
تحلیل احساسات چیست؟
تجزیه و تحلیل احساسات تکنیکی است که احساسات اصلی را در قطعه ای از متن تشخیص می دهد.
این یک فرآیند طبقه بندی متن به صورت مثبت ، منفی یا خنثی است. از تکنیک های یادگیری ماشین برای بررسی یک متن استفاده می شود و احساسات موجود در پشت آن تعیین می شود. تحلیل احساسات جزیی از فرآیند پردازش متن است، که ما در این مقاله سعی در توضیح تحلیل احساسات با پایتون داریم.
تحلیل احساسات چه کاربردی دارد؟
تجزیه و تحلیل احساسات برای بررسی نظر مشتری برای مشاغل مختلف ضروری است.
فرض کنید: شرکت شما به تازگی محصول جدیدی را منتشر کرده است که در کانال های مختلفی تبلیغ می شود.
به منظور سنجش نظر مشتری به این محصول ، می توان تجزیه و تحلیل احساسات را با پایتون انجام داد.
این کار توسط زبانهای مختلفی قابل انجام است ولی متداول ترین زبانی که در علم داده به این منظور استفاده می شود زبان python است .در مقاله کاربرد پایتون در علم داده به تفصیل به بررسی این زبان پرداخته ایم
مشتریان معمولاً در مورد محصولات در شبکه های اجتماعی و انجمن بازخورد مشتری صحبت می کنند. این داده ها را می توان برای سنجش نظر کلی مشتری جمع آوری و تحلیل کرد.
در مراحل بعدی ، روند داده ها نیز قابل بررسی است. به عنوان مثال ، مشتریان یک گروه سنی خاص و جمعیت خاص مکانی ممکن است نسبت به کالاهای خاص پاسخ مثبت تری نسبت به دیگران داشته باشند.
بر اساس اطلاعات جمع آوری شده ، شرکت ها می توانند محصول خود را به صورت متفاوت موقعیت یابی کنند یا مخاطبان هدف خود را تغییر دهند.
در این مطلب قصد داریم با یک مثال عملی تجزیه و تحلیل احساسات کاربران را با python به شما آموزش دهم. برای انجام تجزیه و تحلیل از فایل Reviews.csv از مجموعه داده Kaggle’s Amazon Fine Food Reviews استفاده خواهیم کرد.
مرحله اول: خواندن داده ها
import pandas as pd
df = pd.read_csv('Reviews.csv')
df.head()
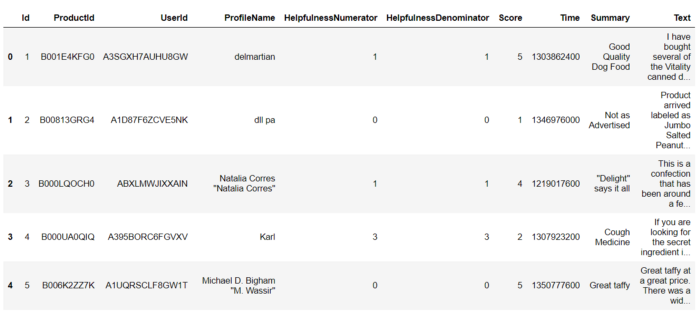
همانطور که می بینید dataframe حاوی برخی از اطلاعات مربوط به محصول ، کاربر و نظر است.
داده هایی که ما بیشتر برای این تحلیل استفاده خواهیم کرد “خلاصه” ، “متن” و “امتیاز” است.
- متن(Text) – این متغیر شامل اطلاعات کامل بررسی محصول است.
- خلاصه(Summary) – این خلاصه ای از کل بررسی است.
- امتیاز(Score) – امتیاز محصول ارائه شده توسط مشتری.
مرحله دوم: تجزیه و تحلیل داده ها
اکنون ، نگاهی به متغیر “Score” خواهیم انداخت تا ببینیم اکثر امتیازهای مشتریان مثبت هستند یا منفی.
برای این کار ابتدا باید کتابخانه Plotly را نصب کنید.
import matplotlib.pyplot as plt
import seaborn as sns
color = sns.color_palette()
%matplotlib inline
import plotly.offline as py
py.init_notebook_mode(connected=True)
import plotly.graph_objs as go
import plotly.tools as tls
import plotly.express as px
# Product Scores
fig = px.histogram(df, x="Score")
fig.update_traces(marker_color="turquoise",marker_line_color='rgb(8,48,107)',
marker_line_width=1.5)
fig.update_layout(title_text='Product Score')
fig.show()
خروجی به این صورت خواهد بود.
