
هدف از انجام این پروژه پیاده سازی و بهبود روش CondenseNet است که در مقاله معرفی شده است. به همین منظور در ابتدا اصل مقاله پیاده سازی شد و سپس روش جدیدی برای بهبود عملکرد آن ارایه شد. این پروژه در جز پروژه های پردازش تصویر طبقه بندی می شود.
برای پیاده سازی این پروژه با چالش های مختلفی روبرو بودیم. در ابتدا درک روش پیشنهادی و پیاده سازی آن به راحتی قابل انجام نبود. به این دلیل که روش نسبتا جدیدی ارایه شده بود و برای رسیدن به دقت اشاره شده در مقاله بایستی تمامی مراحل با جزیات رعایت می شد . چالش اصلی این پروژه بهبود عملکرد روش پیشنهادی بود. چون در این مقاله معماری جدیدی ارایه شده بود که دقتی بالا(بیش از ۹۰٪) بر روی مجموعه دادی cfar10 (سیفار 10) ارایه کرده بود. به همین دلیل رسیدن به دقتی بالاتر از دقت ارایه شده سخت ترین قسمت کار بود. که در نهایت با ترکیب روش ارایه شده در مقاله CondenseNet: An Efficient DenseNet using Learned Group Convolutions و روش یادگیری خود نظارتی توانسیتم به دقتی بالاتر برسیم.
این پروژه با زبان پایتون و فریم ورک pytorch نوشته شده است. pytorch دست ما را برای کار با داده های حجیم و تغییر ساختار در معماری Condensenet باز می گذارد. در ادامه خلاصه ای از ایده موجود در مقاله، روش پیشنهادی و نتایج بدست آمده ارایه می شود.
مدل Densnet
مدلهای شبکه عصبی به طور روز افزونی در موبایلها و سیستم های مختلفی که قدرت پردازش محدود تری دارند فراگیرمی شود. در این راستا در کنار دقت ،مدلهایی که بتوانند به نحوی تعداد پارامترهای این شبکه هارا کاهش دهند از اهمیت و جایگاه ویژه ای برخوردار شده اند.
دراین طرح پژوهشی به سراغ مدل CondeseNet خواهیم رفت که اگر بخواهیم به طور خلاصه به ویژگی های این مدل اشاره کنیم می توانیم بگوییم که در این مدل با به کارگیری دو مفهوم اتصالات متراکم(Dense layers) و گروه های یادگرفته شده کانولوشن ، تلاش شده است ساختار معروف densnet بهبود داده شود. اتصالات متراکم به کارگیری مجدد فیچر هادر شبکه را میسر میسازند در حالیکه که convolutions group learned اتصالاتی که در آن هابه کارگیری مجدد فیچرها ضرورتی ندارد ،را حذف می نماید.
همانطورکه بیان شد، مدل مورد بحث در این طرح پژوهشی بر اساس ساختار معروف Densnet توسعه یافته است. ویژگی منحصر به فرد Densnet معرفی بلوک های dense در ساختار شبکه عصبی می باشد.در نتیجه این امر ورودی مربوط به هر لایه در واقع مجموع فیچر مپ های تمام لایه های پیشین می باشد.( برای مشخص ترشدن ساختارdensnet به شکل زیر یک توجه کنید)
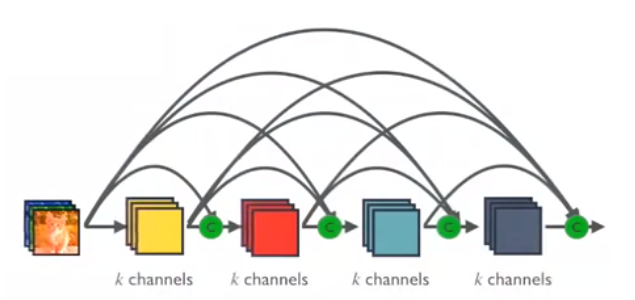
معرفی معماری Condensenet:
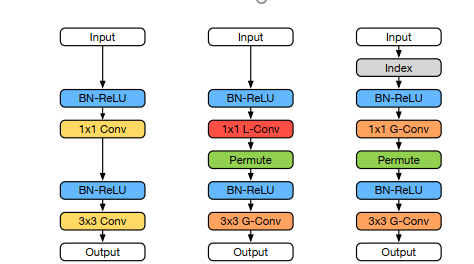
در مدل CondensNet که در این پژوهش مورد استفاده قرار گرفته است ساختار نسبت به Densnet تغییراتی نموده است. لازم به توجه است که مدل مد نظر ما از دو منظر نسبت به مدل اولیه تغییر نموده است. در وهله نخست ساختار هر بلوک dense تغییراتی نموده است که تغییر مربوط به هر بلوک از ساختار را میتوان در شکل شماره ۲ مشاهده نمود. علاوه بر تغییر ساختار هر بلوک به طور کلی ساختار شبکه که از کنار هم قرار گرفتن بلوکهای متعدد حاصل میشود نیز با تغییراتی همراه بوده است که این موضوع در شکل شماره 3 به بحث گذاشته شده است.
