
هنگامی که مطالعه علوم داده را شروع کردید ، چیزی به نام “فرآیند علوم داده” را خواهید شنید. این عبارت به یک فرآیند پنج مرحله ای اشاره دارد که معمولاً دانشمندان علوم داده هنگام کار روی یک پروژه انجام می دهند. در این مطلب به بررسی هر یک از آنها می پردازم ،چه مسایلی مهم هستند و تکنولوژی هایی مورد استفاده قرار گیرند.
1. جمع آوری داده ها
هنگامی که شما در حال مطالعه علوم داده هستید ، ممکن است داده های شما توسط مدرسان به شما داده شود. همچنین می توانید مجموعه داده های زیبایی زیادی را در Kaggle.com یا جستجوی Google Dataset جستجو کنید. در این حالت ، دستیابی به اطلاعات بسیار ساده است ، فقط مجموعه داده را بارگذاری و از آن استفاده کنید.
در زندگی واقعی کمی پیچیده است. برای به دست آوردن داده ها با فرمت موردنیاز ، احتمالاً از API یا scraping وب و دانش اولیه HTML خود برای به دست آوردن هر آنچه نیاز دارید استفاده می کنید. در اینجا مطالبی راجع به روش های جمع آوری داده با کمک خزنده توضییح داده ایم. اساس کار علم داده با داده است. پس هر چقدر بتوانیم اطلاعات بیشتر و مفید تری بدست آوریم خروجی کار با کیفیت بیشتری بدست می آید.
فن آوری های مورد استفاده: HTML ، SQL ، BeautifulSoup. scrapy
۲.تمیز کردن داده ها
مجدداً ، اگر مجموعه داده قبلاً توسط مدرسان خود به شما داده شده باشد ، یا آن را در یکی از وب سایت های ذکر شده در بالا بدست آورده اید ، این احتمال وجود دارد که داده های شما از قبل پاک باشند. اما در بیشتر موارد تمیز کردن مورد نیاز است. شما باید مقادیر گمشده را کنترل کنید (و در مورد آن باهوش باشید) ، مطمئن شوید که تمام ستون ها در داده های صحیح (تاریخ زمان ، اعداد صحیح ، شناورها ، رشته ها و غیره) قرار دارند ، تمام نام های ستون ها حاوی مقدار تهی نیستند (به خصوص اگر از NLP برای انجام تجزیه و تحلیل و مدل سازی استفاده می کنید مهم است). برای اطلاعات بیشتر ،اینجا را مشاهده کنید.
ابزار های مورد استفاده: pandas, numpy
3. EDA
EDA مخفف تجزیه و تحلیل داده ها(Exploratory Data Analysis) است. در این مرحله از فرآیند باید اطلاعات خود را بشناسید. شکل جدول چیست؟ چند ردیف و ستون وجود دارد؟ انواع داده ها (برای اطمینان از تمیز کردن صحیح) چیست؟ چگونه مقادیر عددی توزیع می شوند؟ آیا نوعی همبستگی / چند خطی وجود دارد؟ آیا اگر می خواهید طبقه بندی کنید ، عدم تعادل کلاس وجود دارد؟ قبل از رسیدن به مرحله بعدی باید به همه این سؤالات پاسخ دهید. . اگر می خواهید نتایج را به مخاطبان غیر فنی ارائه دهید ، این مرحله نیز بسیار مهم است. در حالی که اطلاعات خود را به روشی معنی دار کاوش می کنید ، تجسم خوبی از مساله ایجاد خواهید کرد.
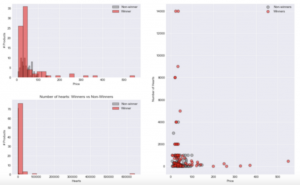
ابزار های مورد استفاده: Pandas, Numpy, Matplotlib, Seaborn, Plotly و …
۴. مدل سازی
این سرگرم کننده ترین قسمت و اصل فرایند است.در واقع ما تمام مراحل قبلی را انجام دادیم که یک داده درست و تمیز را برای مدل سازی اماده کنیم پس از اتمام آماده سازی ، شما می توانید یک الگوی یادگیری ماشین ایجاد کنید که نوعی پیش بینی را انجام می دهد. که می تواند یک رگرسیون خطی ساده ، رگرسیون چندگانه ، طبقه بندی ، سری زمانی ، آنالیز NLP یا یک پروژه بینایی ماشین با شناخت تصویر باشد.
ابزار های مورد استفاده:Scikit-Learn, SciPy, NumPy, Keras, Tensorflow, PyTorch, XGBoost و بسیاری دیگر از ابزار های مدسازی
۵. تفسیر و ارزیابی مدل تولید شده.
در انتها شما به دنبال چنین خروجی خواهید بود.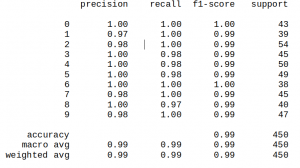
اما معنی این داده چیست؟ نمی توان این داده ها را به سرمایه گذار یا کارفرما ارایه داده و گفت خروجی مدل من ۹۹٪ است. اگر این اطلاعات را به او بدهید به شما خواهد گفت که لطفا فارسی حرف بزنید!. پس راه حل چیست؟ ما باید از این اطلاعات استفاده کنیم در زمینه های دیگر. مثلا این اطلاعات را به بخش توسعه نرم افزار تلفن همراه دهیم که آن ها متناسب با تحلیل بدست امده نرم افزار را توسعه دهند یا از ان در بخش توسعه وب سایت استفاده کنیم. از همین رو کسی که قصد در زمینه علم داده متخصص شود باید سواد حداقلی از دیگر حوزه های نرم افزار هم داشته باشد تا بتواند از تحلیل هی بدست امده بهترین استفاده را بکند.