
مدلهای زبانی بزرگ مثل ChatGPT در سالهای اخیر دنیای تکنولوژی را متحول کردهاند. این مدلها میتوانند متنهای منسجم تولید کنند، به سوالها جواب دهند و حتی کارای پیچیدهتری مثل ترجمه یا خلاصهسازی انجام دهند. حالا اگه بخوام یه مدل زبانی مشابه ChatGPT برای زبان فارسی بسازیم، باید یک سری مراحل مشخص را طی کنیم و به چالشهای خاص زبان فارسی هم توجه کنیم. در این مطلب، میخواهیم به صورت جامع و حرفهای توضیح دهیم که چگونه می توان مشابه این مدل ها را بسازید. این راهنما مناسب افرادی است که با مفاهیم اولیه یادگیری ماشین و NLP آشنا هستند و دنبال چالش های بیشتر در این حوزه هستند.
ساختار و عملکرد مدلهای زبانی بزرگ
مدلهای زبانی بزرگ، نظیر GPT-2 و LLaMA، بر اساس معماری ترانسفورمر طراحی شدهاند که در سال ۲۰۱۷ توسط واسوانی و همکارانش معرفی گردید. این معماری از مکانیزم توجه (Attention Mechanism) بهره میبرد که به مدل امکان میدهد روابط پیچیده و وابستگیهای طولانیمدت میان واژگان در متن را شناسایی و تحلیل کند.
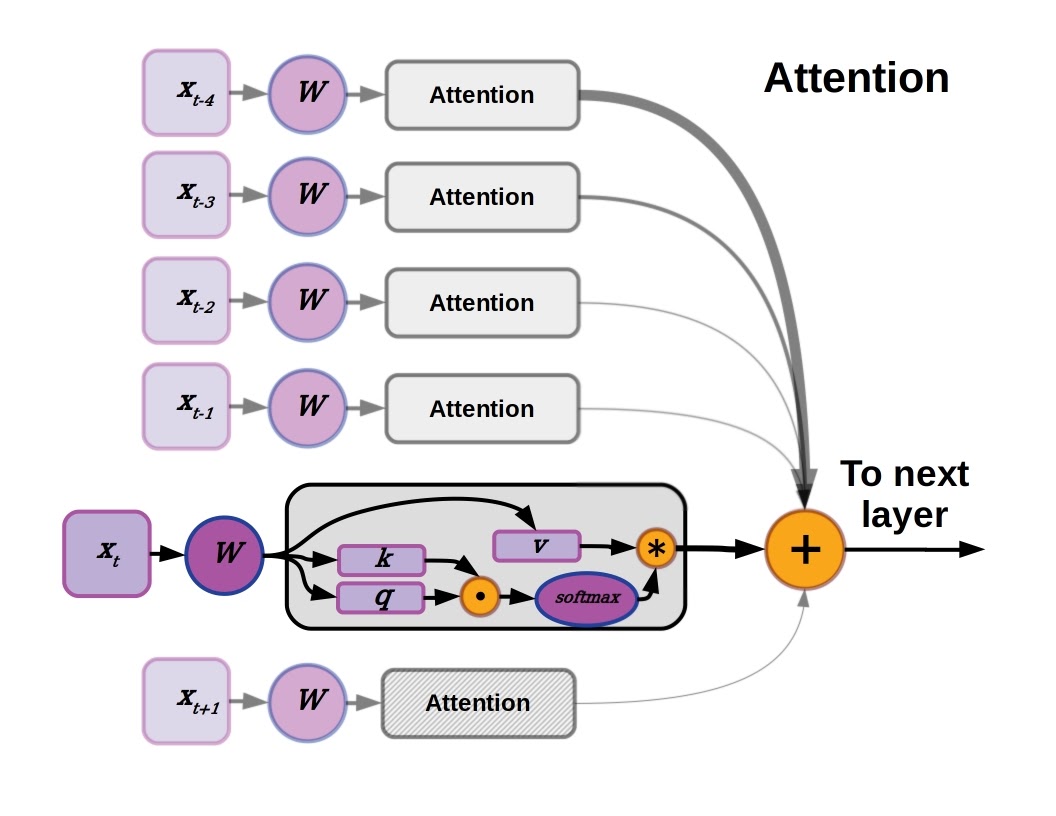
مکانیزم توجه با تخصیص وزنهای متفاوت به بخشهای مختلف متن، اهمیت نسبی هر واژه را در چارچوب کلی تعیین میکند. این ویژگی، ترانسفورمرها را از مدلهای پیشین مانند شبکههای عصبی بازگشتی (RNN) متمایز میسازد که به دلیل پردازش ترتیبی، در مدیریت داده های طولانی دچار مشکل می شدند.