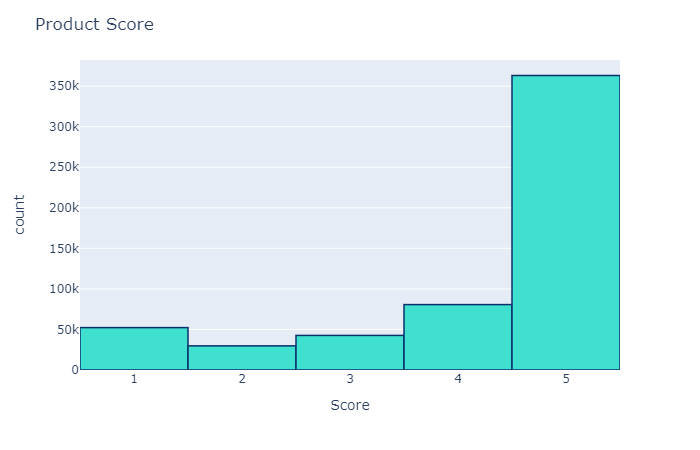
از این نمودار می توان به این نتیجه رسید که بیشتر امتیاز های کاربران مثبت بوده است. اکنون ، می توانیم ابر کلمات(wordclouds) ایجاد کنیم تا بیشترین کلمات مورد استفاده در بررسی ها را مشاهده کنیم.
import nltk
from nltk.corpus import stopwords
# Create stopword list:
stopwords = set(STOPWORDS)
stopwords.update(["br", "href"])
textt = " ".join(review for review in df.Text)
wordcloud = WordCloud(stopwords=stopwords).generate(textt)
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.savefig('wordcloud11.png')
plt.show()
خروجی به صورت زیر خواهد بود.

برخی از کلمات معروف که می توان در اینجا مشاهده کرد شامل “طعم” ، “محصول” ، “عشق” و “آمازون” است. این کلمات عمدتا مثبت هستند ، همچنین نشان می دهد که بیشتر بررسی ها در مجموعه داده، احساس مثبت را بیان می کنند.
مرحله سوم: طبقه بندی نظر ها
در این مرحله از تحلیل احساسات با پایتون ، ما نظر ها را به دو دسته “مثبت” و “منفی” طبقه بندی می کنیم.
نظر های مثبت به عنوان 1+ و نظر های منفی به 1- طبقه بندی می شوند.
ما همه نظرات با امتیاز(Score) بزرگتر از ۳ را به عنوان نظر مثبت یا 1+ در نظر می گیریم.
همچنین همه نظرات با “امتیاز” کمتر از ۳ را به عنوان 1- طبقه بندی می شوند. نظرات با امیتاز برابر ۳ رد می شود ، زیرا خنثی هستند. مدل ما فقط بررسی های مثبت و منفی را طبقه بندی می کند.
df = df[df['Score'] != 3] df['sentiment'] = df['Score'].apply(lambda rating : +1 if rating > 3 else -1)
با نگاهی به قسمت بالای فریم داده ، می توان ستونی جدید به نام «sentiment» مشاهده کرد.
