
ارزیابی الگوریتم یادگیری ماشین شما یک قسمت اساسی در هر پروژه است. ممکن است مدل شما هنگام ارزیابی با استفاده از معیار دقت، نتایج رضایت بخشی به شما بدهد اما وقتی در برابر سایر معیارها مانند precision یا سایر معیارهای دیگر ارزیابی شود، نتایج ضعیفی کسب کند. بیشتر اوقات ما برای سنجش عملکرد مدل خود از دقت طبقه بندی استفاده می کنیم، اما برای قضاوت واقعی در مورد مدل کافی نیست. در این پست، ما انواع مختلفی از معیارهای ارزیابی موجود را پوشش خواهیم داد. مدل ها به اندازه کیفیت پیش بینی هایشان مفید هستند واساساً هدف ما ایجاد مدل نیست (که خب کار آسانی است) بلکه ایجاد مدل هایی با کیفیت بالا است (که اساسا سخت است). بنابراین، قبل از بررسی الگوریتم های بی شمار یادگیری، ابتدا نحوه ارزیابی مدل های تولید شده را بررسی می کنیم.
مدل Cross-Validation
چگونگی ارزیابی مدل در دنیای واقعی:
یک pipline ایجاد کنید که داده ها را پیش پردازش کند، سپس مدل را آموزش دهد و در آخر آن را با استفاده از cross-validation ارزیابی کند.
# Load libraries from sklearn import datasets from sklearn import metrics from sklearn.model_selection import KFold, cross_val_score from sklearn.pipeline import make_pipeline from sklearn.linear_model import LogisticRegression from sklearn.preprocessing import StandardScaler # Load digits dataset digits = datasets.load_digits() # Create features matrix features = digits.data # Create target vector target = digits.target # Create standardizer standardizer = StandardScaler() # Create logistic regression object logit = LogisticRegression() # Create a pipeline that standardizes, then runs logistic regression pipeline = make_pipeline(standardizer, logit) # Create k-Fold cross-validation kf = KFold(n_splits=10, shuffle=True, random_state=1) # Conduct k-fold cross-validation cv_results = cross_val_score(pipeline, # Pipeline features, # Feature matrix target, # Target vector cv=kf, # Cross-validation technique scoring="accuracy", # Loss function n_jobs=-1) # Use all CPU scores # Calculate mean cv_results.mean() 0.96493171942892597
در بررسی اول، ارزیابی مدل های یادگیری با نظارت ممکنه ساده به نظر برسد: یک مدل را آموزش دهید و سپس محاسبه کنید که چقدر با استفاده از برخی از معیارهای عملکرد، عملکرد خوبی داشته است. ولی این رویکرد اساساً ناقص است. اگر ما با استفاده از داده های خود مدلی را آموزش دهیم و سپس ارزیابی کنیم که چطور این داده ها خوب عمل کرده است، به هدف مورد نظر خود نمی رسیم. هدف ما ارزیابی این نیست که مدل چقدر در داده های آموزشی ما کار می کند، بلکه چقدر در داده هایی که قبلاً هرگز ندیده است (مثلاً مشتری جدید، جرم جدید، تصویر جدید) عملکرد خوبی دارد. به همین دلیل، روش ارزیابی ما باید به ما کمک کند تا درک کنیم که مدلها چقدر قادر به پیش بینی داده هایی هستند که قبلاً هرگز ندیده اند.
یک روش می تونه نگه داشتن بخشی از داده ها برای تست باشد. به این روش validation (یا hold-out) می گویند. در validation ویژگی ها و اهداف یا کلاس به دو قسمت تقسیم می شوند که مجموعه آموزش یا tarin و مجموعه تست یا test نامیده می شوند. ما مجموعه تست را کنار می گذاریم، انگارکه قبلاً هرگز آن را ندیده ایم. در مرحله بعدی مدل خود را با داده های train، با استفاده از ویژگی ها و هدف آموزش می دهیم تا به مدل یاد دهیم چگونه بهترین پیش بینی را انجام دهد. در آخر، با استفاده از داده های تست مدل را ارزیابی میکنیم. رویکرد validation دو نقطه ضعف بزرگ دارد. اول، عملکرد این مدل بستگی به این دارد که چه تعداد داده برای test انتخاب شده است. دوم، این مدل با استفاده از تمام داده های موجود train نمی شود و بر روی تمام داده های موجود ارزیابی نمی شود.
یک روش بهتر که بر این نقاط ضعف غلبه می کند، k-fold cross-validation (KFCV) نامیده می شود. در KFCV، داده ها را به بخشهایی تقسیم می کنیم که “folds” نامیده می شوند. سپس مدل با استفاده از k – 1 folds train می شود و با آخرین fold تست می شود. مثلا اگر k ده قسمت باشد دفعه اول k1 برای قسمت test و k2 تا k10 برای train انتخاب می شود دفعه دوم k2 برای قسمت test بقیه برای train استفاده می شود به همین ترتیب این روند 10 بار تکرار می شود و هر بار 10 تا دقت به ما می دهد و در آخر میانگین این 10 عدد را به عنوان دقت مدل در نظر می گیرد.
در این روش، k-fold cross validation با مقدار k برابر 10 انجام می دهیم و خروجی اعداد ارزیابی را به cv_results میدهیم:
# View score for all 10 folds cv_results array([ 0.97222222, 0.97777778, 0.95555556, 0.95 , 0.95555556, 0.98333333, 0.97777778, 0.96648045, 0.96089385, 0.94972067])
هنگام استفاده از KFCV سه نکته مهم وجود دارد که باید آنها را در نظر گرفت. ابتدا، KFCV فرض می کند که هر مشاهده مستقل از دیگری ایجاد شده است ( داده ها به طور یکسان توزیع می شوند independent identically distributed (IID)). اگر داده ها IID باشند، بهتر است هنگام اختصاص دادن به fold ها، مشاهدات را برهم بزنیم و مخلوط کنیم. در scikit-learn می توانیم shuffle را True ست کنیم که shuffling انجام شود shuffle=True.
دوم، هنگامی که ما از KFCV برای ارزیابی یک طبقه بندی استفاده می کنیم، اغلب داشتن folds ها با درصد تقریباً یکسان مشاهدات از هر یک از گروههای مختلف هدف (که به آن طبقه بندی شده stratifiedk-fold می گویند) مزیت محسوب می شود. به عنوان مثال، اگر بردار هدف ما شامل جنسیت باشد و 80٪ مشاهدات مردانه باشد، در این صورت هر fold شامل 80٪ مشاهدات مردانه و 20٪ مشاهده زنانه است. در scikit-learn، می توانیم با جایگزینی کلاس KFold با StratifiedKFold ،k-fold cross-validation را انجام دهیم.
در آخر، هنگامی که ما از مجموعه های validation یا cross-validation استفاده می کنیم، مهم است که داده ها را بر اساس مجموعه داده های آموزش پیش پردازش کنیم و سپس این تغییرات را هم در قسمت آموزش و هم تست اعمال کنیم. به عنوان مثال، وقتی با داده های استاندارد مرحله fit را انجام مدیدم، فقط میانگین و واریانس مجموعه داده های آموزش را محاسبه می کنیم. سپس آن تغییر شکل را (با استفاده ازtransform) در مجموعه های آموزشی و آزمایشی اعمال می کنیم.
