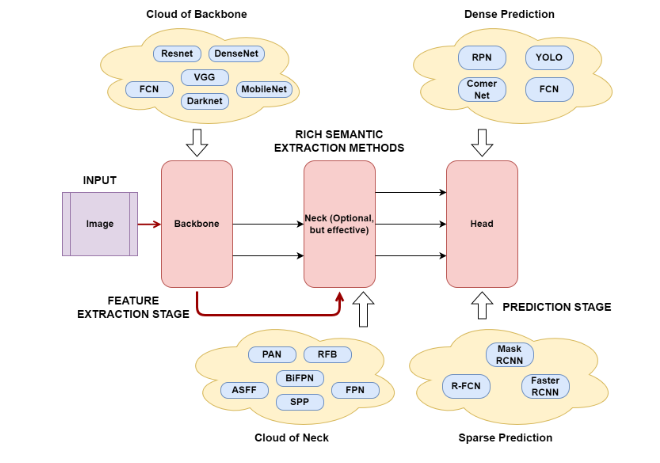
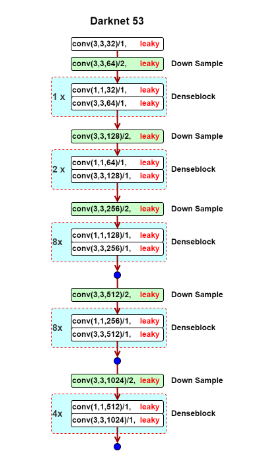
اطلاعات به دست آمده پس از مرحله backbone وارد قسمت neck مدل میشود. وظیفه کلی این قسمت این است که با افزودن فیچرهای به دست آمده از لایههای مختلف مانع از دست رفتن اطلاعات در پروسه انتقال تصویر مابین لایههای bakbone شود
در نهایت با به کار گیری اطلاعات به دست آمده در مرحله پیشین، قسمتhead وظیفه پیشبینی موقعیت مکانی و کلاس مربوط به آبجکتهای موجود در تصویر را دارا میباشد.
ساختار backbone در یولو
همانطور که اشاره شده در مدل یولو3 از ساختار دراک نت52 به منظور استخراج ویژگیهای تصویر استفاده میشود. این شبکه به طور کلی از کنار هم قرار گرفتن تعدادی بلوک با دو ساختار رژیوال و کانولوشن ساخته شده است.
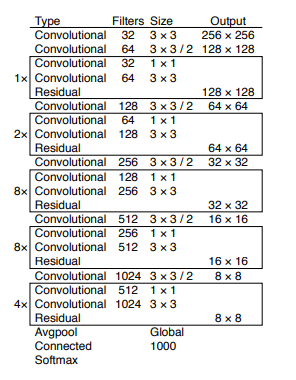
در پروژه فعلی و در قسمت مصور سازی تصویر خروجی، هر مرحله از نمودار شکل 1 به عنوان یک لایه نام گذاری شده است. ابعاد تصاویر خروجی از لایهها به صورت زیر میباشد. مولفه اول هر یک از تنسورهای زیر مشخص کننده بچسایز میباشد، مولفه دوم بیانگر تعداد کانال و دو مولفه انتهایی طول و عرض تصاویر را مشخص میکنند. قابل توجه است که ابعاد مشخص شده برای لایههای مختلف بر حسب تصویر ورودی 416*416 مشخص شدهاند.
فیچرهای استخراج شده در سه سطح از ساختار شبکه در شکل فوق با نقاط آبی مشخص شدهاند از ساختار دارک نت گرفته شده و به مرحله دوم ارسال میشود. ابعاد دیتای خروجی در این مراحل در تصویر مشخص شدهاست.
لازم به ذکر است تابع فعال سازی به کار گرفته شده در تمام کانلوشنهای ساختار دارک نت leaky Relu میباشد. این تابع فعال سازی دو مزیت مهم نسبت به تابع Relu دارا میباشد . نخست اینکه بر خلاف تابع رلو در نقطه صفر مشتق پذیر است و دوم اینکه همانند تابع Relu منجر به صفر شدن تمام مقادیر منفی (که باعث از دست رفتن برخی از نورونها در ساختار شبکه عصبی میشود) نمیگردد.