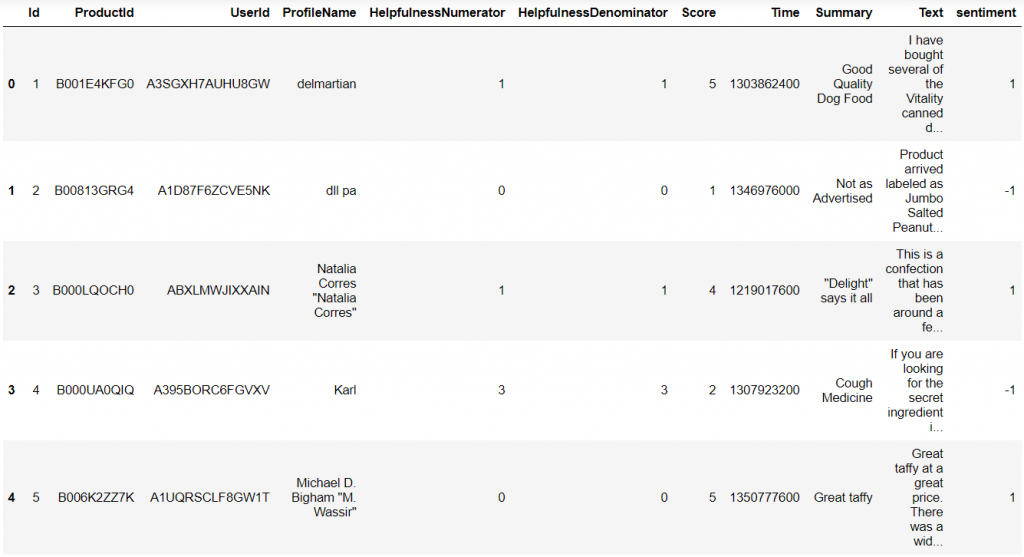
مرحله چهارم: تجزیه و تحلیل بیشتر
حالا که نظرات کاربران را به دو دسته مثبت و منفی طبقه بندی کردیم برای هر دسته ابرکلمات(wordclouds) درست می کنیم. ابتدا دو فریم داده ایجاد می کنیم. یکی برای مثبت ها و دیگری برای منفی ها.
positive = df[df['sentiment'] == 1] negative = df[df['sentiment'] == -1]
ابرکلمات مثبت
stopwords = set(STOPWORDS)
stopwords.update(["br", "href","good","great"])
## good and great removed because they were included in negative sentiment
pos = " ".join(review for review in positive.Summary)
wordcloud2 = WordCloud(stopwords=stopwords).generate(pos)
plt.imshow(wordcloud2, interpolation='bilinear')
plt.axis("off")
plt.show()

ابرکلمات منفی
neg = " ".join(review for review in negative.Summary)
wordcloud3 = WordCloud(stopwords=stopwords).generate(neg)
plt.imshow(wordcloud3, interpolation='bilinear')
plt.axis("off")
plt.savefig('wordcloud33.png')
plt.show()

همانطور که د بالا مشاهده شد ، کلمات ابرمثبت پر از کلمات مثبت مانند “عشق” ، “بهترین” و “خوشمزه” بود.
ابر کلمه احساسات منفی پر از کلمات منفی بود.
کلمات “خوب” و “عالی” علی رغم مثبت بودن در ابر احساسات منفی ظاهر شدند. این احتمالاً به این دلیل است که از آنها در یک زمینه منفی ، مانند “خوب نیست” استفاده شده است.
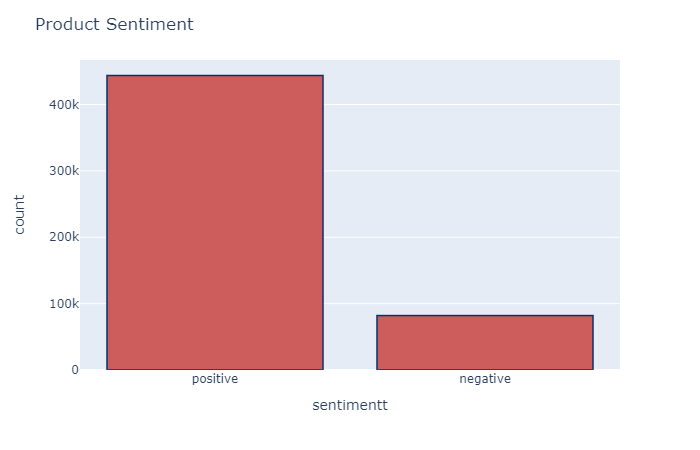
در آخر ، می توانیم نگاهی به توزیع نظر ها از نظر احساسات در مجموعه داده داشته باشیم:
df['sentimentt'] = df['sentiment'].replace({-1 : 'negative'})
df['sentimentt'] = df['sentimentt'].replace({1 : 'positive'})
fig = px.histogram(df, x="sentimentt")
fig.update_traces(marker_color="indianred",marker_line_color='rgb(8,48,107)',
marker_line_width=1.5)
fig.update_layout(title_text='Product Sentiment')
fig.show()
مرحله پنجم: ساخت مدل
سرانجام ، ما می توانیم مدل تجزیه و تحلیل احساسات را با python بسازیم.
