
در این پروژه قصد داریم توییت های فارسی که در زمینه کرونا هستند را با کمک مدل طبقه بند BERT طبقه بندی کنیم. این مجموعه داده شامل 7268 توییت به زبان فارسی در مورد کرونا هستند که از قبل برچسب یا لیبل خورده اند. لیبل های ما در 8 دسته: ‘پرسش’, ‘ترس ‘, ‘تعجب’, ‘خنثی’, ‘خنده’, ‘خوشحالی’, ‘عصبانیت’, ‘غم’ دسته بندی شده اند. هدف از انجام پروژه این است که بعد از ساخت مدل با روش برت (BERT) بتوانیم توییت های جدیدی که منتشر می شوند را بر اساس این 8 دسته تقیسم بندی کنیم.
چالش های ما در انجام این پروژه به دو بخش عمده تقیسم بندی شدند. اول اینکه نسبت لیبل های توییت ها یکسان نبودند. دومی استفاده از روش BERT فارسی بر روی توییت ها بود. پس از اتمام مراحل توانسیتم به دقت 80٪ برسیم که دقت خوبی بر روی این تعداد داده بود.
این پروژه با زبان پایتون با کتابخانه Tensoflow و در محیط گوگل کولب نوشته شده است.
آماده سازی داده های جمع آوری شده از توییتر فارسی
در این پروژه بخش قابل توجهی از کار مربوط به پاکسازی داده های متنی بود. چرا که توییت های کاربران دارای مقادیر ناخواسته ای است که باید تمیز یا حذف شوند.
در اولین مرحله کلمات ناخواسته یا stopwords حذف شدند. برای حذف stopwords لیستی از کلمات به صورتی دستی جمع آوری شد. این لیست شامل 1323 کلمه برای حذف است. کلماتی مانند از جمله،ناگاه، نداریم. پس از حذف این کلمات ستون جدیدی به دیتا اضافه کردیم تا مشخص شود از هر توییت چه تعداد کلمه حذف شده است.
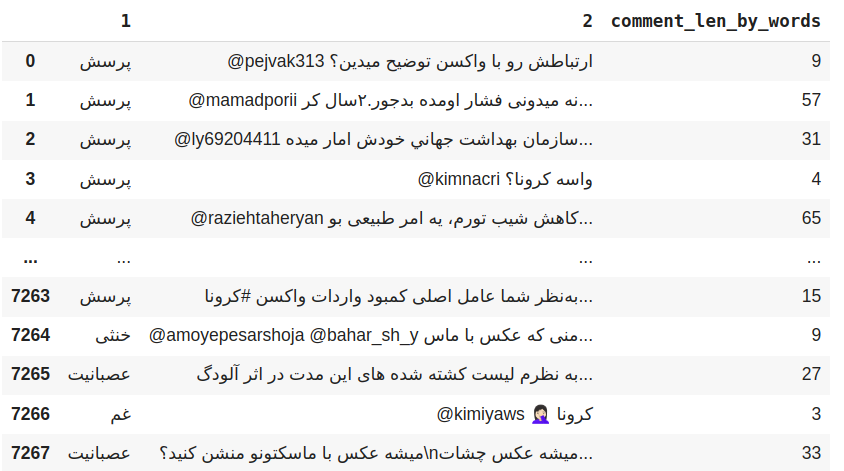
در مرحله بعدی برای آن که توییت ها با تعداد کلمات نا متعارف وارد مدل نشوند طول کمتر از 3 توییت و بیشتر از 250 را حذف کردیم.
در ادامه ی بخش پاکسازی توییت ها URL ها ایموجی ها سمبل ها حذف شدند. برای آنکه کلمات با معانی یکسان ولی نگارش متفاوت یکپارچه شوند از کتابخانه هضم(hazm) استفاده کردیم. با این روش کلماتی مثل رو، رفت، رفتن که معانی یکسانی دارند ولی نگارش متفاوتی دارند تبدیل به ریشه کلمه می شوند. این کار کمک می کند در مرحله ساخت مدل به عملکرد بعتری برسیم.
مصور سازی داده های توییتر:
پس از پاکسازی داده ها، نمودار فراوانی لیبل ها را رسم می کنیم تا متوجه شویم از هر دسته چه تعداد توییت وجود دارد. روش های مختلفی برای مصور سازی توییت های وجود دارد. ما از کتابخانه Plotly استفاده کردیم. این کتابخانه امکان رسم نمودار های پویا را می دهد. به این معنی که کاربر یا مشاهده کننده نمودار می تواند بخش هایی از نمودار را حذف یا مشخص کند چه بخشی از دیتا مشاهده شود. این قابلیت بویژه برای طراحی داشبورد های مدیریتی بسیار کاربرد دارد.