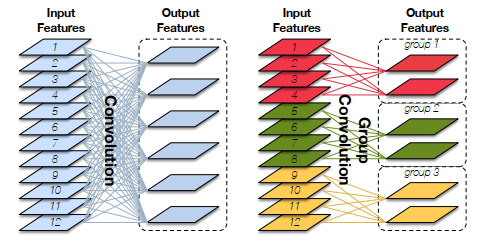
موضوع دیگری که در اینجا لازم است به آن اشاره داشته باشیم مبحث گروه کانولوشنهاست(Group Convolution) که در تصویر شماره 4 این موضوع نشان داده شده است. این ساختار که نخستین بار در مدل معروف AlexNet (الکس نت)به کارگرفته شده است میتواند تاثیر قابل ملاحظهای در کاهش هزینه محاسباتی یک مدل شبکه عصبی داشته باشد
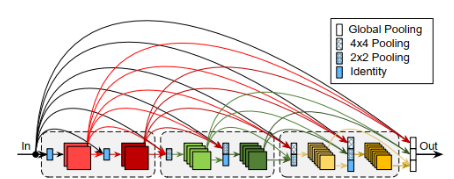
این ساختار دو تفاوت اصلی با ساختار Densnet دارد.نخست اینکه لایههایی که در آنها فیچر مپها رزولوشن متفاوت دارند نیز در این ساختار به یک دیگر متصل میشود. دوم تفاوت به این نکته باز میگردد که که نرخ رشد در این ساختار در مواقعی که سایز فیچر مپ کوچک میشود، دوبرابر خواهد شد.
در این بخش با کلیت روش condensnet و برخی از ایدههای کلی این روش که آنرا نسبت به روشهای پیشین متمایز میسازد آشنا شدیم. در ادامه با مروری بر کلیت روشهای یادگیری خود نظارتی به سراغ به کارگیری این روش در کنار مدل condensnet به منظور بهبود دقت خواهیم رفت.
یادگیری خود نظارتی
آشنایی با مفاهیم کلی
پروسه آموزش دادن شبکههای عصبی به تعداد زیادی دیتای لیبلدار نیازمند میباشد. ایده کلی روشهای خود نظارتی کاهش اتکا به دیتای لیبل دار در پروسه آموزش شبکه ها میباشد. اما چگونه میتوان بدون در اختیار داشتن دیتای دارای مشخصات از آن تصاویر جهت آموزش شبکهها استفاده نمود؟ راهکار روشهای خود نظارتی برای حل این مشکل تولید لیبل برای تصاویر بدون لیبل است. روشهای گوناگونی برای تولید لیبل قابل استفاده میباشند که برخی از آنها عبارتند از :
- Context Encoder
- Rotation Prediction
- SimCLR
- Using Representations for Downstream Tasks
بحث در رابطه با چگونگی کارکرد این روشها خارج از هدف گزارش فعلی است و در صورت لزوم میتوان به منابع مربوطه مراجعه نمود. در اینجا تمرکز خود را صرفا به روش پیشبینی زاویه دوران (مورد دوم ) متمرکز میکنیم. در این روش تصویر ورودی به ازای مقادیر مشخصی دوران داده میشود. (این مقادیر عموما برابر با ضرایب 90 درجه میباشند یعنی 0-90- 180-270) با توجه به اینکه دوران برابر با کدام یک از این مقادیر باشد یک لیبل به تصویر داده میشود که میتوان از این لیبل در آموزش شبکه استفاده نمود.
