
امروزه استفاده از یادگیری عمیق در حوزه های مختلف بسیار پیشرفت کرده است. در این پروژه قصد وارد حوزه سلامت و توانبخشی شدیم. هدف از انچام این پروژه طبقه بندی داده های موج نگاری مغز(electroencephalogram) با کمک شبکه عصبی LSTM و الگوریتم XGBoost است.
چالش های موجود در این پروژه کار با داده های موج نگاری و ساخت یک مدل استخراج ویژگی با شبکه LSTM بود. مقاله پایه این پروژه Deep learning for electroencephalogram (EEG) classification tasks: a review است که می توانید از اینجا به آن دسترسی داشته باشید. در ادامه خلاصه ای از بحش های مختلف این پروژه معرفی می شود. این پروژه با زبان پایتون فریم ورک تنسوفلو و در محیط گوگل کولب نوشته شده است.
دیتاست
در این پروژه از مجموعه داده BCI Competition استفاده شده که یک مجموعه داده دارای سیگنال های EEG و لیبل متناظر می باشد. سیگنال های این دیتاست کانال های مغزی 9 سابجکت متفاوت گرفته شده و دارای لیبل های گوناگونی میباشد. در این پروژه کانال های مغزی شماره 7، 9 و 11 انتخاب شده که در بخش Loop Over Objects (A01T-A09T) کد، سیگنال های هر سابجکت در لیست trials کانال مربوطه و لیبل متناظر با هر سیگنال در لیست class کانال مربوطه اضافه شده است. در نهایت سیگنال و کلاس های تمامی کانال های مغز باهم ادغام میشوند.
لیبل های منتخب در این دیتاست شامل کلاس های دست راست، دست چپ، پا و زبان میباشد. داده های A01T-A09T شامل اطلاعات خام 9 سابجکت هستند که این داده ها در ابتدا قابل استفاده نیستند. نحوه پردازش این داده های خام به طورت یک کلاس در تمامی مقالاتی که ازین دیتاست استفاده کرده اند یکسان بوده و معرفی شده که در این پروژه هم از همان کلاس (MotorImageryDataset) استفاده شده. برای کار و دسترسی به این دیتاست می توانید از این لینک گیت هاب استفاده کنید.
پیش پردازش داده ها
پس از دانلود و دریافت داده ها نوبت به پیش پردازش داده ها می رسد. داده ها شامل 6984 نمونه با 1875 ویژگی هستند.ابتدا بررسی شده داده ها تکراری وجود دارد یا خیر. سپس متوازن بودن لیبل ها یا کلاس ها بررسی شد.

برای پردازش نیاز است لیبل ها با مقدادیر عددی جایگزین شوند. که این کار به راحتی قابل انجام است. چون کار دانلود و تبدیل داده های خام به داده های قابل استفاده برای آموزش شبکه عصبی زمانبر بود، داده بدست آمده در انتهای مرحله پیش پردازش ذخیره شد تا در زمان صرفه جویی شود.
استخراج ویژگی
کار با داده هایی کخ صدها یا هزارن ویژگی دارند در حال افزایش است. هر چقدر تعداد این ویژگی ها بیشتر باشد احتمال برازش(Overfit) شدن افزایش می یابد. برای حل این مساله از روش هایی برای کاهش ابعاد یا استخراج ویژگی های مهم استفاده می شود. استخراج ویژگی دارای مزایای متنوعی است مانند:
- بالا بردن دقت
- کاهش احتمال Overfit
- افزایش سرعت آموزش
- بهبود مصور سازی داده ها
- افزایش تفسیر پذیری مدل
هدف استخراج ویژگی کاهش تعداد ویژگیهای یک مجموعه داده با ایجاد ویژگیهای جدید از ویژگیهای موجود (و سپس کنار گذاشتن ویژگیهای اصلی) است. این مجموعه جدید کاهش یافته از ویژگی ها باید قادر باشند بیشتر اطلاعات موجود در مجموعه اصلی ویژگی ها را خلاصه کنند. به این ترتیب می توان یک نسخه خلاصه شده از ویژگی های اصلی از ترکیب مجموعه اصلی ایجاد کرد.
یکی دیگر از تکنیک های رایج برای کاهش تعداد ویژگی ها در یک مجموعه داده، انتخاب ویژگی است. تفاوت بین انتخاب ویژگی و استخراج ویژگی این است که هدف انتخاب ویژگی رتبهبندی اهمیت ویژگیهای موجود در مجموعه داده و کنار گذاشتن ویژگیهای کمتر مهم است (هیچ ویژگی جدیدی ایجاد نمیشود).
