
پیش بینی انتخابات همیشه برای علاقه مندان به حوزه سیاست و فرهنگ و بخش قابل توجهی از مردم دارای اهمیت زیادی است. به همین دلیل در چند سال گذشته با رشد هوش مصنوعی و روش های تحلیل داده گرایش متخصصان این حوزه به کار بر روی پیش بینی انتخابات بسیار زیاد شده است. با بررسی هایی که انجام دادیم متوجه شدیم بیشتر کارهایی که در زمینه انجام شده است در خارج از کشور است و تحلیل های داخلی اگر انجام شده باشد در دسترس عموم مردم نیست به همین دلیل تلاش کردیم یک مدل هوشمند برای تحلیل داده ها طراحی کنیم تا بتوان انتخابات ریاست جمهوری را پیش بینی کنیم. این پروژه به چند بخش عمده تقسیم بندی شده است که تلاش می کنیم به صورت قدم به قدم آن ها را بررسی و توضیح دهیم.
جمع آوری داده ها
برای پیش بینی انتخابات ریاست جمهوری ابتدا باید داده ها جمع آوری شود. یکی از بهترین پلتفرم ها برای تحلیل افکار و ایده های افراد جامعه، داده های توییتر است.
برای جمع آوری دادهها، توییتر ابزاری را در اختیار پژوهشگران و متخصصان قرار داده که میتوانند به صورت رایگان و با تعداد محدود (۱ میلیون توییت) را در بازه زمانی و برچسبهای دلخواه جمعآوری کنند. برای جمعآوری دادهها از توییتر ابتدا بایستی در بخش توسعه دهندهگان این سایت ثبت نام نمود. پس از موفق بودن عملیات، یک کد منحصر به فرد در اختیار شخص قرار میگیرد تا با کمک آن بتواند یک خزنده(crawler) بر روی سایت توییتر نوشته و دادهها را دریافت کند.
برای آمادهسازی خزنده وب از زبان پایتون و کتابخانه tweepy کمک گرفتیم. بازه زمانی مدنظر برای جمعآوری دادهها از ۱۲ فروردین ۱۴۰۰ تا ۲۷ خرداد ۱۴۰۰ (۱ روز قبل از برگزاری انتخابات۱۴۰۰) است. در این مدت بیشترین واکنش و بازخورد مردم نسبت به انتخابات و شرایط موجود بر کشور مرتبط با موضوع انتخابات در شبكههای اجتماعی منتشر شده است.
هدف از این پروژه پیشبینی انتخابات ریاست جمهوری است و قصد داریم رویکرد مردم نسبت به هر کاندیدا را بررسی کنیم. به همین دلیل توییتهایی را انتخاب کردیم که حتما در مورد یکی از کاندیداها اعمال نظر کردهاند.
با این کار توییتهایی که مربوط به کلیت انتخابات است را مورد بررسی قرار ندادیم چون بخش قابل توجهی از کاربران توییتر خواهان تحریم انتخابات بودهاند. برای این منظورتوییتها حاوی هشتگ با نامهای شش کاندیدا را در بازه زمانی مورد اشاره را دریافت کردیم.
برای اطمینان از دریافت همه توییتها در بازه مورد نظر تلاش شد همه جایگشتهای تمامي کاندیداها را برای دریافت توییتهای حاوی آن هشتگ را دریافت نماییم، كه در مجموع 422938 تعداد توييت استخراج شده است.
پیش پردازش دادهها
در حوزه متن کاوی یکی از مراحل ضروری پیش پردازش دادههای متنی برای تحلیلهای مراحل بعد و یکسان سازی و نرمال سازی متون است. قبل از تحلیل هرگونه داده ها می بایست نویزها و داده های بی ارزش از داده های مفید جداسازی شوند. در ادامه به بخشی از موارد انجام شده جهت پاکسازی داده ها می پردازیم.
- پاکسازی متن توییت ها از اموجی ها و کاراکترهای خاص مانند @ , # و …
- حذف کلمات ناخواسته
- ریشه یابی کلمات
- حذف توییت های که حاوی هشتگ هایی بیش از یک نامزد بودند.
