پیاده سازی تخصصی مقالات و پروژه های ماشین لرنینگ و ai یکی از خدمات تخصصی ماست که با استفاده از جدیدترین الگوریتمهای یادگیری ماشین انجام میشود. تیم ما متشکل از متخصصین علم داده با تجربه با بهرهگیری از دانش تخصصی در زمینههایی مانند یادگیری عمیق (Deep Learning)، شبکههای عصبی، و تحلیل دادهها، پروژههایی با کیفیت بالا ارائه میدهد. چنانچه نیاز به پیادهسازی مدلهای هوش مصنوعی پیشرفته برای تحلیل داده، پیشبینی، پردازش تصویر، متن یا سایر کاربردها دارید،تیم ما با سابقه بیش از ۶ سال کار تخصصی در پیاده سازی و انجام پروژه های مختلف در خدمت شماست. ارتباط مستقیم با متخصصین دیتاساینس ما در تمام مراحل، وجه تمایز کار مجموعه ماست.
برای مشاوره با شماره زیر تماس بگیرید
09125497399
برای تماس با کارشناسان کلیک کنید

انجام و پیاده سازی پروژه پردازش تصویر
پردازش تصویر (Image Processing) یکی از شاخههای کلیدی و رو به رشد در علوم کامپیوتر و هوش مصنوعی است که با استفاده از زبان برنامهنویسی پایتون به ابزاری قدرتمند برای حل مسائل پیچیده تبدیل شده است. این حوزه از بهبود کیفیت تصاویر ساده گرفته تا تشخیص اشیا، تقسیمبندی تصاویر، و تحلیل احساسات در چهرهها، کاربردهای گستردهای در زندگی مدرن پیدا کرده است. در این مقاله جامع، قصد داریم از مفاهیم اولیه پردازش تصویر با پایتون شروع کنیم و به تدریج به انواع اصلی آن، الگوریتمهای معروف، دیتاستهای کلیدی، کتابخانههای پیشرفته مثل TensorFlow و PyTorch، و نوآوریهای روز در سال ۲۰۲۵ را بررسی کنیم. هدف این است که خوانندگان با یک دید عمیق و کامل از این حوزه آشنا شوند و بتوانند پروژههای خود را با پایتون پیادهسازی کنند.
۱. پردازش تصویر چیست و چرا پایتون بهترین ابزار برای این کار است؟

پردازش تصویر به مجموعه تکنیکهایی اشاره دارد که برای تغییر، تحلیل یا استخراج اطلاعات از تصاویر دیجیتال به کار میروند. این فرآیند میتواند شامل وظایف سادهای مثل تنظیم روشنایی و حذف نویز های یک عکس ، یا کارهای پیچیدهتری مثل شناسایی اشیای خاص در یک تصویر، بازسازی یک تصویر ، یا حتی تشخیص حالات احساسی از چهره انسانها باشد. تاریخچه این علم به دهه ۱۹۶۰ برمیگردد، زمانی که محققان با استفاده از کامپیوترهای ابتدایی، الگوریتمهایی برای فیلتر کردن تصاویر یا تشخیص لبهها توسعه دادند. اما با ظهور یادگیری عمیق و شبکههای عصبی کانولوشنی (Convolutional Neural Networks یا CNN)، پردازش تصویر به سطح جدیدی از دقت و پیچیدگی رسیده است که امروزه در حوزههایی مثل پزشکی، خودروسازی، امنیت، و سرگرمی نقش مهمی ایفا میکند.
