
یادگیری تقویتی (Reinforcement Learning) یکی از شاخههای پیشرفته یادگیری ماشین است که با الهام از رفتار انسان در یادگیری از تجربه، به طراحی عاملهای هوشمندی میپردازد که میتوانند در محیطهای پیچیده تصمیمگیری کنند. این فناوری، که در حوزههایی مانند رباتیک، بازیهای ویدیویی، و بهینهسازی سیستمهای صنعتی کاربرد دارد، به عاملها اجازه میدهد با آزمونوخطا و دریافت پاداش یا جریمه، بهترین استراتژیها را یاد بگیرند. این مقاله آموزشی با هدف ارائه یک راهنمای جامع برای پیادهسازی یادگیری تقویتی با استفاده از پایتون و کتابخانه OpenAI Gym نگارش شده است.
یادگیری تقویتی چیست و چگونه کار میکند؟
یادگیری تقویتی فرآیندی است که در آن یک عامل (Agent) با تعامل با محیط (Environment) و دریافت بازخورد بهصورت پاداش (Reward) یا جریمه، یاد میگیرد که چه اقداماتی (Actions) منجر به بهترین نتایج میشوند. برخلاف یادگیری با نظارت که به دادههای برچسبدار نیاز دارد، یادگیری تقویتی بر اساس تجربه عمل میکند. بر اساس مقالهای در “Journal of Machine Learning Research” (مارس ۲۰۲۵)، یادگیری تقویتی از سه مؤلفه اصلی تشکیل شده است: حالت (State)، که موقعیت فعلی عامل در محیط است؛ اقدام، که انتخابی است که عامل انجام میدهد؛ و پاداش، که بازخورد محیط به اقدام عامل است. هدف عامل، به حداکثر رساندن پاداش تجمعی در طول زمان است.
برای مثال، فرض کنید میخواهید یک ربات را آموزش دهید تا در یک ماز (maze) مسیر خروج را پیدا کند. ربات در هر قدم یک اقدام (مثل حرکت به چپ یا راست) انجام میدهد، و اگر به دیوار برخورد کند، پاداش منفی (جریمه) و اگر به خروج برسد، پاداش مثبت دریافت میکند. با تکرار این فرآیند، ربات یاد میگیرد که کدام مسیرها به خروج منتهی میشوند. این مفهوم در یادگیری تقویتی با الگوریتمهایی مانند Q-Learning یا سیاست گرادیانتی پیادهسازی میشود.
چرا OpenAI Gym برای یادگیری تقویتی مناسب است؟
OpenAI Gym یک کتابخانه متنباز پایتون است که محیطهای شبیهسازیشدهای برای آزمایش و توسعه الگوریتمهای یادگیری تقویتی فراهم میکند. این کتابخانه شامل محیطهای متنوعی مانند بازیهای کلاسیک و شبیهسازیهای رباتیک است که به محققان و توسعهدهندگان اجازه میدهد الگوریتمهای خود را بدون نیاز به طراحی محیط از صفر آزمایش کنند. وبسایت “OpenAI” در فوریه ۲۰۲۵ گزارش داد که Gym به دلیل سادگی و انعطافپذیری، به استانداردی در آموزش یادگیری تقویتی تبدیل شده است.
برای شروع، باید Gym را نصب کنیم. کد زیر نصب کتابخانه را نشان میدهد:
!pip install gym
پیادهسازی یک عامل هوشمند با Q-Learning
برای آموزش عملی، الگوریتم Q-Learning را در محیط CartPole از OpenAI Gym پیادهسازی میکنیم. CartPole یک محیط ساده است که در آن، یک میله روی یک گاری قرار دارد و هدف، متعادل نگه داشتن میله با حرکت گاری به چپ یا راست است. این محیط برای یادگیری مفاهیم پایه یادگیری تقویتی ایدهآل است.
مرحله 1: آمادهسازی محیط
ابتدا محیط CartPole را راهاندازی میکنیم:
import gym
import numpy as np
env = gym.make('CartPole-v1')
state_space = env.observation_space.shape[0]
action_space = env.action_space.n
محیط CartPole چهار متغیر حالت (موقعیت گاری، سرعت گاری، زاویه میله، سرعت زاویهای) و دو اقدام (حرکت به چپ یا راست) دارد.
مرحله 2: گسستهسازی فضای حالت
چون فضای حالت CartPole پیوسته است، باید آن را گسسته کنیم تا Q-Learning قابلاجرا باشد. این کار با تقسیم هر متغیر حالت به بازههای کوچک انجام میشود:
def discretize_state(state, bins): discretized = [] for i in range(len(state)): discretized.append(np.digitize(state[i], bins[i]) - 1) return tuple(discretized) bins = [ موقعیت گاری# ,np.linspace(-4.8, 4.8, 20) سرعت گاری# ,np.linspace(-4, 4, 20) زاویه میله# ,np.linspace(-0.418, 0.418, 20) سرعت زاویه ای #, np.linspace(-4, 4, 20) ]
مرحله 3: پیادهسازی Q-Learning
فرمول Q یک الگوریتم بدون مدل است که از یک جدول برای ذخیره ارزش هر جفت حالت-اقدام استفاده میکند. فرمول محاسبه و بروز رسانی Q بصورت زیر است.
