
پیش پردازش داده ها اولین (و احتمالاً مهمترین) قدم به سمت ساخت یک مدل یادگیری ماشین است.
اگر داده های شما پاکسازی و پردازش نشده باد ، مدل شما کار نمی کند.
وارد کردن کتابخانه (import)
در ابتدا با وارد کردن کتابخانه هایی که برای پردازش داده های خود نیاردارید ، شروع می کنیم. کتابخانه ابزاری است که می توانید از آن استفاده کنید. شما ورودی را به كتابخانه می دهید ، كتابخانه كار خود را انجام می دهد و خروجی موردنیاز شما را به شما می دهد. تعداد زیادی كتابخانه وجود دارد ،اما وقتی که با پایتون کار می کنید سه کتابخانه محبوب Numpy ، Matplotlib و Pandas هستند. Numpy کتابخانه ای است که برای عملیات ریاضی به آن نیاز دارید. Matplotlib (به طور دقیق Matplotlib.pyplot) کتابخانه ای است برای ساخت نمودار ، Pandas بهترین ابزار موجود برای وارد کردن و مدیریت داده ها است. Pandas و Numpy برای پردازش داده ها ضروری هستند.
وارد کردن این کتابخانه ها با نام مستعار (میانبر) کمک میکند تا در ادامه بتوانید در وقت خود صرفه جویی کنید. این روش بسیار ساده است و شما می توانید آن را به صورت ذیل انجام دهید:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
اکنون می توانید دادههای خود را با روش زیر وارد کنید
dataset = pd.read_csv(‘my_data.csv’)
تصویر زیر چند سطر اول از مجموعه داده است که برای این آموزش در نظر گرفته شده است:
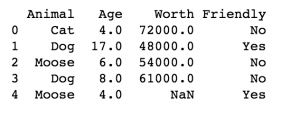
این روش را با Strategy های دیگر امتحان کنید! ممکن است متوجه شوید که برای پروژه خود پر کردن مقادیر مفقود شده با روش میانه (median) یا مد (mode) منطقیتر باشد. تصمیماتی مانند اینها کوچک به نظر می رسد ، اما در واقع اهمیت زیادی دارند.
فقط به دلیل اینکه چیزی محبوب است ، لزوماً آن را به انتخاب صحیحی تبدیل نمی کند. میانگین نقاط داده شما لزوما بهترین انتخاب برای مدل شما نیست.
اگر داده های categorical ای داشته باشید چه می کنید؟
شما دقیقاً نمی توانید از معنی گربه ، سگ و گوزن استفاده کنید. چه می توانیم بکنیم؟ ما می توانیم مقادیر categorical را به صورت اعداد رمزگذاری کنیم! کلاس Label Encoder را از sklearn.preprocessing بگیرید.
از ستونی شروع کنید که می خواهید داده ها را رمزگذاری کنید و از label encoder استفاده کنید. سپس آن را بر روی داده هایاعمال کنید.
from sklearn.preprocessing import LabelEncoder
labelencoder_X = LabelEncoder()
X[:, 0] = labelencoder_X.fit_transform(X[:, 0])
(به خاطر بیاورید که اعداد موجود در براکت ها چگونه کار می کنند؟ “:” بدان معنی است که می خواهیم با تمام سطرها کار کنیم و 0 بدان معنی است که می خواهیم ستون اول را بگیریم.)
بااینکار متغیرهای دسته اول ستون خود را با شماره جایگزین کنید. به عنوان مثال ، به جای گوزن “0” ، به جای “سگ” “2” به جای “گربه” ، “3 را خواهید داشت
ایراد این کار چیست؟
این سیستم برچسب زدن حاکی از ارزش سلسله مراتبی به داده هایی است که می تواند مدل شما را تحت تأثیر قرار دهد. 3 مقدار بالاتر از 0 دارد ، اما گربه (لزوماً) از گوزن بزرگ نیست.