- حذف توییت هایی با طول کمتر از ۳ کلمه
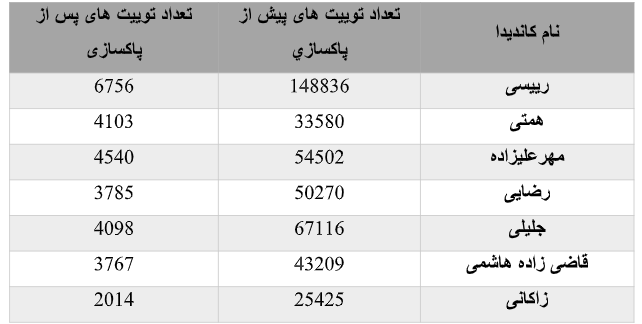
با اتمام فرایند پاکسازی دادهها میتوانیم عملیات مدلسازی را روی آنها انجام دهیم. جدول زیر تعداد هر توییت به اجزا هر کاندیدا را مشخص می کند.
امتیاز دهی به توییت ها
در این پروژه از مدلهای زبانی مبدل برای امتیازدهی به وزن توییتها استفاده شده است. به این صورت که بعد از پاکسازی توییتها، هر توییت به مدل زبانی داده می شود تا امتیاز آنتوییت بدست بیاد. ما برای این تحلیل و پیش بینی انتخابات از مدل ParsiNLU استفاده کردیم.
مدل ParsiNLU بر اساس مدل mt5 است. مدل mt5 یک مدل پردازش متن چند زبانه است. این مدل توانایی تحلیل 101 زبان دنیا را دارد. مبدل ParsiNLU از ساختار mt5 استفاده کرده و بر روی مجموعه دادههای فارسی آموزش دیده شده است.
تحلیل احساسات با مبدل ParsiNLU
تحلیل احساسات با مبدل ParsiNLU در سه بخش میتواند فعالیت کند
- تشخیص احساسات کل متن
- استخراج جنبههایی که یک احساس نسبت به آنها ابراز میشود
- استخراج قطبیت موجود در یک متن
برای تقویت بخش تحلیل احساسات ParsiNLU این مبدل بر روی مجموعه دادههای نظرات سایت دیجیکالا و سایت تیوال آموزش داده شده است.
ما مدل ParsiNLU را بر روی توییتها اجرا کردیم تا امتیاز هر توییت مشخص شود. هر توییت امتیازی بین 2- تا 2+ دریافت میکند. هدف در این بخش تعیین نظر هر کاربر نسبت به هر کاندیدا است. برای این منظور جدولی تشکیل شد که سطرهای آن کاربران هستند. به این ترتیب توییتهایی که یک کاربر در مورد کاندیداهای مختلف ارسال کرده است مشخص میشود. حال با کمک مدل زبانی معرفی شده امتیاز هر توییت مشخص میشود.
توییتهای ارسال شده مربوط به هر کاندیدا که امتیاز بیشتری داشتهاند به عنوان رای آن کاربر در نظر گرفته میشوند. جدول زیر نمونهای از جدول محاسبه رای کاربران است
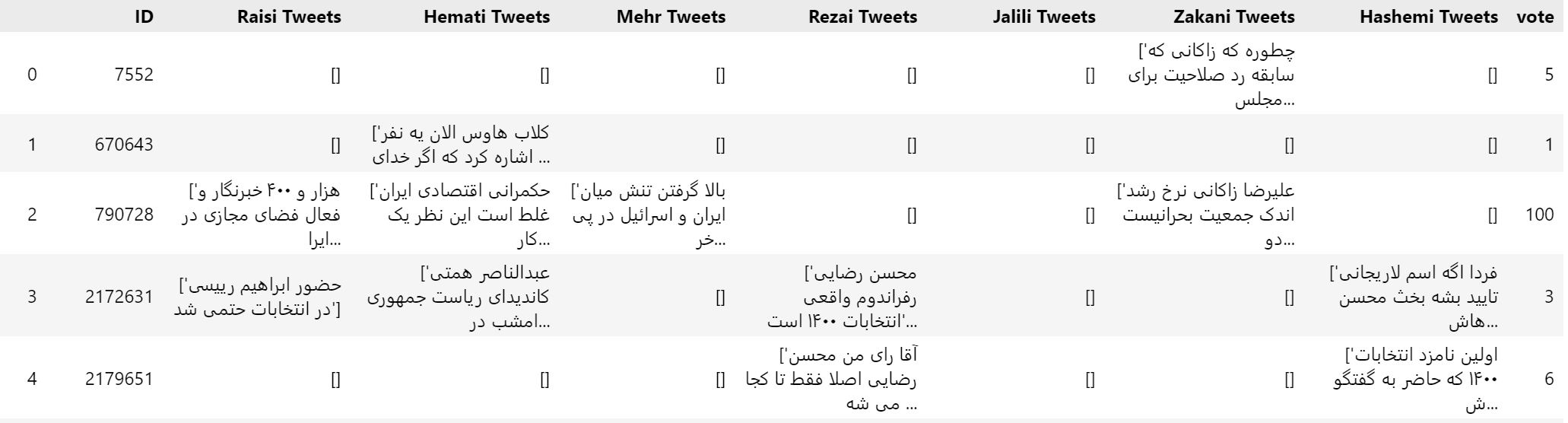