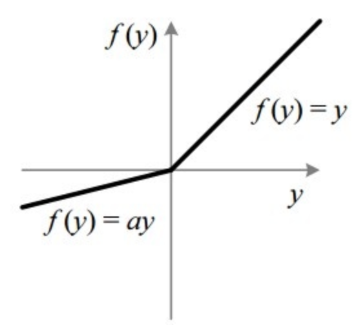
ساختار neck در یولو
همانطور که بیان شد خروجی سه لایه مختلف از ساختار شبکه دارکنت از مرحله نخست وارد ساختار neck میشود. هر کدام از این لایهها متناسب با پروسه یادگیری که طی کردهاند قسمتی از فیچرهای تصویر را توانستهاند استخراج بکنند. ساختار neck با این هدف کلی ایجاد شده است که از به هدر رفتن این اطلاعات جلوگیری کند و با تجمیع اطلاعات به دست آمده از لایههای مختلف به مدل کمک نمایید که پیشبینی صحیحتری از تصاویر داشته باشد.
ساختار head در یولو
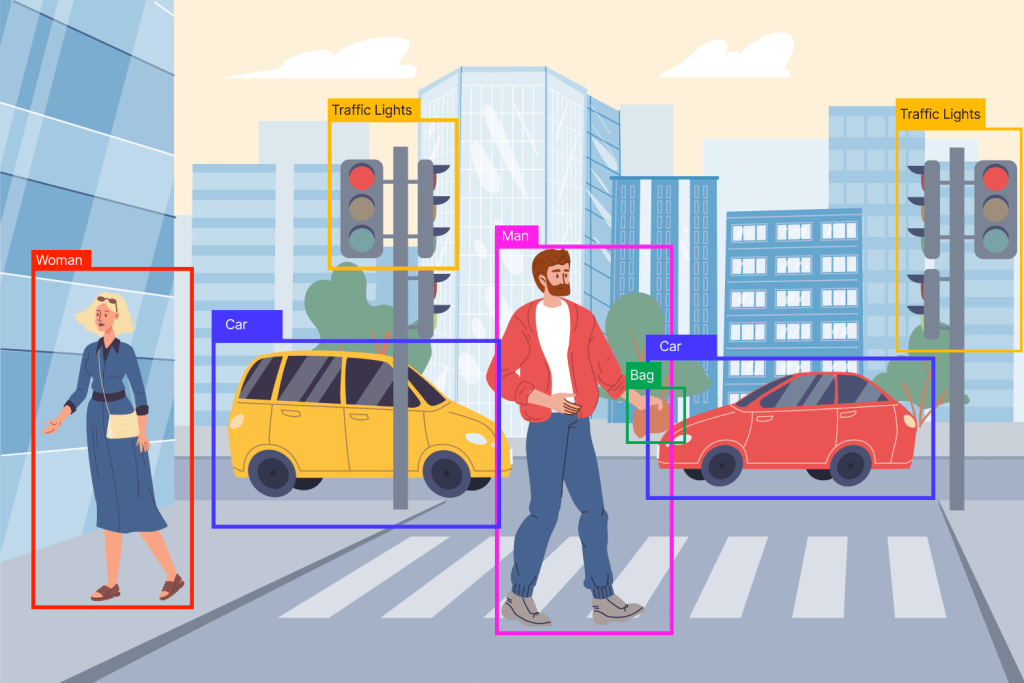
با ورود یک بچ از تصاویر به مدل یولو به صورت (m,416,416,3) این روش میبایست موقعیت و کلاس آبجکتها را مشخص کند. 6 عدد به منظور توصیف هر جسم به کار گرفته میشود.(pc,bx,by,bhh,bw,c) نخستین عدد بیانگر احتمال وجود آبجکت در قسمت مشخصی از تصویر است. در ادامه 4 مولفه بیان کننده مستطیل متناظر با آبجکت میباشند. عدد c نیز میزان تعلق آبجکت را به دسته c مشخص میکند. در هنگام به کارگیری الگوریتم یولو بر روی دیتاست pascal ، 20 دسته مختلف وجود دارد و در نتیجه 20 کلاس مختلف جایگزین این مقدار c خواهند شد.
یولو به منظور توصیف موقعیت اجسام، عکس را به صورت یک شبکه بندی متشکل از مستطیلهای کوچک در نظر میگیرد. مستطیلی که نزدیکتر به موقعیت قرارگیری مرکز جسم باشد وظیفه اصلی پیدا کردن آن جسم را بر عهده دارد. مثلا به ازای ورودی تصویر 416*416 و با در نظر گرفتن stride برابر با 32 برای شبکه، ابعاد فیچر مپ نهایی به صورت 13*13 به دست میآید که متناسب با آن تصویر به صورت 13*13 گرید بندی میشود.