AutoEncoders چیست؟
روش های مختلفی برای انتخاب ویژگی وجود دارد. یکی از بهترین روش ها AutoEncoders ها هستند. AutoEncoder یک شبکه عصبی مصنوعی بدون نظارت است که سعی می کند داده ها را با فشرده سازی(Encoder) در ابعاد پایین تر (لایه گلوگاه یا کد) رمزگذاری کند و سپس داده ها را برای بازسازی(Decoder) ورودی اصلی رمزگشایی کند. لایه گلوگاه نمایش فشرده داده های ورودی را نگه می دارد.
تعداد نورون ها با پیشروی در لایه های میانی در قسمت Encoder کمتر می شود. به همین ترتیب با پیش روی در قسمت Decoder تعدادنرون ها افزایش می باید. شکل زیر نمایی از ساختار یک AutoEncoders است.
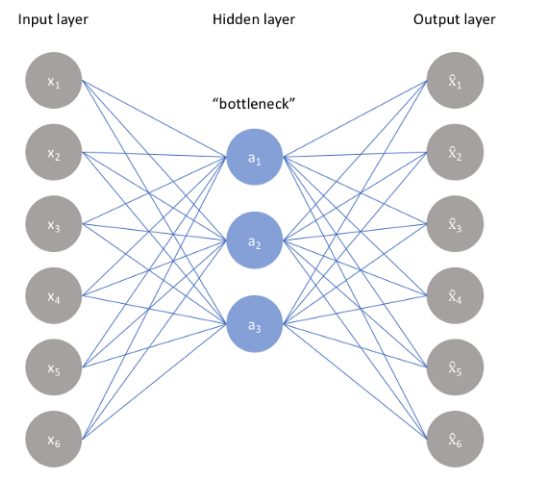
در این پروژه ما از یک مدل LSTM برای ساخت AutoEncoders استفاده کردیم. نتایج خطا یا Loss مدل شبکه عصبی نشان دهنده عملکرد مناسب برای استخراج ویژگی بر روی داده های موج نگاری مغزی است.
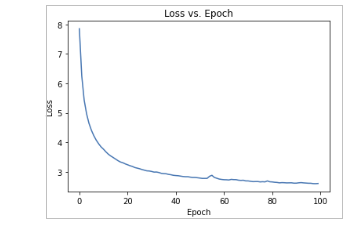
پس انتخاب ویژگی ها مهم نوبت به طبقه بندی داده های مغزی است.
طبقه بندی داده با کمک الگوریتم XGBoost
الکوریتم xgboost در زمینه طبقه بندی داده توانایی بسیار خوبی دارد. به همین دلیل برای طبقه بندی از الگوریتم استفاده کردیم. برای آن که دقت مدل بالاتر رود پارامتر های این الگوریتم (min_child_weight, gamma, subsample, colsample_bytree, max_depth) توسط Gridsearch روی داده های موجود Tune شده و سپس بهینه ترین XGBoost برای طبقه بندی استفاده شد. در نهایت توانسیم بر روی داده های test به دقت 0.81 برسیم.
برای آنکه مطمین شویم طبقه بندی که انتخاب کردیم بهترین نتیحه را دارد الگوریتم های معروف را بر روی داده های نهایی آزمایش کردیم. نتایج را بر روی نمودار میله ای می توانید مشاهده کنید.
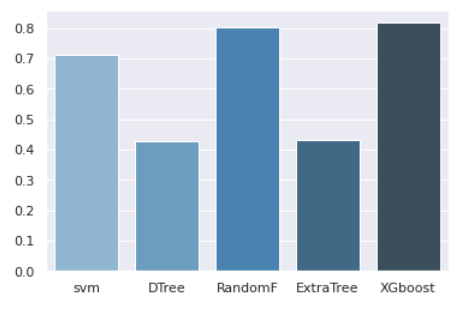
نتایج هم نشان دهنده این است که الگوریتم XGboost بهترین عملکرد را دارد.
نتیجه گیری
امروزه علم داده و یادگیری ماشین در حوزه های مختلفی ورود پیدا کرده است. در این پروژه از یادگیری ماشین برای طبقه بندی داده های توانبخشی استفاده کردیم. ابتدا با استفاده از یک AutoEncoders ویژگی ها مهم داده را استخراج کردیم سپس با کمک الگوریتم XGboost اقدام به طبقه بندی آن ها کردیم. در نهایت توانسیم به دقت 0.81 برسیم که در مقایسه با روش های دیگر عملکرد بهتری دارد.