# Import library from sklearn.model_selection import train_test_split # Create training and test sets features_train, features_test, target_train, target_test = train_test_split( features, target, test_size=0.1, random_state=1) # Fit standardizer to training set standardizer.fit(features_train) # Apply to both training and test sets features_train_std = standardizer.transform(features_train) features_test_std = standardizer.transform(features_test)
دلیل این کاراین است که ما وانمود می کنیم مجموعه داده های تست ناشناخته هستند. اگر ما هر دو پیش پردازنده خود را با استفاده از مشاهدات هر دو مجموعه آموزشی و آزمایشی fit کنیم، برخی از اطلاعات مجموعه تست به مجموعه آموزش ما ورود می کند. این قانون برای هر مرحله از پیش پردازش مانند انتخاب ویژگی اعمال می شود.
scikit-learn در هنگام استفاده از تکنیک های validation انجام این کار را آسان می کند. ما ابتدا pipeline ایجاد می کنیم که داده ها را پیش پردازش می کند (به عنوان مثال standardizer) و سپس یک مدل (regression regression، logit) را آموزش می دهیم:
# Create a pipeline pipeline = make_pipeline(standardizer, logit)
سپس KFCV را با استفاده از آن pipeline اجرا می کنیم و scikit همه کارها را برای ما انجام می دهد:
# Do k-fold cross-validation cv_results = cross_val_score(pipeline, # Pipeline features, # Feature matrix target, # Target vector cv=kf, # Cross-validation technique scoring="accuracy", # Loss function n_jobs=-1) # Use all CPU scores
cross_val_score همراه با سه پارامتر است که ما در مورد آنها بحث نکرده ایم که قابل توجه است. cv روش cross-validation را تعیین می کند. K-fold رایج ترین است، اما موارد دیگری نیز وجود دارد، مانند leave-one-out-cross-validation که در آن تعداد fold k برابر با تعداد مشاهدات است. پارامترscoring معیار موفقیت را مشخص می کند، تعدادی از آنها جلوتر امده اند. در آخر، n_jobs = -1 به scikit-learn یاد می دهد تا یاد بگیرید از هر هسته موجود استفاده کند. مثلا اگر رایانه شما دارای چهار هسته (core) است، scikit-learn برای سرعت بخشیدن به کار، از هر چهار هسته همزمان استفاده می کند.
ایجاد یک مدل رگرسیون پایه
چگونگی ایجاد یک مدل ساده رگرسیون پایه برای مقایسه با مدل خود:
برای ایجاد یک مدل ساده به عنوان پایه درکتابخانه scikit-learn از DummyRegressor استفاده می کنیم.
# Load libraries from sklearn.datasets import load_boston from sklearn.dummy import DummyRegressor from sklearn.model_selection import train_test_split # Load data boston = load_boston() # Create features features, target = boston.data, boston.target # Make test and training split features_train, features_test, target_train, target_test = train_test_split( features, target, random_state=0) # Create a dummy regressor dummy = DummyRegressor(strategy='mean') # "Train" dummy regressor dummy.fit(features_train, target_train) # Get R-squared score dummy.score(features_test, target_test) -0.0011193592039553391
برای مقایسه، مدل را آموزش می دهیم و عملکردش را ارزیابی می کنیم:
# Load library from sklearn.linear_model import LinearRegression # Train simple linear regression model ols = LinearRegression() ols.fit(features_train, target_train) # Get R-squared score ols.score(features_test, target_test) 0.63536207866746675
DummyRegressor به ما این امکان را می دهد که یک مدل بسیار ساده ایجاد کنیم تا بتوانیم از آن برای مقایسه با مدل واقعی خود استفاده کنیم. این اغلب می تواند برای شبیه سازی فرآیند پیش بینی موجود “naive” در یک محصول یا سیستم مفید باشد. به عنوان مثال، ممکن است یک کالایی به سختی رمزگذاری شود به منظور این که فرض کند همه کاربران جدید صرف نظر از ویژگی های آنها در ماه اول 100 دلار هزینه خواهند کرد. اگر این فرض را در یک مدل پایه رمزگذاری کنیم، می توانیم مزایای استفاده از روش یادگیری ماشین را به طور واضح بیان کنیم.
DummyRegressor از پارامتر strategy برای تعیین روش پیش بینی از جمله مقدار میانگین یا مدیوم در مجموعه آموزش استفاده می کند. علاوه بر این، اگر استراتژی را روی constant قرار دهیم و از پارامتر constant استفاده کنیم، می توانیم dummy regtessor ی تنظیم کنیم که تعدادی مقادیر constant را برای هر مشاهده پیش بینی کند:
# Create dummy regressor that predicts 20's for everything clf = DummyRegressor(strategy='constant', constant=20) clf.fit(features_train, target_train) # Evaluate score clf.score(features_test, target_test) -0.065105020293257265
به صورت پیش فرض، score عدد ضریب تعیین (2 R-squared, R) را برمی گرداند:
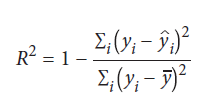
yi مقدار واقعی هدف یا کلاس است، yi مقدار پیش بینی شده و ȳ مقدار میانگین برای بردار هدف است.
هرچه R2 به 1 نزدیکتر باشد، اختلاف بیشتری در بردار هدف وجود دارد که با ویژگی ها توضیح داده می شود.
ایجاد یک مدل طبقه بندی پایه
چگونگی ایجاد یک طبقه بندی ساده پایه برای مقایسه با مدل خود:
از کتابخانه scikit-learn ابزاار DummyClassifier را استفاده می کنیم.
# Load libraries from sklearn.datasets import load_iris from sklearn.dummy import DummyClassifier from sklearn.model_selection import train_test_split # Load data iris = load_iris() # Create target vector and feature matrix features, target = iris.data, iris.target # Split into training and test set features_train, features_test, target_train, target_test = train_test_split( features, target, random_state=0) # Create dummy classifier dummy = DummyClassifier(strategy='uniform', random_state=1) # "Train" model dummy.fit(features_train, target_train) # Get accuracy score dummy.score(features_test, target_test) 0.42105263157894735
با مقایسه طبقه بندی پایه با طبقه بندی tarain شده، می توانیم پیشرفت را مشاهده کنیم:
# Load library from sklearn.ensemble import RandomForestClassifier # Create classifier classifier = RandomForestClassifier() # Train model classifier.fit(features_train, target_train) # Get accuracy score classifier.score(features_test, target_test) 0.94736842105263153
معیار عملکرد طبقه بندی کننده (classifier) این است که چقدر بهتر از حدس تصادفی است. DummyClassifier ازscikit-learn این مقایسه را آسان می کند. پارامتر strategy به ما چندین گزینه برای تولید مقادیر می دهد. دو strategy بسیار مفید وجود دارد. اول، stratified پیش بینی هایی متناسب با نسبت کلاس طبقه بردار هدف داده های train را انجام می دهد (اگر 20٪ مشاهدات داده های tarin را زنان تشکیل دهند، DummyClassifier زنان را 20٪ از تعداد پیش بینی می کند). دوم، uniform به طور تصادفی بین طبقات مختلف پیش بینی ها را ایجاد می کند. مثلا، اگر 20٪ مشاهدات زنان و 80٪ مرد باشد، uniform پیش بینی هایی را ایجاد می کند که 50٪ زن و 50٪ مرد است.