اما این لیبل چه کمکی میتواند به عملکرد بهتر در تسک مد نظر ما داشته باشد؟؟ چنانچه بتوانیم شبکه را به نحوی آموزش دهیم که بتواند تشخیص دهد تصویر چه میزان دوران نموده است در واقع داریم به لایههای شبکه خود آموزش میدهیم که با تشخیص فیچرهای مختلف مربوط به تصویر میزان دوران آن را پیش بینی بکند که این امر به معنای تقویت ساختار شبکه کانولوشن ما در استخراج فیچر از تصاویر میباشد که میتوانیم از آن به منظور بهبود دقت در تسک اصلی استفاده کنیم.
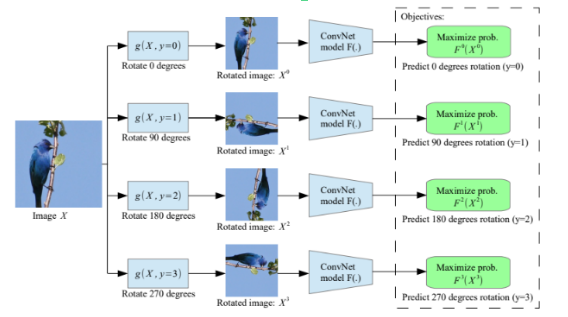
به کارگیری روش چرخش به عنوان تسک خودنظارتی در کنار تسک اصلی به دو صورت ممکن است. در حالت اول میتوانیم یک بار شبکه را کلا بر اساس لیبلهای مجازی که با استفاده از دوران تعریف کردهایم آموزش دهیم و بر اساس ضرایب به دست آمده از این روش، پروسه یادگیری مربوط به تسک اصلی را شروع کنیم. در حالت دوم میتوانیم پس از هر batch که در یادگیری تسک اصلی استفاده میشود، عملیات جانبی را نیز بر روی بخشی از دیتای مجازا لیبل دار شده انجام دهیم (در این پژوهش از روش دوم استفاده شده است که در قسمتهای بعدی به تشریح موضوع خواهیم پرداخت.)
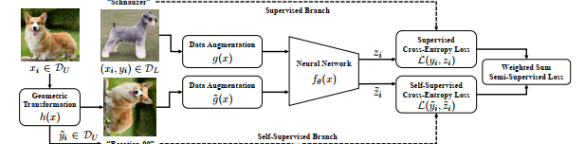
به کارگیری روش یادگیری خود نظارتی
تا اینجا با مفهوم و کارکرد روشهای مبتنی بر یادگیری خود نظارتی آشنا شدیم. مقاله مرجع مورد بررسی ما که از اینجا قابل دسترسی است، با به کارگیری ماهیت یادگیری سلف سوپروایزد، از آن به منظور رگولارایز کردن نتایج حاصل از آموزش شبکه استفاده نموده است. به عبارتی دیگر تلاش نموده است تا با دخیل کردن یک تسک سلف سوپروایزد در کنار یادگیری تسک اصلی، از اورفیت شدن شبکه بر روی تسک اصلی جلوگیری کند و به ما این امکان را بدهد که از آن شبکه نتیجه بهتری را در دیتای تست به دست آوریم.
بررسی نتایج
در وهله اول مدل condensnet به عنوان یک مدل که با تعداد پارامترهای بهینه شده میتواند به دقت مناسبی برسد را در نظر گرفتهایم. در گام نخست بدون استفاده از هیچ روش جانبی صرفا خود این مدل را بر روی دیتاست Ciafar10 پیاده سازی نمودیم. پارامترهای مهم دخیل در این پیاده سازی در جدول شماره 1 مشخص شدهاند.