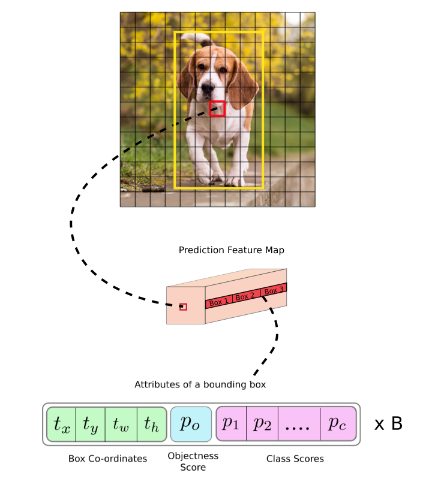
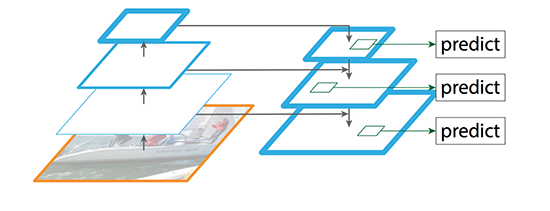
لازم به توجه است یکی از دستاوردهای نسخه سوم یولو نسبت به گزینههای پیشین به کارگیری اسکیلهای متفاوت به منظور تشخیص اجسام با ابعاد متفاوت میباشد. بدین منظور در مدل نهایی سه گریدبندی متفاوت مشابه با شکل زیر برای تصاویر در نظر گرفته میشود و سه خروجی متفاوت از لایه head به دست میآید.

در پیاده سازی الگوریتم یولو توجه به این نکته ضروری است که چنانچه وظیفه کامل پیش بینی طول و عرض تصاویر بر عهده مدل باشد منجر به ناپایداری گردیان در پروسه یادگیری میشود. برای حل این مشکل در این مدل از مستطیلهای از پیش تعیینشده ای به نام انکر باکس استفاده میشود. بر روی هر یک از سه اسکیل مختلف گریدبندی که مورد اشاره قرار گرفت، الگوریتم یولو سه دسته انکر باکس از پیش تعیین شده را به کار میگیرد. به عبارت دیگر میتوان گفت در این مدل در مجموع 9 انکرباکس با سایزهای مختلف این وظیفه را برعهده دارند که اجسام موجود در تصویر را پیدا نمایند. برای پیدا کردن ابعاد مناسب برای این انکرباکسها میتوان از روش k_means بر روی دیتاست استفاده نمود.
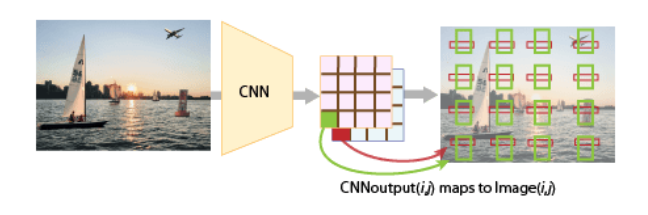
با در نظر گرفتن مفهوم انکر باکس تصویر خروجی مدل یولو به ازای هر یک از سه اسکیل به کار گرفته شده را میتوان به صورت تصویر زیر نمایش داد.
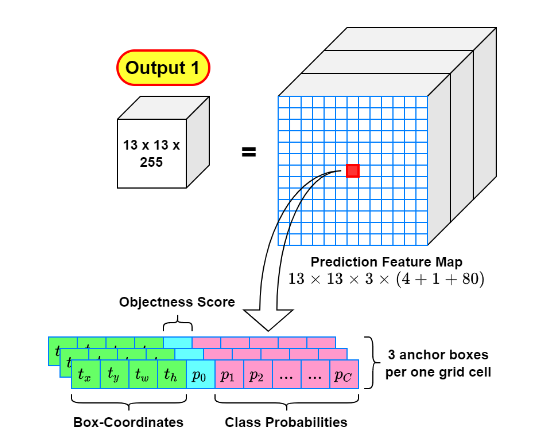
پردازش نتایج خروجی
همانطور که در شکل اخر نشان داده شد هر یک از سه خروجی (هر خروجی معادل با یک سایز گریدبندی میباشد) مدل یولو به صورت یک تنسور چند بعدی به دست میآید. در ادامه لازم است با استفاده از مقادیر موجود در این تنسورها موقعیت قرارگیری آبجکتهای موجود در تصویر را به طور دقیق مشخص نمود.
بدین منظور در گام نخست تمام باکسهای به دست آمده بر حسب مقدار object confidence فیلتر میشوند و باکسهایی که احتمال وقوع آبجکت در آنها از حد معینی کمتر است حذف میشوند.