پایتون به دلایل متعددی به انتخاب اول توسعهدهندگان و محققان در این حوزه تبدیل شده است. این زبان برنامهنویسی به خاطر سادگی و خواناییاش، یادگیری و استفاده از آن را برای افراد مبتدی و حرفهای آسان کرده است. علاوه بر این، اکوسیستم غنی پایتون، شامل کتابخانههایی مثل NumPy برای محاسبات عددی، Matplotlib و Seaborn برای مصور سازی دادهها و OpenCV برای پردازش تصاویر پایه، پایتون را به یک ابزار همهکاره تبدیل کرده است. طبق گزارشهای منتشرشده در Towards Data Science، پایتون در سال ۲۰۲۵ همچنان پراستفادهترین زبان برای پروژههای هوش مصنوعی و پردازش تصویر است، بهویژه به دلیل وجود فریم ورک های پیشرفته مثل TensorFlow و PyTorch که امکان پیادهسازی مدلهای یادگیری عمیق را با چند خط کد فراهم میکنند. برای مثال، با استفاده از OpenCV میتوان یک تصویر را بارگذاری کرد، آن را خاکستری کرد کرد، یا فیلترهای مختلف را روی تصویر اعمال کرد. این عملیات ساده، نقطه شروع بسیاری از پروژههای پیچیدهتر است که در ادامه به آنها خواهیم پرداخت
۲. انواع اصلی پردازش تصویر
پردازش تصویر با پایتون شامل چندین زیر شاخه اصلی است که هر کدام تکنیکها، الگوریتمها و کاربردهای خاص خود را دارند. در این بخش، این انواع را با توضیحات جامع و معرفی الگوریتمهای معروف بررسی میکنیم تا درک کاملی از هر کدام به دست بیاید..
۲.۱. طبقهبندی تصاویر (Image Classification)
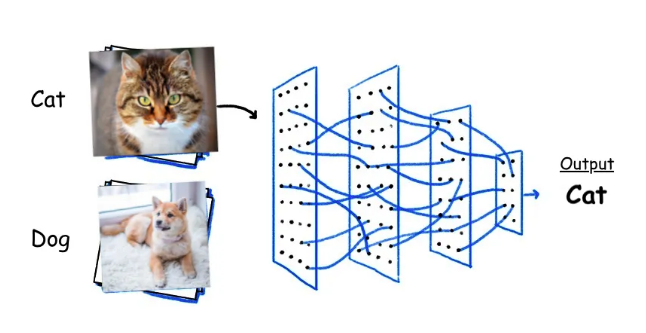
طبقهبندی تصاویر فرآیندی است که در آن به هر تصویر یک برچسب یا دستهبندی اختصاص داده میشود. به عنوان مثال، هدف ممکن است تشخیص این باشد که یک تصویر حاوی یک گربه است یا یک سگ، یا اینکه یک عکس پزشکی نشاندهنده یک بیماری خاص است یا خیر. این کار با استفاده از مدلهای یادگیری ماشین و بهویژه یادگیری عمیق انجام میشود که در سالهای اخیر به لطف شبکههای عصبی کانولوشنی، پیشرفت چشمگیری داشته است. در این روش، تصویر به عنوان ورودی به یک مدل داده میشود و مدل پس از تحلیل ویژگیهای بصری، یک برچسب خروجی تولید میکند. این فرآیند در حوزههایی مثل تشخیص پزشکی (شناسایی سرطان پوست)، امنیت (تشخیص چهره)، و تجارت الکترونیک (دستهبندی محصولات) کاربرد گستردهای دارد.
الگوریتم VGG
یکی از معروفترین الگوریتمها در این زمینه، VGG (Visual Geometry Group) است که در سال ۲۰۱۴ توسط دانشگاه آکسفورد معرفی شد. این مدل از لایههای عمیق کانولوشنی تشکیل شده که به ترتیب فیلترهای کوچک (مثل ۳×۳) را روی تصویر اعمال میکنند تا ویژگیهای سطح پایین (مثل لبهها) و سطح بالا (مثل شکلها و الگوها) را استخراج کنند. نسخههای VGG16 و VGG19 به دلیل دقت بالایشان در دیتاست ImageNet بسیار محبوب شدند، اما به دلیل تعداد زیاد پارامترها، مصرف محاسباتی بالایی دارند.
الگوریتم ResNet
الگوریتم دیگری که باید به آن اشاره کرد، ResNet (Residual Network) است که در سال ۲۰۱۵ توسط مایکروسافت توسعه یافت. ResNet با معرفی “اتصالات باقیمانده” (Residual Connections)، مشکل محو شدن گرادیان در شبکههای عمیق را حل کرد. این اتصالات به مدل اجازه میدهند که به جای یادگیری مستقیم ویژگیها، تفاوتها یا باقیماندهها را یاد بگیرند، که باعث میشود حتی شبکههای بسیار عمیق (مثل ResNet50 یا ResNet152) هم به خوبی آموزش ببینند.