| epoch | Lr_type | mometum | Learning rate | Batch size | دیتاست |
| 33 | cosine | 0.9 | 0.1 | 32 | Cifar 10 |
به منظور به کارگیری تسک خود نظارتی به عنوان عامل رگولایزر در کنار تسک اصلی نیاز به یک دیتاست دیگر داریم. بدین منظور می بایست به سراغ جمعآوری تصاویری متناسب با دیتاست cifa10 رفته و با برچسب زنی مجازی آنها، از تصاویر جدید استفاده نماییم. با توجه به اینکه در اینجا به طور کلی قصد بررسی کلیت ایده را داریم، به منظور انجام تسک سوپروایزد نیز مجددا از خود دیتاست cifar10 استفاده خواهیم نمود. با این تفاوت که در دیتاست فراخوانی شده در این تسک از تمام لیبلها صرف نظر میکنیم و لیبلهای مد نظر خود را به تصاویر الصاق میکنیم که همان زاویه دوران نسبت به وضعیت اولیه است. به منظور مقایسه بیشتر این پیادهسازی را یکبار نیز بر اساس دیتاست cifar100 تکرار خواهیم نمود.( یعنی در واقع به شبکه آموزش میدهیم که تصاویر دیتاست cifar10 را به درستی در گروههای مختلف قرار دهد و در کنار این آموزش اصلی به همان شبکه آموزش میدهیم که بتواند دوران عکسها در دیتاست cifar 100 را نیز به درستی پیشبینی کند)
پارامترهای به کار گرفته شده برای پیاده سازی مدل پیشنهادی
| epoch | Lr_type | mometum | Learning rate | Batch Size جانبی | Batch size اصلی | دیتاست جانبی | دیتاست اصلی |
| 33 | cosine | 0.9 | 0.1 | 32 | 32 | Cifar 10 | Cifar 10 |
| 33 | cosine | 0.9 | 0.1 | 64 | 32 | Cifar100 | Cifar10 |
| روش | Best test_set accuracy |
| condensnet | 87.43 |
| condensnet with cifar10 supervised | 88.58 |
| condensnet with cifar100 supervised | 89.14 |
همانطور که در جدول مربوط به نتایج مشاهده میشود در تعداد ایپاک مورد استفاده جهتیادگیری، به کارگیری تسک خود نظارتی توانسته تا حدودی نسبت به افزایش دقت مدل موثر واقع شود. به کارگیری دیتاست cifar 100 جهت تسک جانبی توانسته تاثیر مناسبتری نسبت به بکارگیری دیتاست cifar10 داشته باشد.
نمودارهای مربوط به تغییرات میزان دقت و تابع هزینه بر مبنای هر دو دیتای تست و ترین نیز ذخیره و در هر سه وضعیت مدلسازی شده در شکل زیر آورده شدهاند. تقریبا در هر دو تسک جانبی شبیهسازی شده با طی شدن ایپاکها به سمت مقادیر نهایی شبکه ما قادر شده است در حدود 80 درصد تصاویر دوران یافته را به درستی پیشبینی کند. رویه تغییر دقت و تابع هزینه نیز در نمودارها برای هر سه وضعیت مدلسازی شده، آورده شده است.
لازم به توضیح است با توجه به نزدیک بودن دقتها و مقادیر تابع loss، مقادیردقیق این عبارات در پروسه یادگیری شبکه پرینت شده و در نوتبوک نهایی مربوط به هر فایل موجود میباشند
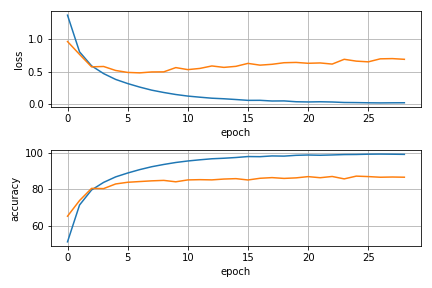
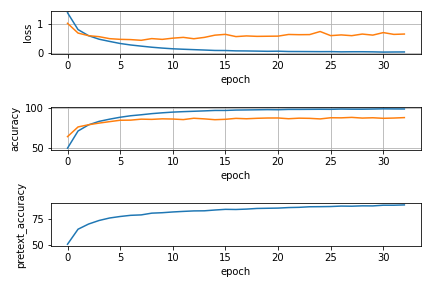
نمودارهای بالا میانگین loss و دقت بر حسب تعداد epoch در پیادهسازیهای مختلف را نشان می دهد. (نارنجی : دیتای ترین، آبی :دیتای تست)
نتیجه گیری
در این پروژه تلاش شد مدل condensnet پیاده سازی شود سپس با روش یادگیری خود نظارتی(Selfsupervise) بهبود داده شود. برای اینکار ابتدا اصل مقاله مورد اشاره پیاده سازی شد سپس با کمک یادگیری خود نظارتی بهبود داده شد. نتایج دقت بر روی داده Cifar10 با روش condensnet به مقدار 87.43 رسیدیم. این معیار بعد از بهبود روش با مقدار 88.58 رسیده است که نشان دهنده بهبود در عملکرد روش پیشنهادی است.