در ادامه با انجام عملیات non max suppression لازم است باکسهای تشخیص داده شدهای که انطباق زیادی با یکدیگر دارند از نتایج حذف شوند. (به واسطه سلهای مرکزی متفاوت و همچنین انکرباکسهای مختلف احتمالا یک آبجکت چندین بار تشخیص داده میشود)

تابع هزینه
یکی از مهمترین مراحل در طراحی هر ساختار شبکه عصبی تعریف تابع هزینه مناسب جهت بهینهسازی ضرایب شبکه میباشد. پژوهشگران ارائه دهنده الگوریتم یولو تلاش نمودهاند با به کارگیری تابع هزینه رگرشنی متناسب با مساله پیدا نمودن مرز جسم در کنار تابع هزینه مربطو به مساله تقسیمبندی به فرمولی مناسب جهت بهینه سازی ضرایب مدل برسند. بدین تریب برای محاسبه تابع هزینه در این روش لازم است سه تابع هزینه زیر محاسبه شوند :
تابع هزینه confidence : این تابع هزینه وظیقه دارد به مدل کمک کند تا بهتر بتواند تصاویر پس زمینه را از قسمتهای تصویر که در آن آبجکت وجود دارد تشخیص دهد. (رابطه1)
تابع هزینه regression: این تابع هزینه زمانی اعمال میشود که باکس مد نظر دارای ک آبجکت باشد، در این وضعیت خطای موقعیت باکس پیشبینی شده و باکس واقعی توسط این تابع سنجیده میشود.
تابع هزینه classification: این تابع هزینه بر حسب پیشبینی که مدل از دستهبندی مربوط به هر آبجکت ارائه داده است محاسبه میشود. برای اینکار میتوان از تابع هزینه کراس آنتروپی مشابه با رابطه 3 استفاده نمود.
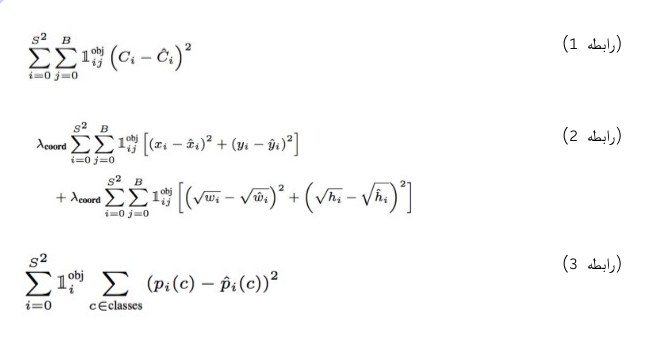
آشنایی با دیتاست
در این پروژه از مجموعه دیتاست پاسکال 2012 و 2007 استفاده شده است. این دیتاست شامل تصاویر مربوط به اجسام مختلف در 20 دسته میباشد. تعداد تصاویر مورد استفاده جهت تست در این دیتاست برابر تصاویر موجود در trainval موجود در این دو دیتاست میباشد که عدد آن برابر با 16551 میباشد.
همچنین درمجموع از 4952 تصویر برای تست نمودن مدل استفاده شده است.(این تصاویر بر اساس دیتای تست پاسکال 2007 انتخاب شده اند.)
شرایط پیادهسازی
مطابق با توضیحات مربوط موجود در دیتاست پاسکال معیار اصلی سنجش عملکرد الگوریتم تشخیص اجسام mAP (یا همان Ap) میباشد که بر حسب مقادیر پریسشن و ریکال به دست میآید. در طول پروسه یادگیری پس از طی شدن هر 4 ایپاک بر روی دیتای ترین، عملکرد مدل با استفاده از دیتای تست مورد ارزیابی قرار میگیرد و در نهایت مدلی که به بیشنه مقدار mAP برسد به عنوان مدل نهایی ذخیره میشود. پروسه یادگیری در 80 ایپاک صورت پذیرفته است و در پروسه یادگیری آن از تکنیک ادغام تصاویر بهره گرفته شده است. (به صورت رندوم به برخی از تصاویر، تصویر رندومی اضافه میشود.)
پیاده سازی مدل با استفاده از فریم ورک pytorch صورت پذیرفته است. در تعریف ساختار الگوریتم یولو3، در قسمت backboneاز مدل دارک نت 52 آموزش داده شده بر روی imagenet استفاده شده است تا پروسه یادگیری سریعتر طی شود. همچنین در پروسه یادگیری از روش SGD به منظور بهینه سازی ضرایب ساختار مدل استفاده شده است. میزان مومنتوم مربوط به این روش برابر با 0.9 در نظر گرفته شده است و learning rate آن با استفاده از روشcosine_lr_scheduler تنظیم میشود. در به کارگیری روش SGD از weight decay برابر با 0.0005 نیز استفاده شده است.