در نهایت، EfficientNet که در سال ۲۰۱۹ توسط گوگل معرفی شد، با بهینهسازی همزمان عمق، عرض و رزولوشن شبکه، تعادل بینظیری بین دقت و کارایی ایجاد کرده است. این مدلها همگی در TensorFlow و PyTorch به صورت از پیش آموزشدیده در دسترساند و با چند خط کد میتوان آنها را برای پروژههای مختلف استفاده کرد.
۲.۲. تشخیص اشیا (Object Detection)
تشخیص اشیا یک گام پیشرفتهتر از طبقهبندی تصاویر است. در این روش، نه تنها نوع شیء مشخص میشود، بلکه مکان آن در تصویر هم با استفاده از جعبههای مرزی (Bounding Boxes) تعیین میشود. این فرآیند برای کاربردهایی مثل سیستمهای امنیتی (تشخیص افراد یا اشیا در دوربینهای مداربسته)، رانندگی خودکار (شناسایی عابران پیاده و خودروها)، و حتی رباتیک (درک محیط) ضروری است. برخلاف طبقهبندی که فقط یک برچسب به کل تصویر میدهد، تشخیص اشیا باید چندین شیء را در یک تصویر شناسایی کند و برای هر کدام مکان و نوع را مشخص کند.
الگوریتم YOLO
یکی از الگوریتمهای برجسته در این حوزه، YOLO (You Only Look Once) است که اولین بار در سال ۲۰۱۶ توسط جوزف ردمن معرفی شد. YOLO به خاطر سرعت بالایش شناخته میشود، زیرا برخلاف روشهای قبلی که تصویر را چندین بار اسکن میکردند، این الگوریتم کل تصویر را در یک گذر (Single Pass) پردازش میکند. YOLO تصویر را به یک شبکه تقسیم میکند و برای هر سلول پیشبینی میکند که آیا شیئی وجود دارد یا خیر، و اگر بله، چه نوع شیئی است و کجاست. نسخههای جدیدتر مثل YOLOv8 و YOLOv10 که در سال ۲۰۲۵ منتشر شدهاند، با بهبودهایی در دقت و بهینهسازی برای پردازش بلادرنگ (Real-time Processing)، در کاربردهایی مثل نظارت ویدئویی و خودروهای خودران پیشتاز شدهاند.
الگوریتم دیگر، Faster R-CNN است که در سال ۲۰۱۵ توسط مایکروسافت توسعه یافت. این مدل از یک شبکه پیشنهاد منطقه (Region Proposal Network یا RPN) استفاده میکند تا ابتدا مناطقی که احتمالاً حاوی اشیا هستند را پیدا کند و سپس آنها را طبقهبندی کند. Faster R-CNN دقت بسیار بالایی دارد، اما سرعتش نسبت به YOLO کمتر است و بیشتر برای کاربردهایی مناسب است که دقت اولویت دارد تا سرعت.
در نهایت، SSD (Single Shot MultiBox Detector) یک الگوریتم سبکتر و سریعتر است که تعادل خوبی بین دقت و کارایی برقرار میکند و در PyTorch و TensorFlow به راحتی قابل پیادهسازی است.
۲.۳. تقسیمبندی تصاویر (Image Segmentation)
تقسیمبندی تصاویر یا سگمنتیشن به معنای جدا کردن بخشهای مختلف یک تصویر است تا هر پیکسل به یک دستهبندی خاص اختصاص پیدا کند. این فرآیند میتواند به دو صورت انجام شود: سگمنتیشن معنایی (Semantic Segmentation) که همه پیکسلهای متعلق به یک کلاس (مثل “انسان” یا “ماشین”) را مشخص میکند، و سگمنتیشن نمونهای (Instance Segmentation) که اشیای مجزا از یک کلاس را تفکیک میکند (مثلاً دو ماشین جداگانه).
کاربردهای Image Segmentation
این تکنیک در حوزههایی مثل پزشکی (تشخیص تومور در تصاویر MRI)، رباتیک (درک محیط)، و ویرایش تصاویر (جدا کردن پسزمینه) کاربرد دارد.