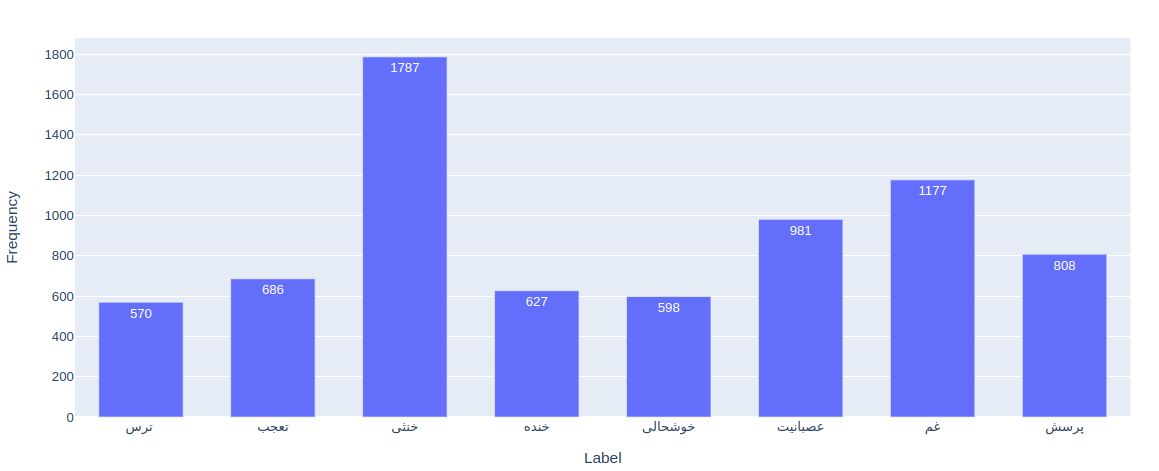
همانطور که مشاهده می شود تعداد توییت های موجود در دسته “خنثی” بسیار بیشتر از دسته های دیگر است.
لیبل های ما به صورت رشته ای هستند. برای طبقه بندی داده ها این لیبل ها باید با مقادیر عددی جایگزین شوند. این جابجایی به صورت زیر است.
![]()
برای ساخت و اریابی مدل باید داده ها به سه قسمت آموزش ارزیابی و تست تبدیل شوند. در ابتدا 10 درصد داده ها برای تست و 90 درصد برای آموزش جداسازی شدند. سپس از 90 درصد داده آموزش 10 درصد برای ارزیابی یا validation جداسازی شدند. در نهایت تعداد 5859 توییت برای آموزش مدل، برای validation و 724 برای تست مدل در نظر گرفته شد.
BERT چیست؟
برت یا BERT (Bidirectional Encoder Representations from Transformers) در سال 2018 توسط بخش تحقیقات شرکت گوگل طراحی شد و توانست انقلاب بزرگی در زمینه پردازش ماشین و حتی دیگر زمینه های هوش مصنوعی ایجاد کند. Bert نوعی مدل زبانی است که بر پایه معماری ترنسرفورمرها بنا شده است. (ترنسفورمرها از مکانسیم توجه برای یادگیری استفاده می کنند.)روش های قدیمی تر پردازش زبان طبیعی مانند LSTM و خانواده RNN ها متن را از یک سو می دیدند. یعنی یا از چپ به راست یا برعکس ولی در مدل برت مدل داده ها را به صورت یکپارچه یا بدون جهت می بیند. نتایج عملکرد مدل برت نشان می داد خروجی کار دقت بسیار بیشتری دارد و مدل خیلی بهتر می توانست محتوا و جریان داده ای را شناسایی کند.
برای آموزش مدل BERT بیشتز از 4 روز زمان صرف شده است. همچنین تعداد پارامتر های این شبکه بیش از 300 میلیون است. ساخت این مدل برای افراد عادی با سیستم های معمولی غیر ممکن است به همین از مدل اماده BERT برای پردازش زبان طبیعی استفاده می کنیم.
خوشبختانه برای زبان فارسی مدل BERT آموزش داده شده است که ما در این پژوهش از این مدل آموزش دیده بر روی داده های فارسی استفاده کرده ایم.
ساخت مدل BERT
برای ساخت مدل، کلمه ها را توکن بندی می کنیم و به هر کلمه یک عدد نسبت می دهیم. به صورت زیر:
![]()
تمام توییت ها بایستی طول یکسان داشته باشند. به همین دلیل توییت هایی که طول کمتری دارند به انتهای آن ها 0 اضافه می کنیم. نمونه داده ی تبدیل شده به همراه لیبل آن به صورت زیر است.

در انتها داده ها به همراه لیبل آن ها را به مدل طبقه بند BERT می دهیم تا مدل اصلی ساخته شده و دقت را محاسبه کنیم.
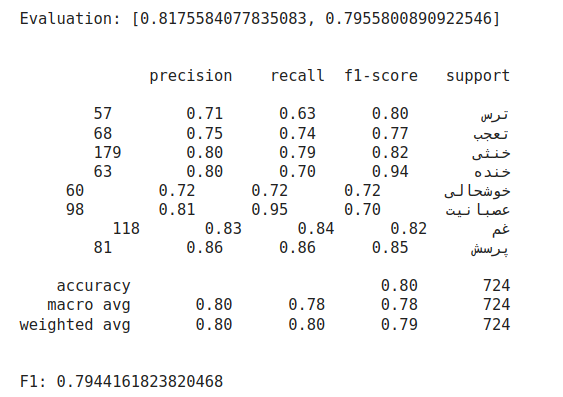
با استفاده Classification report خروجی مدل را به تفکیک هر لیبل می توانیم مشاهده کنیم. مقدار F1 برای کل داده ها 0.79 است.
نتیجه گیری
در این پروژه تلاش کردیم دیتای توییتر فارسی که در 8 کلاس لیبل بندی شده بود را طبقه بندی کنیم. ابتدا داده ها را تمیز کردیم سپس از مدل Bert فارسی استفاده کردیم تا بتوانیم بهترین دفت را از داده ها بدست آوریم. نتایج نشان دادند به دقت 81٪ و F1 79٪ رسیم که نشان دهند عملکرد مناسب روش استفاده شده در این پروژه بوده است.
کدهای طبقه بندی داده های توییتر فارسی با روش BERT کجا هستند؟
سلام وقت بخیر
ضمن تشکر از توضیحات خوبتان در خصوص پروژه “طبقه بندی داده های توییتر فارسی با روش BERT”
چگونه میتوانم به کد پروژه دسترسی داشته باشم؟