این مدل نظر ها را به عنوان ورودی می پذیرد. سپس پیش بینی می کند یک نظر مثبت است یا منفی.
این یک مدل طبقه بندی است. برای ادامه کار باید چند مرحله را انجام دهیم.
تمیز کردن داده ها
ما برای ارائه پیش بینی ها از داده های خلاصه استفاده خواهیم کرد. ابتدا باید تمام علائم نگارشی را از داده ها حذف کنیم.
def remove_punctuation(text):
final = "".join(u for u in text if u not in ("?", ".", ";", ":", "!",'"'))
return final
df['Text'] = df['Text'].apply(remove_punctuation)
df = df.dropna(subset=['Summary'])
df['Summary'] = df['Summary'].apply(remove_punctuation)
تقسیم دیتافریم
چارچوب داده جدید فقط باید دو ستون داشته باشد: “Summary” (داده های متن بررسی) و “sentiment” (متغیر هدف).
dfNew = df[['Summary','sentiment']] dfNew.head()
دیتافریم جدید به صورت زیر خواهد بود
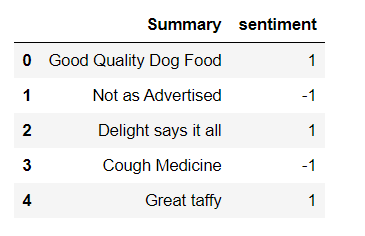
اکنون ما فریم داده را به مجموعه های آموزش و آزمایش تقسیم می کنیم. 80٪ از داده ها برای آموزش و 20٪ برای آزمایش استفاده می شود.
index = df.index df['random_number'] = np.random.randn(len(index)) train = df[df['random_number'] <= 0.8] test = df[df['random_number'] > 0.8]
ساخت bag of words
در فرآیند تجزیه و تحلیل احساسات موجود در متن با استفاده از کتابخانه Scikit-learn در پایتون فرمت ذخیره کلمات تغییر را تغییر می دهیم. در واقع کلمات به صورت یک ماتریس ذخیره می شوند. چون الگوریتم مدلسازیlogistic regression توانایی درک کلمات به صورت عادی را ندارد.
from sklearn.feature_extraction.text import CountVectorizer vectorizer = CountVectorizer(token_pattern=r'\b\w+\b') train_matrix = vectorizer.fit_transform(train['Summary']) test_matrix = vectorizer.transform(test['Summary'])
وارد کردن الگوریتم و تقسیم کردن داده ها.
from sklearn.linear_model import LogisticRegression lr = LogisticRegression() X_train = train_matrix X_test = test_matrix y_train = train['sentiment'] y_test = test['sentiment']
ساخت مدل
lr.fit(X_train,y_train)
پیش بینی داده ها
predictions = lr.predict(X_test)
با موفقیت مدل ساخته و پیش بینی انجام شد.
گام ششم: تست مدل
در این مرحله دقت مدل طراحی شده را تست می کنیم.
from sklearn.metrics import confusion_matrix,classification_report new = np.asarray(y_test) confusion_matrix(predictions,y_test)
ماتریس درهم ریختگی مدل به صورت زیر است.

print(classification_report(predictions,y_test))
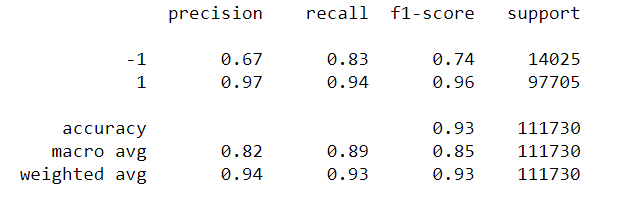
دقت کلی مدل در داده های آزمون حدود 93٪ است ، که با توجه به اینکه ما پیش پردازش زیادی انجام نداده ایم ، بسیار خوب است.
از مواردی که تحلیل احساسات با پایتون کاربرد دارد تحلیل فیدبک های مشتریان در شبکه های اجتماعی و اعمال تغییرات متناسب در کسبد و کارها و ا پیش بینی نظرات و قطبیت موجود در جامعه و مسایل کلان و پیش بینی انتخابات و نظرسنجی ها می باشد.
امیدوارم از آموزش تحلیل احساسات در پایتون استفاده کرده باشید.