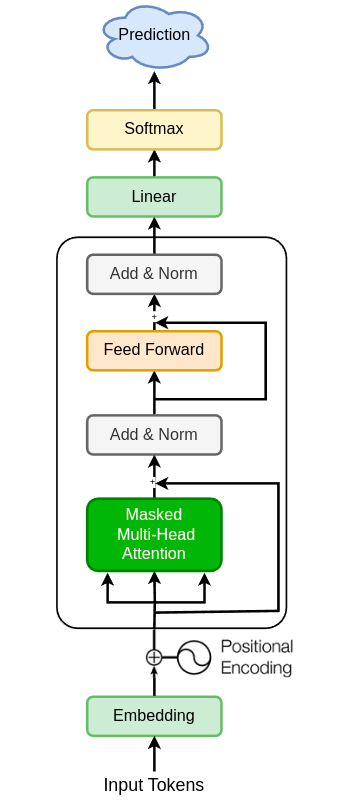
معماری ترانسفورمر شامل دو بخش اصلی است: انکودر (Encoder) و دیکودر (Decoder). انکودر متن ورودی را به یک بردار تبدیل میکند، در حالی که دیکودر این بردار را برای تولید متن خروجی به کار میگیرد. با این حال، در مدلهای زبانی مولد مانند GPT-2 و LLaMA، تنها از بخش دیکودر استفاده میشود. این مدلها به صورت خودبازگشتی (Autoregressive) عمل میکنند و هر واژه جدید را بر اساس واژگان پیشین در دنباله پیشبینی مینمایند. به عنوان مثال، در جملهای مانند “امروز هوا بسیار…”، مدل با تکیه بر الگوهای آموختهشده، واژه بعدی نظیر “گرم” یا “سرد” را پیشبینی میکند.
هر لایه دیکودر در این مدلها از دو مؤلفه کلیدی تشکیل شده است:
- توجه چندسر (Multi-Head Attention): این بخش به مدل اجازه میدهد به صورت موازی به جنبههای مختلف متن توجه کند. در زبان فارسی، که دارای ساختارهای نحوی پیچیده و جهت نوشتاری راست به چپ است، این قابلیت اهمیت ویژهای دارد. برای نمونه، در جمله “کتابی که دیروز خریدم، بسیار جالب بود”، توجه چندسر ارتباط میان “کتابی” و “جالب بود” را بهرغم وجود عبارت میانجی بهدرستی تشخیص میدهد.
- شبکههای عصبی پیشخور (Feed-Forward Neural Networks): این بخش به صورت مستقل روی هر واژه عمل کرده و ویژگیهای عمیقتری را استخراج میکند. لایههای متعدد این مؤلفهها به صورت پشتهای، توانایی مدل را در یادگیری الگوهای زبانی پیچیده افزایش میدهند.
چالشهای زبان فارسی، از جمله جهت نوشتاری، تنوع واژگانی، و وجود کلمات چندمعنایی، نیازمند بهینهسازیهای خاصی در این مدلهاست. کمبود دادههای آموزشی باکیفیت نیز توسعه مدلهای کارآمد را دشوار میسازد، اما با بهرهگیری از تکنیکهایی نظیر تنظیم دقیق (Fine-tuning) مدلهای چندزبانه، میتوان این موانع را تا حدی برطرف کرد.