ارزیابی پیش بینی های طبقه بندی باینری
چگونگی ارزیابی کیفیت یک مدل طبقه بندی train شده:
در کتابخانه scikit-learn ازcross_val_score برای ایجاد cross-validation استفاده می کنیم. پارامتر scoring برای تعریف یکی از معیارهای عملکرد، از جمله accuracy، percision، recall و F1 می باشد.
Accuracy یا دقت یک معیار رایج عملکرد است که نسبت مشاهداتی است که به درستی پیش بینی شده است:
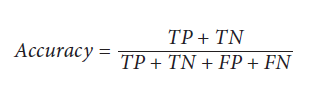
TP تعداد true positives می باشد. مشاهداتی که بخشی از کلاس positive هستند (بیماری دارد، محصول را خریداری کرده و… ) و ما درست پیش بینی کرده ایم.
TN تعداد true negatives می باشد. مشاهداتی که بخشی از کلاس negative هستند (بیماری ندارد، محصول را خریداری نکرده و… ) و ما درست پیش بینی کرده ایم.
FP تعداد false positives می باشد. خطای نوع I نیز نامیده می شود. مشاهدات پیش بینی شده اند که بخشی از کلاس positive باشند ولی در واقعیت بخشی از کلاس negative هستند.
FN تعداد false negatives می باشد. خطای نوع II نیز نامیده می شود. مشاهدات پیش بینی شده اند که بخشی از کلاس negative باشند ولی در واقع بخشی از کلاس positive هستند.
با قرار دادن scoring=”accuracy” در cross-validation میتوانیم دقت را اندازه گیره کنیم:
# Load libraries from sklearn.model_selection import cross_val_score from sklearn.linear_model import LogisticRegression from sklearn.datasets import make_classification # Generate features matrix and target vector X, y = make_classification(n_samples = 10000, n_features = 3, n_informative = 3, n_redundant = 0, n_classes = 2, random_state = 1) # Create logistic regression logit = LogisticRegression() # Cross-validate model using accuracy cross_val_score(logit, X, y, scoring="accuracy") array([ 0.95170966, 0.9580084 , 0.95558223])
با قرار دادن scoring=”accuracy” در cross-validation میتوانیم دقت را اندازه گیره کنیم:
خوبی دقت به دست آوردن این است که یک توضیح ساده دارد: نسبت مشاهدات به درستی پیش بینی شده است. با این حال، در دنیای واقعی، غالباً داده های ما دارای کلاس های نامتعادل هستند (به عنوان مثال ، 99.9٪ مشاهدات از کلاس 1 و فقط 0.1٪ از کلاس 2 هستند). هنگامی که کلاس های نامتعادل وجود دارد، دقت دچار پارادوکس می شود که در آن یک مدل بسیار دقیق است اما فاقد قدرت پیش بینی است. به عنوان مثال، تصور کنید که برای پیش بینی وجود یک سرطان بسیار نادر هستیم که در 0.1٪ از جمعیت اتفاق می افتد. پس از آموزش مدل خود، متوجه می شویم که دقت 95٪ است. در حالی که، 99.9٪ افراد مبتلا به سرطان نیستند: اگر ما به سادگی مدلی ایجاد کنیم که “پیش بینی” کند که هیچ کس سرطان ندارد، مدل ساده و اشتباه ما 4.9٪ دقیق تر است، اما در واقع قادر به پیش بینی چیزی نیست. به همین دلیل، ما اغلب ما مجبور به استفاده از معیارهای دیگر مانند precision، recall و F1-score هستیم.
Precision نسبت هر مشاهده ای است که positive پیش بینی شده است و در واقعیت هم positive است. می توانیم به عنوان یک نویز اندازه گیری در پیش بینی های خود در نظر بگیریم – یعنی وقتی پیش بینی می کنیم چیزی مثبت است، چقدر در مورد آن درست می گوییم. مدل هایی با Precision بالا بدبینانه از این نظر هستند که فقط درصورتی مشاهده را از کلاس مثبت پیش بینی می کنند که آن قطعا از کلاس مثبن می باشد. Precision عبارت است از:
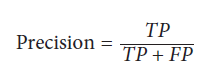
# Cross-validate model using precision cross_val_score(logit, X, y, scoring="precision") array([ 0.95252404, 0.96583282, 0.95558223])
recall نسبت هر مشاهده positive است که درست مثبت شده است. recall توانایی مدل را در شناسایی مشاهدات از کلاس مثبت اندازه گیری می کند. مدلهای دارای recall بالا از این جهت خوشبین هستند که نوار کمی برای پیش بینی مشاهده در کلاس مثبت دارند:
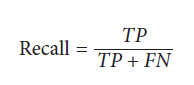
# Cross-validate model using recall cross_val_score(logit, X, y, scoring="recall") array([ 0.95080984, 0.94961008, 0.95558223])
اگر اولین باری است که با percision و recall روبرو می شوید، درک کامل آنها کمی زمان می برد. percision و recall کمتر شهودی است. تقریباً همیشه ما نوعی تعادل بین percision و ecall را می خواهیم و از F1-score استفاده می شود. F1-score میانگین هارمونیک است (نوعی میانگین استفاده شده برای نسبت ها):

این یک معیار صحت است که در پیش بینی مثبت بدست آمده است – یعنی مشاهداتی که با عنوان مثبت شناخته می شوند ، چند مورد واقعاً مثبت هستند:
# Cross-validate model using f1 cross_val_score(logit, X, y, scoring="f1") array([ 0.95166617, 0.95765275, 0.95558223])
به عنوان یک معیار ارزیابی، دقت یا accuracy دارای برخی از خصوصیات ارزشمند، به ویژه شهود ساده آن است. با این حال، معیارهای بهتر اغلب برای استفاده در برخی از توازنها percision و recall هستند – یعنی یک معامله بین خوش بینی و بدبینی مدل ما. F1 تعادل بین recall و percision را نشان می دهد، جایی که سهم و همکاری نسبی هر دو برابر است.