در جدول بالا کاربر با شماره 7552 فقط در مورد آقای زاکانی توییت ارسال کرده است و این توییت دارای بار مثبت بوده است. به همین دلیل در محاسبه رای عدد شماره 5 در نظر گرفته شده است که معادل با رای به این کاندیدا است.
کاربر با شماره 2172631 در مورد ۴ کاندیدا توییت زده است. امتیاز مربوط به هر کاندیدا محاسبه شده. رای در نظر گرفته شده برای این کاربر محسن رضایی است که با عدد ۳ در ستون رایها مشخص شده است.
تجمیع رایها
پس از آنکه رای هر کاربر مشخص شد نوبت به تجمیع آرا می رسد که بایستی رای هر کاندیدا محاسبه شود. برای این کار فقط کافی است تعداد رای هر کاندیدا محاسبه شده با دیگر کاندیداها مقایسه شود تا بتوانیم پیشبینی تحلیلی از برنده انتخابات را ارائه دهیم. جدول زیر به صورت خلاصه آرای تجمیع شده را نشان میدهد.
|
نام کاندیدا |
تعداد رای کسب شده |
|
ابراهیم رییسی |
1064 |
|
محسن مهرعلیزاده |
802 |
|
محسن رضایی |
635 |
|
عبدالناصر همتی |
580 |
|
قاضی زاده هاشمی |
503 |
|
سعید جلیلی |
437 |
|
علیرضا زاکانی |
274 |
|
بدون رای |
3044 |
به این ترتیب با توجه به نتایج بدست آمده از روش پیشنهادی برنده انتخابات آقای ابراهیم رئیسی است.
همان طور که می دانیم برنده انتخابات ۱۴۰۰ آقای رئیسی بودند که نشان دهنده درستی پیش بینی انتخابات است.
انتخابات ۱۴۰۳
حال با توجه به مدل طراحی شده که می دانیم دقت خوبی برای پیش بینی انتخابات دارد تلاش می کنیم که انتخابات پیش رو را پیش بینی کنیم. نکته که باید به آن توجه کنیم این است که بعد از ان که توییتر به ایکس تغییر نام داد امکان جمع آوری داده ها بسیار دشوارتر شده است. همچنین این تحلیل در فاصله ۲۴ ساعت بعد از مناظره اول کاندیدا ریاست جمهوری انجام شده است و امکان تغییر آرا با توجه به شرایط انتخابات می تواند بسیار متغیر باشد.
با توجه به مدلی که طراحی کردیم درصد محبوبیت کاندیداها به شرح زیر است.
|
نام کاندیدا |
میزان محبوبیت |
|
پزشکیان |
۲۴٪ |
|
قالیباف |
۲۱٪ |
|
جلیلی |
۲۰٪ |
|
زاکانی |
۱۳٪ |
|
قاضی زاده |
۱۳٪ |
|
پور محمدی |
۶٪ |