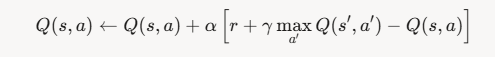
که در آن، 𝛼 نرخ یادگیری، 𝛾 ضریب تخفیف، 𝑟 پاداش، و 𝑠 ′ حالت بعدی است. کد زیر الگوریتم Q-Learning را پیادهسازی میکند
alpha = 0.1 gamma = 0.99 epsilon = 0.1 episodes = 10000 q_table = np.zeros([20] * state_space + [action_space]) for episode in range(episodes): state = env.reset() state = discretize_state(state, bins) done = False while not done: if np.random.random() < epsilon: ()action = env.action_space.sample else: action = np.argmax(q_table[state]) next_state, reward, done, _ = env.step(action) next_state = discretize_state(next_state, bins) q_value = q_table[state][action] next_max = np.max(q_table[next_state]) q_table[state][action] += alpha * (reward + gamma * next_max - q_value) state = next_state env.close()
مرحله 4: آزمایش عامل
پس از آموزش، میتوانیم عامل را آزمایش کنیم:
env = gym.make('CartPole-v1', render_mode='human')
state = env.reset()
state = discretize_state(state, bins)
done = False
while not done:
action = np.argmax(q_table[state])
state, reward, done, _ = env.step(action)
state = discretize_state(state, bins)
env.render()
env.close()
این کد عامل را اجرا میکند و شما میتوانید ببینید که گاری میله را برای مدت طولانی متعادل نگه میدارد.
چالشهای پیادهسازی یادگیری تقویتی
پیادهسازی یادگیری تقویتی، بهویژه در محیطهای پیچیدهتر، چالشهایی دارد. یکی از مشکلات اصلی، مقیاسپذیری است. در محیط CartPole، فضای حالت محدود بود، اما در محیطهای واقعی (مثل رباتیک)، تعداد حالات میتواند بسیار زیاد باشد. استفاده از شبکههای عصبی عمیق (Deep Reinforcement Learning) میتواند این مشکل را حل کند، اما به منابع محاسباتی قوی نیاز دارد. مقالهای در “IEEE Transactions on Neural Networks” (آوریل ۲۰۲۵) گزارش داد که آموزش مدلهای عمیق یادگیری تقویتی ممکن است روزها طول بکشد.
چالش دیگر، تنظیم پارامترهاست. انتخاب مقادیر مناسب برای α\alpha، γ\gamma و ϵ\epsilon تأثیر زیادی بر عملکرد مدل دارد. برای مثال، اگر ϵ\epsilon بیشازحد بالا باشد، عامل بیشازحد تصادفی عمل میکند و یادگیری کند میشود. تیمهای حرفهای در انجام پروژه ماشین لرنینگ میتوانند با بهینهسازی این پارامترها، فرآیند آموزش را تسریع کنند.
کاربردهای یادگیری تقویتی در دنیای واقعی
یادگیری تقویتی در حوزههای متنوعی کاربرد دارد. در بازیهای ویدیویی، الگوریتمهایی مانند DQN (Deep Q-Network) برای آموزش عاملهایی استفاده میشوند که میتوانند بازیهایی مانند شطرنج یا Go را در سطح حرفهای بازی کنند. برای مثال، یک تیم توسعهدهنده میخواهد عاملی بسازد که در یک بازی مسابقهای مسیر بهینه را پیدا کند. یادگیری تقویتی میتواند با آزمایش مسیرهای مختلف، بهترین استراتژی را یاد بگیرد.
در رباتیک، یادگیری تقویتی برای آموزش رباتها به انجام وظایف پیچیده، مانند برداشتن اشیا یا حرکت در محیطهای ناشناخته، استفاده میشود. فرض کنید یک ربات باید در یک انبار بستهها را جابهجا کند. عامل با دریافت پاداش برای تحویل سریع و جریمه برای برخورد با موانع، مسیر بهینه را یاد میگیرد.
در بهینهسازی سیستمها، یادگیری تقویتی برای مدیریت منابع کاربرد دارد. برای مثال، یک سیستم مدیریت انرژی میتواند با یادگیری تقویتی، زمانبندی پمپهای آب را بهینه کند تا مصرف انرژی کاهش یابد. توسعه چنین سیستمهایی نیازمند تخصص است و همکاری با تیمهای حرفهای در انجام پروژه هوش مصنوعی میتواند نتایج را بهبود بخشد.
نتیجهگیری
یادگیری تقویتی، با توانایی خلق عاملهای هوشمند، یکی از قدرتمندترین ابزارهای هوش مصنوعی است. از بازیهای ساده مانند CartPole تا کاربردهای پیچیده در رباتیک و بهینهسازی، این فناوری راهحلهایی نوآورانه ارائه میدهد. پیادهسازی عملی با OpenAI Gym و Q-Learning، که در این مقاله آموزش داده شد، نشان میدهد که این فناوری برای توسعهدهندگان در دسترس است. مثالهایی مانند حرکت ربات در صفحه شطرنجی یا پیشنهاد محصولات، کاربردهای آن را برای همه روشن میکند. بااینحال، چالشهایی مانند مقیاسپذیری و تنظیم پارامترها نیازمند تخصص است.