در صورت استفاده از cross_val_score ، اگر مقادیر y واقعی و مقادیر y پیش بینی شده داشته باشیم، می توان معیارها را مانند accuracy و recall را مستقیما محاسبه کرد:
Load library from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score # Create training and test split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=1) # Predict values for training target vector y_hat = logit.fit(X_train, y_train).predict(X_test) # Calculate accuracy accuracy_score(y_test, y_hat) 0.94699999999999995
ارزیابی آستانه های طبقه بندی باینری
چگونگی ارزیابی یک طبقه بندی باینری و آستانه های مختلف احتمال:
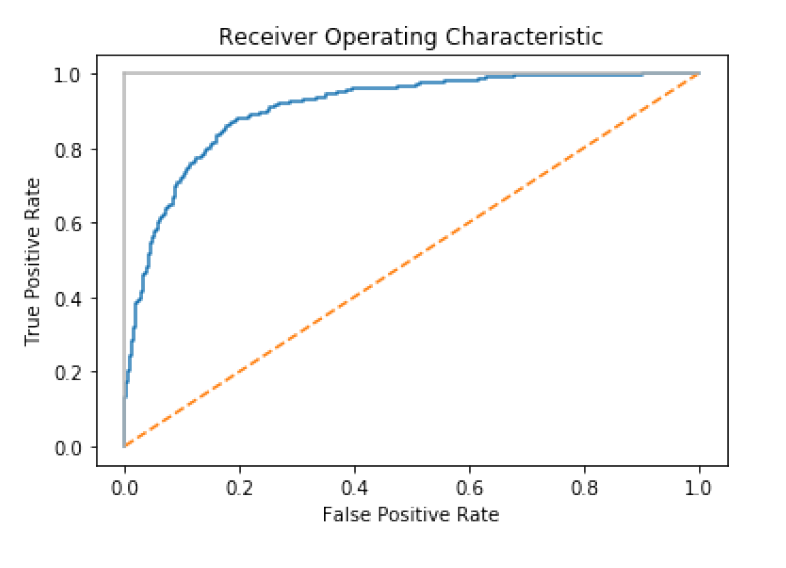
منحنی Receiving Operating Characteristic (ROC) یک روش معمول برای ارزیابی کیفیت طبقه بندی باینری است. ROC حضور true positives و false positives را در هر آستانه احتمال مقایسه می کند (احتمالی که یکی از مشاهدات طبق کلاس پیش بینی شده باشد). با ترسیم منحنی ROC می توان عملکرد مدل را مشاهده کرد. طبقه بندی کننده ای که هر مشاهده را به درستی پیش بینی می کند مانند خط خاکستری روشن در نمودار زیر به نظر می رسد، بلافاصله به سمت بالا می رود. طبقه بندی کننده ای که به طور تصادفی پیش بینی می کند به عنوان خط مورب ظاهر می شود. هرچه مدل بهتر باشد، به خط خاکستری نزدیکتر است. در scikit-learn، می توانیم از roc_curve برای محاسبه درست و غلط positive در هر آستانه استفاده کنیم، سپس آنها را رسم کنیم:
# Load libraries
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_curve, roc_auc_score
from sklearn.model_selection import train_test_split
# Create feature matrix and target vector
features, target = make_classification(n_samples=10000,
n_features=10,
n_classes=2,
n_informative=3,
random_state=3)
# Split into training and test sets
features_train, features_test, target_train, target_test = train_test_split(
features, target, test_size=0.1, random_state=1)
# Create classifier
logit = LogisticRegression()
# Train model
logit.fit(features_train, target_train)
# Get predicted probabilities
target_probabilities = logit.predict_proba(features_test)[:,1]
# Create true and false positive rates
false_positive_rate, true_positive_rate, threshold = roc_curve(target_test,
target_probabilities)
# Plot ROC curve
plt.title("Receiver Operating Characteristic")
plt.plot(false_positive_rate, true_positive_rate)
plt.plot([0, 1], ls="--")
plt.plot([0, 0], [1, 0] , c=".7"), plt.plot([1, 1] , c=".7")
plt.ylabel("True Positive Rate")
plt.xlabel("False Positive Rate")
plt.show()
تاکنون ما فقط مدل ها را بر اساس مقادیر پیش بینی شده بررسی کرده ایم. با این حال، در بسیاری از الگوریتم های یادگیری، آن مقادیر پیش بینی شده بر اساس تخمین احتمالات نیستند. یعنی به هر مشاهده احتمالاً تعلق خاطر در هر کلاس داده می شود. در روش زیر، می توانیم از predict_proba برای دیدن احتمالات پیش بینی شده برای اولین مشاهده استفاده کنیم:
# Get predicted probabilities logit.predict_proba(features_test)[0:1] array([[ 0.8688938, 0.1311062]])
با استفاده از classes_ می توان کلاس ها را مشاهده کرد:
logit.classes_ array([0, 1])
در این مثال، اولین مشاهده %87 ~ احتمال حضور در کلاس منفی (0) و 13٪ احتمال حضور در کلاس مثبت (1) را دارد. به طور پیش فرض، scikit-learn اگر یک احتمال بیشتر از 0.5 باشد (که thresholdنامیده می شود) مشاهده بخشی از کلاس مثبت است را پیش بینی می کند. با این حال، به جای یک راه میانه، اغلب ما می خواهیم مدل خود را جهت استفاده از آستانه دیگری به دلایل اساسی مغرضانه کنیم. به عنوان مثال، اگر یک مثبت کاذب برای شرکت ما بسیار پرهزینه است، ممکن است ما مدلی را ترجیح دهیم که آستانه احتمال آن زیاد باشد. ما نمی توانیم برخی از نکات مثبت را پیش بینی کنیم، اما وقتی یک مشاهده مثبت پیش بینی می شود، می توانیم از صحت پیش بینی اطمینان داشته باشیم. این معامله در نرخ مثبت واقعی true positive rate (TPR) و نرخ مثبت کاذب false positive rate (FPR) نشان داده می شود. true positive rate تعداد مشاهدات درست پیش بینی شده تقسیم بر تمام مشاهدات مثبت مثبت است:
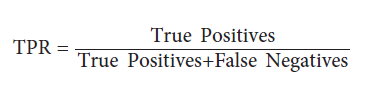
false positive rate، تعداد مثبت نادرست پیش بینی شده تقسیم بر تمام مشاهدات منفی واقعی و درست است:
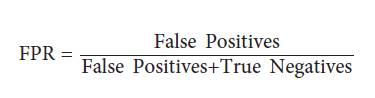
منحنی ROC نمایانگر TPR و FPR مربوط به هر آستانه احتمال است. به عنوان مثال ، در محلول ما آستانه تقریباً 0.50 دارای TPR برابر 0.81 و FPR برابر 0.15 است:
print("Threshold:", threshold[116])
print("True Positive Rate:", true_positive_rate[116])
print("False Positive Rate:", false_positive_rate[116])
Threshold: 0.528224777887
True Positive Rate: 0.810204081633
False Positive Rate: 0.154901960784
اگر ما آستانه را به 80 ~ افزایش دهیم (مثلا، قبل از پیش بینی مشاهده مثبت بودن مدل، میزان اطمینان را افزایش دهیم) TPR به طور قابل توجهی کاهش می یابد، اما FPR نیز کاهش می یابد:
print("Threshold:", threshold[45])
print("True Positive Rate:", true_positive_rate[45])
print("False Positive Rate:", false_positive_rate[45])
Threshold: 0.808019566563
True Positive Rate: 0.563265306122
False Positive Rate: 0.0470588235294
این بدان دلیل است که نیاز بالاتر ما برای پیش بینی در کلاس مثبت باعث شده است که این مدل تعدادی از مشاهدات مثبت (TPR پایین) را شناسایی نکند، اما همچنین باعث کاهش نویز حاصل از مشاهدات منفی شود که به عنوان مثبت پیش بینی می شوند (FPR پایین).