بررسی نتایج
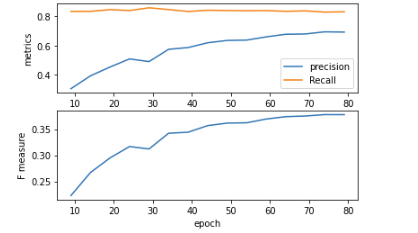
به منظور بررسی صحت عملکرد مدل میبایست دو پارامتر مهم NMS_THRESH و CONF_THRESH در شروع کار تعیین شوند. پارامتر نخست بیان میدارد که چه مقدار iou بین تصویر پیش بینی شده و تصویر لیبل زده شده به عنوان درصد قابل قبول در نظر گرفته شود. در اجرای نهایی این مقدار برابر با 0.45 در نظر گرفته شده است. پارامتر دوم مشخص میکند که درصد مورد اعتماد مدل برای تایید پیش بینی یک لیبل چه میزان است. که این پارامتر برابر با 0.2 در نظر گرفته شده است. انتخاب عدد کوچکتر برای این معیار منجر به رسیدن به map های بالاتری میشود. زیرا در این وضعیت tp بیشتری توسط مدل در تصاویر دیده خواهد شد. با این حال از طرف دیگر کم کردن این عدد منجر به افزایش fp های خروجی نیز میشود که در نتیجه آن معیار precision به شدت کاهش خواهد یافت
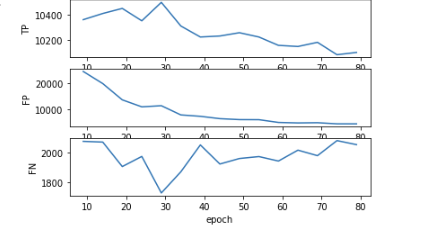
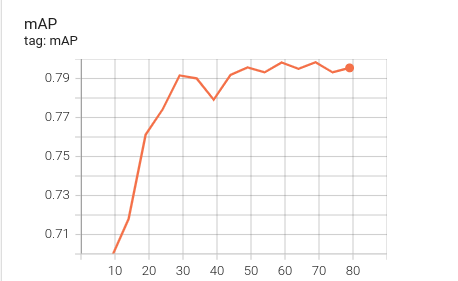
نتایج به دست آمده در شکل بالا نشان میدهد که عملکرد مدل به مرور و بر حسب ایپاکهای طی شده در تشخیص مقادیر مثبت کاذب عملکرد بسیار بهتری را از خود نشان میدهد. هر چند از ایپاک 30 به بعد عملکرد مدل در تشخیص مقادیر مثبت حقیقی روند منفی را شروع میکند، با این حال تغییر این عدد به نسبت مقادیر مربوط به منفی کاذب قابل توجه نیست و همانطور که نمودارهای شکل بعدی مشاهده میشود این موضوع منجر به افزایش قابل توجه مقدار Recall میشود. مقادیر به دست آمده برای map که متریک اصلی مربوط به ارزیابی مدل میباشد نیز موید بهبود قابل توجه عملکرد مدل در 50 ایپاک ابتدایی میباشد. بعد از این بازه روند بهبود این مقدار این شاخص کند شده و تقریبا در ایپاک 70 رویه مثبت آن معکوس میشود. در مجموع مدلی که بهترین عملکرد را از نظر شاخص map دارد به عنوان بهترین مدل سیو میشود.
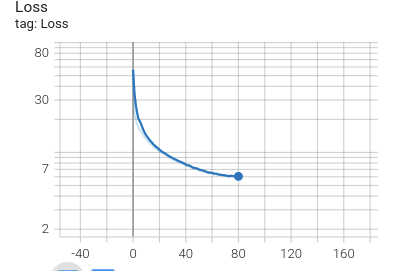
به منظور اطمینان از صحت پروسه طی شده در یادگیری الگوریتم توجه به نمودار تغییرات تابع هزینه میتواند اطلاعات مفیدی را در اختیار ما بگذارد. همانطور که در قسمتهای پیشین به بحث گذاشته شد، تابع هزینه در الگوریتم یولو3 از سه مقدار متفاوت تشکیل میشود. که در نمودار زیر مجموع این سه مقدار بر حسب ایپاک ترسیم شده است. همانطوری که این نمودار ترسیم شده نشان میدهد روش بهینهسازی به کار گرفته شده در حل مساله به خوبی توانسته است تابع هزینه را در پروسه یادگیری مدل به سمت رسیدن به نقطه کمینه هدایت کند.