ما باید متغیرهای ساختگی ایجاد کنیم!
ما می توانیم یک ستون برای گربه، یک ستون برای گوزن و غیره ایجاد کنیم. سپس ستون ه ا را با 1 و 0 پر خواهیم کرد (مثلاً ۱ یعنی بله و ۰ یعنی نه).مثلا برای ستون گربه خانه ردیفی که مربوط به گربه بود را ۱ گذاشته و باقی خانه های ستون را صفر میگذاریم.
برای این کار از OneHotEncoder استفاده میکنیم
from sklearn.preprocessing import OneHotEncoder
onehotencoder = OneHotEncoder(categorical_features = [0])
X = onehotencoder.fit_transform(X).toarray()
می توانیم از رمزگذاری (Label Encoder) برای ستون y استفاده کنیم.اگر متغیرهای categorical مانند “yes” و “No” داشته باشیم .
labelencoder_y = LabelEncoder()
y = labelencoder_y.fit_transform(y)
تقسیم دادهها به ۲ قسمت برای آموزش و آزمون (Train test split)
در این مرحله ، می توانید داده های خود را در مجموعه های آموزش و آزمون تقسیم کنید. همیشه داده های خود را در مجموعه های آموزش و آزمون قرار دهید و هرگز از داده های آزمون خود برای آموزش استفاده نکنید
در حال حاضر ما ماشینی داریم که باید چیزی را یاد بگیرد. بوسیله داده ها آن را آموزش داده و ببیند چقدر می تواند آنچه را که در داده های جداگانه آموخته است درک کند. حفظ کردن مجموعه آموزش همان یادگیری نیست! هرچه مدل شما در مورد مجموعه آموزشها بهتر بیاموزد ، در پیش بینی نتایج برای مجموعه آرمون ، بهتر خواهد بود.
در ابتدا train_test_split را وارد می کنیم
from sklearn.model_selection import train_test_split
حالا میتوانیم گروههای آموزش و آزمون خود را بسازیم
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
انجام یک تقسیم 80/20 از داده های شما بسیار معمول است ، که 80٪ از داده های شما به آموزش و 20٪ به آزمون اختصاص می یابد. . شما می توانید آن را به هر اندازهای تقسیم کنید به هر حال لازم است. شما نیازی به تنظیم random_state ندارید ، اما این کار را انجام دادم تا نتیجهای یکسان تولید شود.
مقیاس سازی ویژگیها (feature scalin)
مقیاس سازی ویژگی چیست؟ چرا ما به آن احتیاج داریم؟
به داده های ما نگاه کنید. ما یک ستون با سنین حیوانات از 4 تا 17 سال داریم و ارزش حیواناتی نیز داریم که از 48000 تا 83000 دلار متغیر است. ستون ارزش نه تنها از اعدادبزرگتری نسبت به ستون سن تشکیل شده است ، بلکه متغیرها دامنه بسیار وسیع تری از داده ها را نیز پوشش می دهند. این بدان معناست که فاصله اقلیدسی در ستون ارزش نسبت به ستون ۳ بسیار زیاد خواهد شد.
روش های بسیاری برای انجام مقیاس سازی ویژگی وجود دارد. همه آنها بدان معنی است که ما همه ویژگی های خود را در همان مقیاس قرار می دهیم تا هیچ یک بر دیگری مسلط نشود.
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
برای داده های آزمون نیاز به fit نیست، مستقیم روی دادهها اعمال میکنیم. (چون با داده آموزش fit شده)
X_test = sc_X.transform(X_test)
sc_y = StandardScaler()
y_train = sc_y.fit_transform(y_train)
اگر یک متغیر وابسته مانند 0 و 1 دارید ، دیگر نیازی به اعمال مقیاس سازی ویژگی ها ندارید. این یک مسأله طبقه بندی با مقدار وابسته categorical است. اما اگر طیف گسترده ای از ویژگی ها را دارید ،باید از مقیاس سازی استفاده نمایید.