الگوریتم های Image Segmentation
یکی از الگوریتمهای معروف در این زمینه، U-Net است که در سال ۲۰۱۵ برای تصاویر پزشکی معرفی شد. U-Net به خاطر ساختار U شکلش شناخته میشود که شامل یک مسیر انقباضی (Contracting Path) برای استخراج ویژگیها و یک مسیر انبساطی (Expanding Path) برای بازسازی تصویر است. این مدل به دلیل تواناییاش در کار با دیتاستهای کوچک و دقت بالایش در سگمنتیشن پیکسل به پیکسل، در پروژههای پزشکی بسیار محبوب است.
الگوریتم دیگر، Mask R-CNN است که در سال ۲۰۱۷ توسط فیسبوک توسعه یافت. این مدل نسخه پیشرفتهتر Faster R-CNN است و علاوه بر تشخیص اشیا، یک ماسک پیکسلی برای هر شیء تولید میکند. Mask R-CNN با ترکیب تشخیص و سگمنتیشن، در کاربردهایی مثل شناسایی اشیا در تصاویر شلوغ عملکرد فوقالعادهای دارد.
در نهایت، DeepLab که توسط گوگل توسعه یافته، از کانولوشنهای اتساعی (Dilated Convolutions) استفاده میکند تا میدان دید (Field of View) مدل را افزایش دهد و سگمنتیشن معنایی با دقت بالا ارائه دهد. نسخههای جدید DeepLab در سال ۲۰۲۵ با بهینهسازیهایی برای سرعت، در TensorFlow بهروزرسانی شدهاند.
۲.۴. تشخیص احساسات (Emotion Recognition)
تشخیص احساسات از تصاویر یا ویدئوها یکی از موضوعات پیشرفتهتر در پردازش تصویر است که به تحلیل حالات چهره برای شناسایی احساساتی مثل شادی، غم، خشم، یا ترس میپردازد. این فرآیند با ترکیب تکنیکهای پردازش تصویر و یادگیری عمیق انجام میشود و در حوزههایی مثل تبلیغات (تحلیل واکنش مشتری)، روانشناسی (مطالعه رفتار)، و بازیهای تعاملی (ایجاد تجربههای شخصیسازیشده) کاربرد دارد. برای این کار، ابتدا چهرهها در تصویر شناسایی میشوند و سپس ویژگیهای کلیدی مثل موقعیت چشمها، دهان و ابروها تحلیل میشوند تا حالت احساسی مشخص شود.
یکی از رویکردهای اولیه در این زمینه، استفاده از شبکههای کانولوشنی ساده (CNN) بود که با دیتاستهایی مثل FER-2013 آموزش داده میشدند. این مدلها ویژگیهای بصری چهره را استخراج میکردند و با استفاده از لایههای تماممتصل (Fully Connected Layers)، احساسات را پیشبینی میکردند. اما در سالهای اخیر، Vision Transformers (ViT) که در ادامه توضیح داده میشود، به دلیل دقت بالایشان در تشخیص احساسات ظریف (مثل سردرگمی یا کنجکاوی) محبوب شدهاند. مدل دیگری که میتوان به آن اشاره کرد، FER-Net است که در مقالات اخیر arXiv معرفی شده و برای دیتاستهای کوچک بهینهسازی شده است. این مدل با استفاده از تکنیکهای افزایش داده (Data Augmentation)، عملکرد خوبی حتی با دادههای محدود ارائه میدهد.
۲.۵. پردازش تصاویر سهبعدی و بازسازی 3D Reconstruction
پردازش تصاویر سهبعدی و بازسازی به تبدیل تصاویر دوبعدی به مدلهای سهبعدی میپردازد که در حوزههایی مثل رباتیک، واقعیت افزوده (Augmented Reality)، و بازیسازی کاربرد دارد. این فرآیند معمولاً با استفاده از چندین تصویر از زوایای مختلف انجام میشود تا ساختار سهبعدی یک شیء یا صحنه بازسازی شود. یکی از الگوریتمهای کلاسیک در این زمینه، Structure-from-Motion (SfM) است که با تحلیل حرکت دوربین و نقاط مشترک بین تصاویر، یک مدل سهبعدی تولید میکند. این روش در پایتون با کتابخانههایی مثل OpenCV قابل پیادهسازی است و در پروژههایی مثل نقشهبرداری سهبعدی استفاده میشود.