منحنی ROC علاوه بر اینکه می تواند معامله بین TPR و FPR را تجسم کند، می تواند به عنوان یک معیار کلی برای یک مدل نیز استفاده شود. هرچه مدل بهتر باشد، منحنی بالاتر است و در نتیجه سطح زیر منحنی بیشتر است. به همین دلیل، محاسبه سطح زیر منحنی ROC (AUCROC) برای قضاوت در مورد برابری کلی یک مدل در تمام آستانه های ممکن، معمول است. هرچه AUCROC به 1 نزدیکتر باشد ، مدل بهتر است. در scikit-learn ما می توانیم AUCROC را با استفاده از roc_auc_score محاسبه کنیم:
# Calculate area under curve roc_auc_score(target_test, target_probabilities) 0.90733893557422962
ارزیابی پیش بینی های طبقه بندی چند کلاسه
چگونگی ارزیابی عملکرد مدلی که سه کلاس یا بیشتر دارد:
از cross-validation با معیار ارزیابی که قادر به اداره بیش از دو کلاس است، استفاده می کنیم.
# Load libraries from sklearn.model_selection import cross_val_score from sklearn.linear_model import LogisticRegression from sklearn.datasets import make_classification # Generate features matrix and target vector features, target = make_classification(n_samples = 10000, n_features = 3, n_informative = 3, n_redundant = 0, n_classes = 3, random_state = 1) # Create logistic regression logit = LogisticRegression() # Cross-validate model using accuracy cross_val_score(logit, features, target, scoring='accuracy') array([ 0.83653269, 0.8259826 , 0.81308131])
وقتی کلاسهای متعادلی داریم (یعنی تعداد مشاهدات تقریباً برابر در هر کلاس از بردارهای هدف)، دقت، درست مانند مدل کلاس باینری، یک انتخاب ساده و قابل تفسیر برای یک معیار ارزیابی است. دقت، تعداد پیش بینی های صحیح، تقسیم بر تعداد مشاهدات است و در چند کلاسه همانند مدل باینری عمل می کند. با این حال، وقتی کلاسهای نامتعادل داریم، باید تمایل به استفاده از سایر معیارهای ارزیابی داشته باشیم.
بسیاری از معیارهای scikit-leaen برای ارزیابی طبقه بندی باینری است. اما، وقتی بیش از دو کلاس داشته باشیم بسیاری از این معیارها قابل استفاده هستند. Precision,، recall و F1-score معیارهای مفیدی هستند که قبلاً به تفضیل توضیح داده ایم. در حالی که در اصل همه آن ها برای طبقه بندی باینری طراحی شده اند، ولی ما می توانیم آنها را در تنظیمات چند کلاسه اعمال کنیم و داده های خود را به عنوان مجموعه ای از کلاس های باینری در نظر بگیریم. با انجام این کار می توان معیارها را برای هر کلاس به کار برد به گونه ای که گویی تنها کلاس موجود در داده ها است و سپس با میانگین گیری از آنها، ارزیابی را برای همه کلاس ها جمع کرد:
# Cross-validate model using macro averaged F1 score cross_val_score(logit, features, target, scoring='f1_macro') array([ 0.83613125, 0.82562258, 0.81293539])
در این کد، _macro به روشی که برای میانگین نمرات ارزیابی از کلاسها استفاده می شود اشاره دارد:
marco = اندازه میانگین نمرات را برای هر کلاس محاسبه می کند و هر کلاس را به طور مساوی وزن می کند.
weighted = محاسبه میانگین نمرات برای هر کلاس را محاسبه می کند و هر کلاس را متناسب با اندازه آن در داده ها وزن می کند.
micro = میانگین نمرات را برای هر ترکیب مشاهدات کلاس محاسبه می کند.
تجسم عملکرد طبقه بندی کننده
چگونگی مقایسه کیفیت مدل از نظر بصری با توجه به کلاسهای پیش بینی شده و کلاسهای واقعی داده های آزمون:
از یک ماتریس سردرگمی confusion matrix استفاده می کنیم، که کلاسهای پیش بینی شده و کلاسهای واقعی را با هم مقایسه می کند.
# Load libraries
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
import pandas as pd
# Load data
iris = datasets.load_iris()
# Create feature matrix
features = iris.data
# Create target vector
target = iris.target
# Create list of target class names
class_names = iris.target_names
# Create training and test set
features_train, features_test, target_train, target_test = train_test_split(
features, target, random_state=1)
# Create logistic regression
classifier = LogisticRegression()
# Train model and make predictions
target_predicted = classifier.fit(features_train,
target_train).predict(features_test)
# Create confusion matrix
matrix = confusion_matrix(target_test, target_predicted)
# Create pandas dataframe
dataframe = pd.DataFrame(matrix, index=class_names, columns=class_names)
# Create heatmap
sns.heatmap(dataframe, annot=True, cbar=None, cmap="Blues")
plt.title("Confusion Matrix"), plt.tight_layout()
plt.ylabel("True Class"), plt.xlabel("Predicted Class")
plt.show()
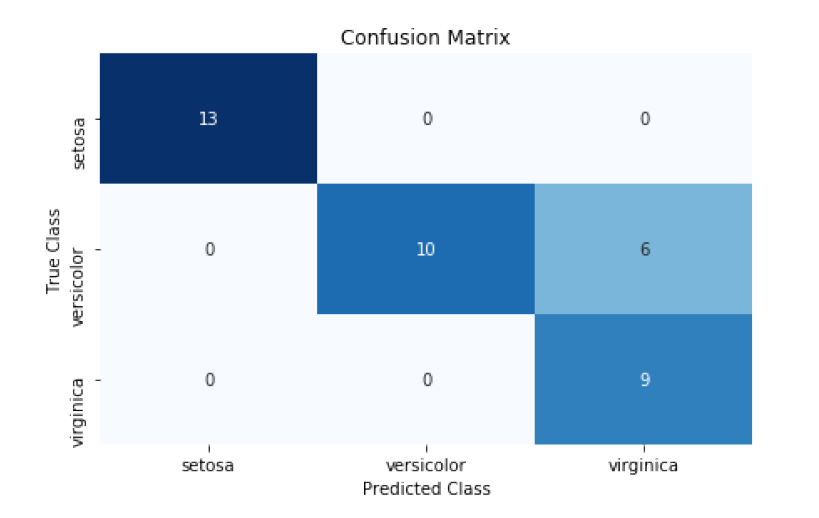
ماتریس های سردرگمی تجسم آسان و موثرعملکرد طبقه بندی کننده است. یکی از مهمترین مزایای ماتریس های سردرگمی تفسیرپذیری آنهاست. هر ستون از کلاس های پیش بینی شده را نشان می دهد، در حالی که هر سطر کلاس های واقعی را نشان می دهد. نتیجه نهایی این است که هر سلول یک ترکیب ممکن از کلاس های پیش بینی و واقعی است. به عنوان مثال، سلول سمت چپ بالا تعداد مشاهداتی است که پیش بینی می شود Iris setosa باشد (با ستون نشان داده می شود) که در واقع هم Iris setosa است (با ردیف نشان داده می شود). این بدان معنی است که مدل ها تمام گلهای Iris setosa را به طور دقیق پیش بینی کرده اند. با این حال، مدل در پیش بینی Iris virginica عملکرد خوبی ندارد. سلول سمت راست پایین نشان می دهد که مدل با موفقیت 9 مشاهدات Iris virginica را پیش بینی کرده، اما (سلول سمت بالا) شش گل viriginica را که در واقع Iris versicolor بودند، می باشد.
