


بیایید یک نمونه تصادفی 500 تایی از این داده ها بگیریم. این به سرعت بخشیدن به آموزش و آزمون مدل (model training and testing) کمک می کند ، به راحتی می توانید ایم مقدار را تغییر دهید:
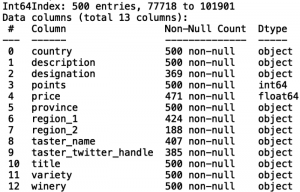
چندین ستون کمتر از 500 مقدار غیر تهی دارند که با مقادیر مفقود شده مطابقت می کند. ابتدا بیایید ساختن مدلی را که مقادیر “قیمت (price)” گم شده را با استفاده از “امتیاز (points)” جایگزاری می کند را در نظر بگیریم. برای شروع ، بیایید همبستگی (correlation) بین “قیمت” و “امتیاز” را چاپ کنیم:
![]()
می بینیم که همبستگی مثبت ضعیفی وجود دارد. بیایید یک مدل رگرسیون خطی (linear regression model) ایجاد کنیم که از “امتیاز” برای پیش بینی “قیمت” استفاده می کند. ابتدا ماژول “LinearRegresssion” را از “scikit-Learn” وارد می کنیم:
![]()
می بینیم که عملکرد خیلی عالی نیست. ما برای بهوبد می توانیم عملکرد را با آموزش در قیمت های محدود شده تا مرز میانگین قیمت به علاوه یک انحراف استاندارد بهبود ببخشیم:
![]()
![]()
می بینیم که مدل جنگل های تصادفی از عملکرد بسیار بهتری برخوردار است. اکنون ، می خواهیم مقادیر قیمت گمشده را با استفاده از مدل هایمان پیش بینی کنیم:
![]() در اینجا شما را تشویق می کنم که در انتخاب ویژگی ها و تنظیم پارامترها بیش از اندازه بازی کنید تا ببینید آیا می توانید عملکرد را بهبود ببخشید. بعلاوه ، من شما را تشویق می کنم که این الگو را گسترش دهید تا مقادیر گمشده را در متغیرهای کیفی از جمله “region_1” و “designation’” بدست آورید.
در اینجا شما را تشویق می کنم که در انتخاب ویژگی ها و تنظیم پارامترها بیش از اندازه بازی کنید تا ببینید آیا می توانید عملکرد را بهبود ببخشید. بعلاوه ، من شما را تشویق می کنم که این الگو را گسترش دهید تا مقادیر گمشده را در متغیرهای کیفی از جمله “region_1” و “designation’” بدست آورید.