الگوریتم پیشرفتهتر، NeRF (Neural Radiance Fields) است که در سال ۲۰۲۰ معرفی شد و در سال ۲۰۲۵ با بهینهسازیهایی برای سرعت و دقت، به یکی از ابزارهای اصلی در این حوزه تبدیل شده است. NeRF از شبکههای عصبی برای مدلسازی تابش نور و بازسازی صحنهها استفاده میکند و میتواند تصاویری با کیفیت بالا و جزئیات دقیق تولید کند. این مدل در PyTorch پیادهسازی شده و برای کاربردهایی مثل ساخت انیمیشنهای واقعگرایانه یا شبیهسازی محیطهای سهبعدی بسیار مناسب است.
۳. دیتاستها: قلب پردازش تصویر

دیتاستها نقش حیاتی در آموزش مدلهای پردازش تصویر دارند، زیرا بدون دادههای باکیفیت و متنوع، حتی بهترین الگوریتمها هم نمیتوانند عملکرد خوبی داشته باشند. یکی از معروفترین دیتاستها، ImageNet است که با بیش از ۱۴ میلیون تصویر و ۲۰ هزار دستهبندی، پایه بسیاری از مدلهای از پیش آموزشدیده در TensorFlow و PyTorch محسوب میشود. این دیتاست که در سال ۲۰۰۹ معرفی شد، شامل تصاویری از اشیای روزمره، حیوانات، و مناظر است و در سال ۲۰۲۵ با نسخههای بهروز شده، تنوع بیشتری پیدا کرده است.
دیتاست دیگری که باید به آن اشاره کرد، COCO (Common Objects in Context) است که شامل ۳۳۰ هزار تصویر با ۸۰ دستهبندی است و برای تشخیص اشیا و سگمنتیشن طراحی شده. COCO با برچسبگذاری دقیق جعبههای مرزی و ماسکهای پیکسلی، برای تست مدلهای پیچیده بسیار مناسب است.
برای پروژههای تشخیص احساسات، FER-2013 یک دیتاست تخصصی است که شامل ۳۵ هزار تصویر چهره با ۷ احساس اصلی (شادی، غم، خشم، ترس، تعجب، نفرت، و خنثی) است. این دیتاست با تصاویر سیاهوسفید و رزولوشن پایین، چالشهای خاص خود را دارد، اما برای آموزش مدلهای اولیه بسیار مفید است. در حوزه تصاویر شهری، Cityscapes دیتاستی است که برای سگمنتیشن طراحی شده و شامل تصاویر باکیفیت از خیابانها و مناظر شهری است. این دیتاست در پروژههای رانندگی خودکار کاربرد گستردهای دارد. در نهایت، Open Images V7 که در سال ۲۰۲۵ معرفی شده، با دادههای چندوجهی (Multimodal) مثل تصویر و متن، برای مدلهای پیشرفتهتر که نیاز به تحلیل ترکیبی دارند، بسیار مناسب است
۴. کتابخانههای کلیدی: TensorFlow و PyTorch

۴.۱. کتابخانه TensorFlow
TensorFlow یک فریم ورک متنباز است که توسط گوگل توسعه یافته و به دلیل مقیاسپذیری بالا و پشتیبانی از پروژههای صنعتی، یکی از محبوبترین ابزارها در پردازش تصویر محسوب میشود. این کتابخانه با APIهایی مثل Keras، کار با مدلهای پیچیده را سادهتر کرده است و امکاناتی مثل TensorFlow Object Detection API را برای تشخیص اشیا ارائه میدهد. مدلهایی مثل EfficientNet که با بهینهسازی اندازه شبکه دقت بالایی دارند، و MobileNet که برای دستگاههای کممصرف طراحی شده، از جمله ابزارهای آماده TensorFlow هستند. در سال ۲۰۲۵، نسخههای جدید TensorFlow با بهینهسازیهایی برای پردازش بلادرنگ روی موبایل و سختافزارهای کممصرف منتشر شدهاند که این کتابخانه را برای کاربردهای عملیتر مناسبتر کرده است.