در مورد ماتریس های سردرگمی سه نکته وجود دارد: اول، یک مدل عالی در هر جای دیگر دارای مقادیری در امتداد مورب و صفر خواهد بود. یک مدل بد به نظر می رسد تعداد مشاهده به طور مساوی در اطراف سلول ها پخش می شود. دوم، یک ماتریس سردرگمی نشان می دهد که نه تنها در کجای مدل اشتباه بود، بلکه همچنین نحوه اشتباه آن را نیز می توانیم ببینیم. یعنی می توانیم الگوهای طبقه بندی غلط را بررسی کنیم. به عنوان مثال، مدل ما زمان تمایز بین Iris virginica و Iris setosa بسیار آسان بود، اما طبقه بندی Iris virginica و Iris versicolor بسیار دشوارتر بود. در آخر، ماتریس های سردرگمی با هر تعداد کلاس کار می کنند (اگرچه اگر یک میلیون کلاس در بردار هدف خود داشته باشیم، خواندن تجسم ماتریس سردرگمی ممکن است دشوار باشد).
ارزیابی مدل های رگرسیون
چگونگی ارزیابی عملکرد یک مدل رگرسیون:
از روش خطای مربع میانگین یا mean squared error (MSE) استفاده می کنیم.
# Load libraries from sklearn.datasets import make_regression from sklearn.model_selection import cross_val_score from sklearn.linear_model import LinearRegression # Generate features matrix, target vector features, target = make_regression(n_samples = 100, n_features = 3, n_informative = 3, n_targets = 1, noise = 50, coef = False, random_state = 1) # Create a linear regression object ols = LinearRegression() # Cross-validate the linear regression using (negative) MSE cross_val_score(ols, features, target, scoring='neg_mean_squared_error') array([-1718.22817783, -3103.4124284 , -1377.17858823])
یکی دیگر از معیارهای متداول رگرسیون ضریب تعیین، R2 است:
# Cross-validate the linear regression using R-squared cross_val_score(ols, features, target, scoring='r2') array([ 0.87804558, 0.76395862, 0.89154377])
MSE یکی از رایج ترین معیارهای ارزیابی مدل های رگرسیون است. MSE به شرح زیر است:
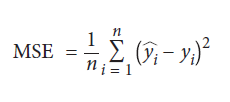
n تعداد مشاهدات است، yi مقدار واقعی هدف یا targetی است که می خواهیم برای داده ی iام پیش بینی کنیم، و yi مقدار پیش بینی شده مدل برای yi است. MSE اندازه گیری مجموع مربع تمام فواصل بین مقادیر پیش بینی شده و واقعی است. هرچه مقدار MSE بیشتر باشد، کل خطای مربع بیشتر خواهد بود و بنابراین مدل بدتر می شود. مجذور اصطلاح خطا چندین مزیت ریاضی دارد، از جمله اینکه تمام مقادیر خطا را مجبور می کند مثبت باشند، اما یک مسئله غیرقابل تحقق این است که مجذور چند خطای بزرگ را بیش از بسیاری از خطاهای کوچک جریمه می کند، حتی اگر مقدار مطلق آن باشد خطاها همان است. به عنوان مثال، دو مدل A و B را تصور کنید، هر کدام با دو مشاهده:
مدل A دارای خطاهای 0 و 10 است و بنابراین MSE آن 100 + 102 = 02 است.
مدل B هر کدام دو خطای 5 دارد و بنابراین MSE آن 52 + 52 = 52 است.
خطای کلی هر دو مدل یکسان است، 10؛ اما، MSE مدل A (MSE = 100) را بدتر از مدل B (MSE = 50) می داند. در عمل و از نظر تئوریک نیز می تواند مفید باشد و MSE به عنوان یک معیار ارزیابی کاملا خوب عمل می کند.
یک نکته مهم: به طور پیش فرض در استدلال های scikit-learn از پارامتر scoring فرض می کند که مقادیر بالاتر بهتر از مقادیر پایین هستند. با این حال، این مورد در MSE صدق نمی کند، چون مقادیر بالاتر به معنی بدتر بودن مدل است. به همین دلیل، scikit-learn با استفاده از استدلال neg_mean_squared_error به MSE منفی نگاه می کند.
متغیر ارزیابی رگرسیون متناوب، R2 است که مقدار واریانس در بردار هدف را اندازه گیری می کند که توسط مدل توضیح داده شده است:
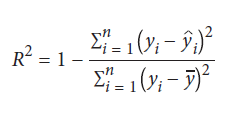
جایی که yi مقدار هدف واقعی مشاهده iام است، yi مقدار پیش بینی شده مشاهدات iام است و y مقدار میانگین بردار هدف است. هرچه به 1.0 نزدیکتر باشد، مدل بهتر است.
ارزیابی مدلهای خوشه بندی
چگونگی ارزیابی عملکرد یک الگوریتم یادگیری بدون نظارت برای خوشه بندی داده:
پاسخ کوتاه این است که شما احتمالاً نمی توانید ، حداقل نه به روشی که می خواهید.
همانطور که گفته شد، یک گزینه ارزیابی خوشه بندی با استفاده از عامل مشترک شبح است که کیفیت خوشه ها را اندازه گیری می کند:
import numpy as np from sklearn.metrics import silhouette_score from sklearn import datasets from sklearn.cluster import KMeans from sklearn.datasets import make_blobs # Generate feature matrix features, _ = make_blobs(n_samples = 1000, n_features = 10, centers = 2, cluster_std = 0.5, shuffle = True, random_state = 1) # Cluster data using k-means to predict classes model = KMeans(n_clusters=2, random_state=1).fit(features) # Get predicted classes target_predicted = model.labels_ # Evaluate model silhouette_score(features, target_predicted) 0.89162655640721422
ارزیابی مدل های با نظارت (مثالا، کلاس ها یا مقادیر کمی)، پیش بینی ها را با مقادیر واقعی مربوطه در بردار هدف مقایسه می کند. با این حال، اکثرا دلیل استفاده از روش های خوشه بندی این است که داده های شما بردار هدف ندارند. تعدادی از معیارهای ارزیابی خوشه بندی وجود دارد که به یک بردار هدف نیاز دارد، اما باز هم، استفاده از رویکردهای یادگیری بدون نظارت مانند خوشه بندی هنگامی که یک بردار هدف در دسترس دارید، احتمالا لازم نیست.