معرفی مدل GPT-2 و ChatGPT
مدل GPT-2، که در سال ۲۰۱۹ توسط OpenAI معرفی شد، با ۱.۵ میلیارد پارامتر، یکی از پیشگامان مدلهای زبانی بزرگ محسوب میشود. این مدل با استفاده از توجه خودی (Self-Attention) و به صورت خودبازگشتی، متون منسجم و طبیعی تولید میکند. توجه خودی به مدل امکان میدهد تا در هنگام تولید هر واژه، تنها به واژگان پیشین توجه کند و واژه بعدی را بر اساس آنها پیشبینی نماید. GPT-2 با آموزش بر روی دادههای گسترده، قادر به تولید محتواهایی متنوع مانند مقالات علمی یا داستانهای کوتاه است، هرچند در مواردی ممکن است اطلاعات نادرست تولید کند یا در متنهای طولانی انسجام خود را از دست بدهد.
ChatGPT، که بر پایه مدلهای پیشرفتهتر مانند GPT-3 و GPT-4 توسعه یافته، نسخهای بهینهشده برای چت کردن و مکالمه است. این مدل با بهرهگیری از یادگیری تقویتی (Reinforcement Learning) و تنظیم دقیق، پاسخهایی طبیعی و مرتبط با پرسوجوهای کاربران ارائه میدهد. برای مثال، در پاسخ به پرسشی مانند “وضعیت اقتصادی ایران چگونه است؟”، ChatGPT پاسخی منطقی بر اساس الگوهای زبانی آموختهشده تولید میکند، هرچند فاقد اطلاعات بهروز است. برای زبان فارسی، این مدلها نیازمند تنظیم با دادههای بومی هستند تا ساختارهای خاص این زبان را بهخوبی مدیریت کنند.
معرفی مدل LLaMA
LLaMA، که در سال ۲۰۲۳ توسط Meta معرفی شد، یک مدل زبانی متنباز است که برای استفاده توسط محققان و توسعهدهندگان طراحی شده است. این مدل در نسخههایی با پارامترهای ۷ تا ۶۵ میلیارد عرضه شده و به دلیل بهینهسازیهای انجامشده در لایههای توجه و نرمالسازی، کارایی بالایی دارد. برای مثال، نسخه ۱۳ میلیارد پارامتری آن میتواند با مدلهای بزرگتری مانند GPT-3 (با ۱۷۵ میلیارد پارامتر) رقابت کند. این کارایی، LLaMA را به گزینهای مناسب برای کاربردهایی با منابع محاسباتی محدود تبدیل کرده است.
LLaMA نیز از توجه چندسر و شبکههای عصبی پیشخور بهره میبرد و به صورت خودبازگشتی عمل میکند. مزیت برجسته آن، متنباز بودن است که انعطافپذیری بالایی برای تنظیم با زبانهای خاص، از جمله فارسی، فراهم میکند. با آموزش مناسب روی دادههای فارسی، این مدل میتواند جملاتی روان مانند “امروز صبح هوا خنک بود و من پیادهروی کردم” تولید کند.
آمادهسازی دادهها برای زبان فارسی
آمادهسازی دادهها یکی از مهمترین مراحل در توسعه یک مدل زبانی برای زبان فارسی به شمار میرود، زیرا کیفیت و تنوع دادهها مستقیماً بر عملکرد مدل تأثیر میگذارد. برای شروع، لازم است مجموعهای گسترده از متون فارسی جمعآوری شود. این متون میتوانند از منابع مختلفی مانند ویکیپدیای فارسی، وبسایتهای خبری معتبر نظیر ایسنا یا مهر، کتابهای دیجیتال در دسترس، و حتی شبکه های اجتماعی یا مکالمات متنی استخراج شوند. هرچه تنوع موضوعی این دادهها بیشتر باشد، مدل توانایی بهتری در درک و تولید متون متنوع، از جمله متون علمی، ادبی، و روزمره، پیدا خواهد کرد. برای دستیابی به یک مدل کارآمد، توصیه میشود حجم دادهها به چندین صد گیگابایت متن خام برسد، زیرا مدلهای زبانی بزرگ به مجموعههای عظیمی از دادهها نیاز دارند تا الگوهای زبانی را بهخوبی فرا بگیرند.