۴.۲. کتابخانه PyTorch
PyTorch که توسط فیسبوک توسعه یافته، به خاطر انعطافپذیری و سادگی در دیباگ کردن شناخته میشود و بیشتر در پروژههای تحقیقاتی و آکادمیک استفاده میشود. این کتابخانه از گراف محاسباتی دینامیک پشتیبانی میکند، به این معنا که میتوان ساختار شبکه را در حین اجرا تغییر داد، که برای آزمایش و توسعه سریع مدلها بسیار مفید است. افزونه TorchVision در PyTorch مدلهای آمادهای مثل ResNet، Mask R-CNN، و YOLO را ارائه میدهد که با چند خط کد قابل استفادهاند. در سال ۲۰۲۵، PyTorch با معرفی قابلیتهای جدید مثل پشتیبانی بهتر از Vision Transformers و بهینهسازی برای GPUهای نسل جدید (مثل NVIDIA H100)، جایگاه خود را در میان محققان تقویت کرده است.
۵. Vision Transformers: انقلابی در پردازش تصویر

Vision Transformers (ViT) یکی از نوآوریهای بزرگ در پردازش تصویر است که در سال ۲۰۲۰ معرفی شد و در سال ۲۰۲۵ به بلوغ رسیده است. این مدلها ابتدا برای پردازش زبان طبیعی (Natural Language Processing) با معماری Transformer طراحی شده بودند، اما با تطبیق آنها برای تصاویر، تحولی در این حوزه ایجاد کردند. معماری Transformer بر پایه مکانیزم “توجه” (Attention Mechanism) کار میکند که به مدل اجازه میدهد به بخشهای مهمتر ورودی وزن بیشتری بدهد. در ViT، تصویر به تکههای کوچک (Patches) تقسیم میشود و هر تکه به صورت یک توالی (Sequence) پردازش میشود، مشابه کلمات در یک جمله. سپس، این تکهها از طریق لایههای Transformer که شامل توجه چندسر (Multi-Head Attention) و لایههای پیشخور (Feed-Forward Layers) هستند، تحلیل میشوند.
مزیت اصلی ViT نسبت به CNNها این است که به جای تمرکز محلی روی فیلترهای کوچک، کل تصویر را به صورت جهانی (Global Context) بررسی میکند. این ویژگی باعث شده که ViT در وظایفی مثل طبقهبندی تصاویر و تشخیص احساسات، دقت بالاتری نسبت به مدلهای سنتی داشته باشد. در سال ۲۰۲۵، نسخههای بهینهشده ViT با مصرف حافظه کمتر و سرعت بالاتر در PyTorch و TensorFlow منتشر شدهاند و در کاربردهایی مثل تحلیل تصاویر پزشکی و سگمنتیشن پیشتاز شدهاند.
خدمات تخصصی ما در زمینه انجام پروژه پردازش تصویر و بینایی ماشین

در دنیای امروز، هوش مصنوعی (AI) و فناوریهای مرتبط با آن به عنوان ابزاری قدرتمند برای حل مسائل پیچیده و پیشرفت در زمینههای مختلف شناخته میشوند. ما با ارائه خدمات تخصصی در حوزه هوش مصنوعی، پردازش تصویر و متن، و همچنین پیادهسازی مقالات و پایاننامههای تحصیلات تکمیلی، همراه شما هستیم تا به اهداف علمی و پژوهشی خود دست یابید.
پیادهسازی مقاله و پایاننامههای تحصیلات تکمیلی
ما در کنار شما هستیم تا مقالات و پایاننامههای کارشناسی ارشد و دکتری خود را به بهترین شکل ممکن پیادهسازی کنید. تمامی مراحل پروژه، از طراحی اولیه تا ارائه نهایی، تحت نظارت مستقیم دکتر مجلسآرا انجام میشود. پیادهسازی مقالات علمی در حوزه هوش مصنوعی. اجرای تخصصی پایاننامههای کارشناسی ارشد و دکتری. تضمین کیفیت و دقت بالا در تمامی مراحل