اگر بردار هدف نداشته باشیم، نمی توانیم پیش بینی ها را در مقابل مقادیر واقعی ارزیابی کنیم، اما می توانیم ماهیت خوشه ها را ارزیابی کنیم. می توان تصور کرد که خوشه های “خوب” فاصله بسیار کمی بین مشاهدات در یک خوشه (خوشه های متراکم) و فاصله زیاد بین خوشه های مختلف (خوشه های کاملاً تفکیک شده) داشته باشند. ضرایب شبح یک مقدار واحد برای اندازه گیری هر دو صفت فراهم می کنند. ضریب شبح مشاهده مشاهده است:
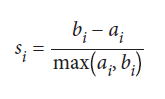
si ضریب شبح برای مشاهده i است، ai میانگین فاصله بین i و تمام مشاهدات یک کلاس است و bi میانگین فاصله بین i و تمام مشاهدات از نزدیکترین خوشه یک کلاس متفاوت است. مقداری که توسط silhouette_score برگردانده می شود میانگین ضریب شبح برای همه مشاهدات است. ضرایب شبح بین -1 و 1 است، که 1 نشانگر خوشه های متراکم و کاملاً جدا است.
ایجاد اندازه های ارزیابی به صورت سفارشی
چگونگی ارزیابی یک مدل با استفاده از معیاری که ایجاد کرده اید:
معیار را به عنوان یک تابع ایجاد کرده و با استفاده از make_scorer در scikit-learn آن را به یک تابع امتیاز دهنده تبدیل می کنیم.
# Load libraries from sklearn.metrics import make_scorer, r2_score from sklearn.model_selection import train_test_split from sklearn.linear_model import Ridge from sklearn.datasets import make_regression # Generate features matrix and target vector features, target = make_regression(n_samples = 100, n_features = 3, random_state = 1) # Create training set and test set features_train, features_test, target_train, target_test = train_test_split( features, target, test_size=0.10, random_state=1) # Create custom metric def custom_metric(target_test, target_predicted): # Calculate r-squared score r2 = r2_score(target_test, target_predicted) # Return r-squared score return r2 # Make scorer and define that higher scores are better score = make_scorer(custom_metric, greater_is_better=True) # Create ridge regression object classifier = Ridge() # Train ridge regression model model = classifier.fit(features_train, target_train) # Apply custom scorer score(model, features_test, target_test) 0.99979061028820582
در حالی که scikit-learn تعدادی معیار داخلی برای ارزیابی عملکرد مدل دارد، اما تعریف معیارهای خودمان اغلب مفید است. scikit-learn با استفاده از make_scorer این کار را آسان می کند. ابتدا، تابعی را تعریف می کنیم که دو استدلال – بردار هدف و مقادیر پیش بینی شده – را در بر می گیرد و دارای مقداری امتیاز است. دوم، ما از make_scorer برای ایجاد یک شی استفاده می کنیم و مطمئن می شویم که آیا نمرات بالاتر یا پایین تر مورد نظر هستند (با استفاده از پارامتر greater_is_better).
اندازه های سفارشی در این راه حل (custom_metric) مثل اسباب بازی است زیرا به سادگی یک اندازه داخلی را برای محاسبه R2 انجام می دهد. در واقعیت، ما می توانیم تابع custom_metric را با هر اندازه سفارشی که می خواهیم جایگزین کنیم. با این وجود، می توان دریافت که معیار سفارشی محاسبه R2 با مقایسه نتایج با روش داخلی r2_score در scikit-learn کار می کند:
# Predict values target_predicted = model.predict(features_test) # Calculate r-squared score r2_score(target_test, target_predicted) 0.99979061028820582
تجسم تأثیر اندازه مجموعه داده های آموزشی
چگونگی ارزیابی تأثیر تعداد مشاهدات موجود در مجموعه داده های آموزشی بر روی برخی از معیارها (مثل دقت، F1 و… ):
نمودار منحنی یادگیری را ترسیم می کنیم.
# Load libraries
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_digits
from sklearn.model_selection import learning_curve
# Load data
digits = load_digits()
# Create feature matrix and target vector
features, target = digits.data, digits.target
# Create CV training and test scores for various training set sizes
train_sizes, train_scores, test_scores = learning_curve(# Classifier
RandomForestClassifier(),
# Feature matrix
features,
# Target vector
target,
# Number of folds
cv=10,
# Performance metric
scoring='accuracy',
# Use all computer cores
n_jobs=-1,
# Sizes of 50
# training set
train_sizes=np.linspace(
0.01,
1.0,
50))
# Create means and standard deviations of training set scores
train_mean = np.mean(train_scores, axis=1)
train_std = np.std(train_scores, axis=1)
# Create means and standard deviations of test set scores
test_mean = np.mean(test_scores, axis=1)
test_std = np.std(test_scores, axis=1)
# Draw lines
plt.plot(train_sizes, train_mean, '--', color="#111111", label="Training score")
plt.plot(train_sizes, test_mean, color="#111111", label="Cross-validation score")
# Draw bands
plt.fill_between(train_sizes, train_mean - train_std,
train_mean + train_std, color="#DDDDDD")
plt.fill_between(train_sizes, test_mean - test_std,
test_mean + test_std, color="#DDDDDD")
# Create plot
plt.title("Learning Curve")
plt.xlabel("Training Set Size"), plt.ylabel("Accuracy Score"),
plt.legend(loc="best")
plt.tight_layout()
plt.show()
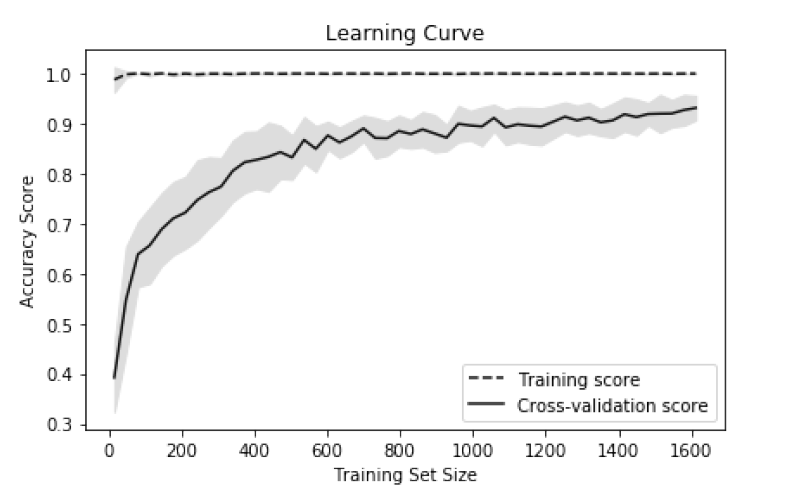
منحنی های یادگیری عملکرد یک مدل (مثل دقت، recall) را روی مجموعه آموزشی و در هنگام cross-validation با افزایش تعداد مشاهدات در مجموعه آموزش، تصویر سازی می کنند. آنها معمولاً برای تعیین اینکه الگوریتم های یادگیری ما از جمع آوری اطلاعات آموزشی اضافی سود می برند، استفاده می شوند.