پس از جمعآوری دادهها، مرحله پیشپردازش آغاز میشود که شامل پاکسازی و آمادهسازی متون برای استفاده در مدل است. در این مرحله، باید عناصری مانند پیوندهای اینترنتی، کاراکترهای غیرضروری (مانند شکلکها در متون غیررسمی)، و علائم نگارشی اضافی از متن حذف شوند تا دادهها یکدست و قابلاستفاده شوند. همچنین، نرمالسازی متن ضروری است؛ به این معنا که املای واژگان باید یکسانسازی شود (برای مثال، “میروم” و “میروم” به یک شکل استاندارد تبدیل شوند) و خطاهای املایی احتمالی اصلاح گردند. در زبان فارسی، که دارای ویژگیهای خاصی مانند جهت نوشتاری راست به چپ و تنوع در نگارش است، این فرآیند اهمیت بیشتری پیدا میکند. سپس، متن باید به واحدهای کوچکتر، یعنی توکنها، تقسیم شود. برای این منظور، ابزارهایی مانند Hazm یا Parsivar که با قواعد زبان فارسی سازگار هستند، میتوانند به کار گرفته شوند تا توکنسازی به شکلی دقیق و متناسب با ساختار زبان انجام شود. در برخی موارد، حذف واژگان توقف (مانند “و”، “به”، یا “در”) نیز ممکن است مدنظر قرار گیرد، اما در مدلهای زبانی بزرگ، معمولاً این واژگان حفظ میشوند، زیرا مدل قادر است روابط میان آنها را به صورت خودکار یاد بگیرد.
در نهایت، دادهها باید به یک دیتاست ساختاریافته تبدیل شوند که برای آموزش مدل مناسب باشد. این دیتاست به صورت دنبالههای متنی تنظیم میشود، به طوری که متن ورودی و متن هدف (که معمولاً با یک شیفت به جلو تعریف میشود) مشخص باشند. برای مثال، اگر متن ورودی “سلام چطوری” باشد، متن هدف میتواند “چطوری هستی” تعریف شود. این دادهها میتوانند در قالب فایلهای متنی ساده (مانند فرمت .txt) یا ساختارهای پیشرفتهتر مانند JSON ذخیره شوند تا در مراحل بعدی به راحتی قابل بارگذاری و استفاده باشند.
استفاده از مدلهای از پیش آموزشدیده
ایجاد یک مدل زبانی از ابتدا فرآیندی زمانبر و پرهزینه است که نیازمند منابع محاسباتی قابلتوجه، مانند واحدهای پردازش گرافیکی پیشرفته، و مدتزمان طولانی برای آموزش است. به همین دلیل، استفاده از مدلهای از پیش آموزشدیده و تنظیم دقیق آنها برای زبان فارسی رویکردی کارآمدتر محسوب میشود. در این روش، ابتدا باید یک مدل پایه مناسب انتخاب شود. مدلهای چندزبانه مانند mBERT یا XLM-RoBERTa گزینههای مناسبی هستند، زیرا این مدلها در طیف گستردهای از زبانها، از جمله فارسی، آموزش دیدهاند و میتوانند به عنوان نقطه شروع استفاده شوند. با این حال، مدلهای اختصاصیتر مانند ParsBERT یا PersianBERT که به طور خاص برای زبان فارسی طراحی شدهاند، به دلیل تطابق بیشتر با ویژگیهای این زبان، انتخابهای بهتری به شمار میروند.
مرحله بعدی، تنظیم دقیق این مدلها با استفاده از دادههای فارسی است. در این فرآیند، دیتاست آمادهشده به مدل ارائه میشود تا الگوهای خاص زبان فارسی، مانند ساختارهای نحوی و واژگان بومی، را فرا بگیرد. برای انجام این کار، باید پارامترهایی مانند نرخ یادگیری (Learning Rate) در سطح پایینی (مانند 2e-5) تنظیم شوند تا از تغییرات بیش از حد در دانش پیشین مدل جلوگیری شود. همچنین، تعداد دورههای آموزش (Epoch) معمولاً بین ۳ تا ۵ دوره محدود میشود و از تکنیکهایی مانند Dropout برای کاهش خطر بیشبرازش استفاده میگردد. این تنظیمات به مدل کمک میکنند تا ضمن حفظ دانش عمومی خود، به نیازهای خاص زبان فارسی نیز پاسخ دهد.
پس از اتمام آموزش، ارزیابی عملکرد مدل ضروری است. برای این منظور، میتوان از معیارهایی مانند Perplexity استفاده کرد که نشاندهنده میزان موفقیت مدل در پیشبینی دنبالههای متنی است. همچنین، معیار BLEU Score میتواند برای سنجش کیفیت متن تولیدی به کار گرفته شود. در نهایت، مدل باید با دادههای جدیدی که در فرآیند آموزش استفاده نشدهاند، آزمایش شود تا توانایی تعمیمپذیری آن مورد تأیید قرار گیرد.
پیادهسازی با پایتون
اکنون به بخش عملی پیادهسازی با زبان پایتون میرسیم که نمونهای از کدنویسی برای ساخت یک مدل زبانی ساده ارائه میدهد. این پیادهسازی با استفاده از کتابخانه Hugging Face Transformers انجام میشود که ابزارهای قدرتمندی برای کار با مدلهای زبانی فراهم میکند.
ابتدا باید کتابخانههای مورد نیاز نصب شوند.
pip install transformers datasets torch
در مرحله بعد، دادهها بارگذاری میشوند. فرض کنید یک فایل متنی فارسی به نام text.txt دارید که حاوی دادههای خام است. این دادهها با استفاده از کتابخانه datasets به صورت زیر بارگذاری میشوند:
from datasets import load_dataset
dataset = load_dataset('text', data_files={'train': 'farsi_text.txt'})
سپس، فرآیند توکنسازی انجام میشود تا دادهها برای مدل قابلاستفاده شوند. در اینجا از یک توکنساز آماده استفاده میکنیم که با مدل انتخابشده سازگار است:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('bert-base-multilingual-cased')
def tokenize_function(examples):
return tokenizer(examples['text'], padding='max_length', truncation=True, max_length=128)
tokenized_dataset = dataset.map(tokenize_function, batched=True)
پس از توکنسازی، مدل و تنظیمات آموزشی بارگذاری میشوند. در این مثال، از یک مدل مولد استفاده میکنیم و پارامترهای آموزشی را تنظیم میکنیم:
from transformers import AutoModelForCausalLM, Trainer, TrainingArguments
model = AutoModelForCausalLM.from_pretrained('bert-base-multilingual-cased')
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=8,
save_steps=10_000,
save_total_limit=2,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset['train'],
)
مرحله آموزش با اجرای دستور زیر آغاز میشود:
trainer.train()
پس از اتمام آموزش، میتوان از مدل برای تولید متن استفاده کرد. به عنوان مثال، با ارائه یک متن ورودی، مدل خروجی تولید میکند:
input_text = "سلام، چطوری؟" input_ids = tokenizer.encode(input_text, return_tensors='pt') output = model.generate(input_ids, max_length=50) print(tokenizer.decode(output[0], skip_special_tokens=True))
این کد یک نمونه ساده است که میتواند به عنوان پایهای برای پروژههای پیچیدهتر مورد استفاده قرار گیرد. برای دستیابی به عملکرد بهتر، استفاده از مدلهای بزرگتر مانند GPT-2 یا LLaMA و دیتاستهای گستردهتر توصیه میشود.
نتیجهگیری
توسعه یک مدل زبانی مشابه ChatGPT برای زبان فارسی نیازمند برنامهریزی دقیق و استفاده از ابزارهای مناسب است. در این راهنما، از آمادهسازی دادهها و تنظیم مدلهای از پیش آموزشدیده تا پیادهسازی عملی با پایتون، مراحل کلیدی به صورت جامع تشریح شد. این فرآیند، با وجود چالشهای خاص زبان فارسی، با بهرهگیری از منابع موجود و تکنیکهای پیشرفته کاملاً قابلاجرا است. امیدواریم این محتوا راهگشای شما در این مسیر باشد و بتوانید پروژهای موفق در این حوزه پیادهسازی کنید.