در مسئله ما، دقت طبقه بندی random forest را در 50 اندازه مجموعه آموزشی مختلف از 1٪ مشاهدات تا 100٪ ترسیم می کنیم. دقت فزاینده مدل های متقابل تأیید شده به ما می گوید که ما احتمالاً از مشاهدات اضافی بهره مند خواهیم شد (اگرچه در عمل این امکان پذیر نیست).
ایجاد یک گزارش متنی از معیارهای ارزیابی
چگونگی داشتن یک شرح سریع از عملکرد طبقه بندی کننده:
از classification_report در scikit-learn استفاده می کنیم.
# Load libraries from sklearn import datasets from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report # Load data iris = datasets.load_iris() # Create feature matrix features = iris.data # Create target vector target = iris.target # Create list of target class names class_names = iris.target_names # Create training and test set features_train, features_test, target_train, target_test = train_test_split( features, target, random_state=1) # Create logistic regression classifier = LogisticRegression() # Train model and make predictions model = classifier.fit(features_train, target_train) target_predicted = model.predict(features_test) # Create a classification report print(classification_report(target_test, target_predicted, target_names=class_names)) precision recall f1-score support setosa 1.00 1.00 1.00 13 versicolor 1.00 0.62 0.77 16 virginica 0.60 1.00 0.75 9 avg / total 0.91 0.84 0.84 38
classification_report یک روش سریع برای دیدن برخی معیارهای ارزیابی رایج، از جمله precision، recall و score F1 فراهم می کند. support به تعداد مشاهدات در هر کلاس اشاره دارد.
تصویر سازی تأثیر مقادیر Hyperparameter
چگونگی تغییر عملکرد مدل، با تغییر مقدار برخی از ابر پارامترها:
منحنی اعتبار سنجی را رسم می کنیم.
# Load libraries
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_digits
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import validation_curve
# Load data
digits = load_digits()
# Create feature matrix and target vector
features, target = digits.data, digits.target
# Create range of values for parameter
param_range = np.arange(1, 250, 2)
# Calculate accuracy on training and test set using range of parameter values
train_scores, test_scores = validation_curve(
# Classifier
RandomForestClassifier(),
# Feature matrix
features,
# Target vector
target,
# Hyperparameter to examine
param_name="n_estimators",
# Range of hyperparameter's values
param_range=param_range,
# Number of folds
cv=3,
# Performance metric
scoring="accuracy",
# Use all computer cores
n_jobs=-1)
# Calculate mean and standard deviation for training set scores
train_mean = np.mean(train_scores, axis=1)
train_std = np.std(train_scores, axis=1)
# Calculate mean and standard deviation for test set scores
test_mean = np.mean(test_scores, axis=1)
test_std = np.std(test_scores, axis=1)
# Plot mean accuracy scores for training and test sets
plt.plot(param_range, train_mean, label="Training score", color="black")
plt.plot(param_range, test_mean, label="Cross-validation score", color="dimgrey")
# Plot accurancy bands for training and test sets
plt.fill_between(param_range, train_mean - train_std,
train_mean + train_std, color="gray")
plt.fill_between(param_range, test_mean - test_std,
test_mean + test_std, color="gainsboro")
# Create plot
plt.title("Validation Curve With Random Forest")
plt.xlabel("Number Of Trees")
plt.ylabel("Accuracy Score")
plt.tight_layout()
plt.legend(loc="best")
plt.show()
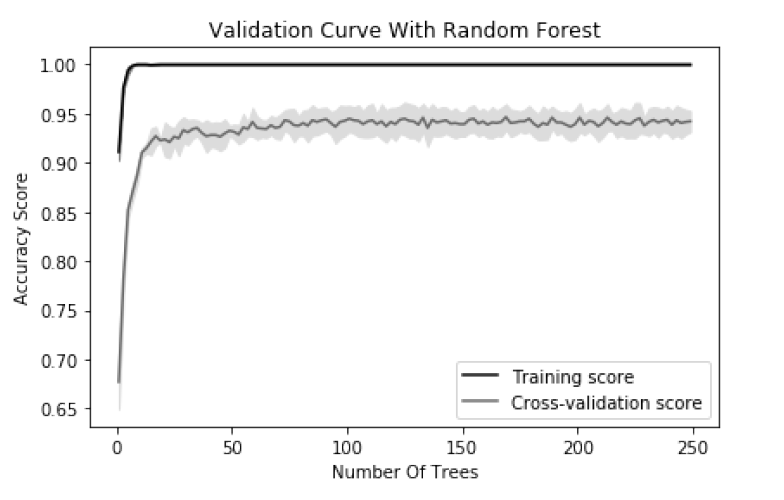
اکثر الگوریتم های آموزشی (که جلوتر بسیاری از آن ها بررسی می شود) حاوی ابر پارامترهایی هستند که باید قبل از شروع روند آموزش انتخاب شوند. به عنوان مثال، یک طبقه بندی کننده random forest یا جنگل تصادفی “forest” یا جنگلی از درختان تصمیم گیری ایجاد می کند، که هر یک از آنها به کلاس پیش بینی شده یک رأی می دهند. یک ابر پارامتر در طبقه بندی کننده های random forest تعداد درختان در جنگل است. اغلب مقادیر ابرپارامتر در هنگام انتخاب مدل انتخاب می شوند. با این حال، گاهی اوقات مفید است که با تغییر مقدار hyperparameter، تغییرعملکرد مدل را ببینیم. در مسئله ما، تغییرات دقت را برای یک طبقه بندی کننده randm forest برای مجموعه آموزشی و در طول cross-validation با افزایش تعداد درختان ترسیم می کنیم. وقتی تعداد کمی درخت داریم، دقت مجموعه آموزش و cross-validation هم پایین است و این نشان می دهد که مدل از کمبودی برخوردار است. همانطور که تعداد درختان به 250 مورد افزایش می یابد، دقت هر دو سطح خاموش است، که نشان می دهد احتمالاً ارزش زیادی در هزینه محاسباتی آموزش یک جنگل عظیم وجود ندارد.
در scikit-learn، ما می توانیم منحنی اعتبار سنجی یا validation را با استفاده از validation_curve محاسبه کنیم، که شامل سه پارامتر مهم است:
• param_name نام ابر پارامتر است که می تواند متفاوت باشد.
• param_range مقدار ابرپارامتر که مورد استفاده قرار می گیرد.
• scoring معیار ارزیابی است که برای داوری برای مدل سازی استفاده می شود.
خب تا به این جا با اکثر معیارهای ارزیابی آشنا شدیم، ما باید درک کنیم که چگونه یک مدل یادگیری ماشین را ارزیابی کنیم. این یکی از وظایف اصلی در گردش کار یادگیری ماشین است و پیش بینی و برنامه ریزی برای موفقیت یک مدل در تولید می تواند یک کار دلهره آور باشد.