
scikit learn سایکیت لرن یک کتابخانه رایگان با زبان پایتون برای یادگیری ماشین است. این کتابخانه دارای الگوریتم های یادگیری ماشین مانند ماشین بردار پشتیبان (SVM)، درخت تصمیم و k نزدیک ترین همسایه است. همچنین این کتابخانه از کتابخانه های عددی و آماری پایتون مانند NumPy و SciPy پشتیبانی می کند. این کتابخانه می تواند یادگیری نظارت شده و یا یادگیری بدون نظارت را با کیفیت خوبی انجام دهد.
الگوریتم های یادگیری نظارت شده در scikit learn
الگوریتم های یادگیری ماشین به دو دسته کلی تقسیم می شوند. نظارت شده و بدون نظارت. ابتدا یادگیری نظارت شده را در کتابخانه scikit learn بررسی می کنیم. یادگیری نظارت شده به دو دسته تقسیم می شوند:
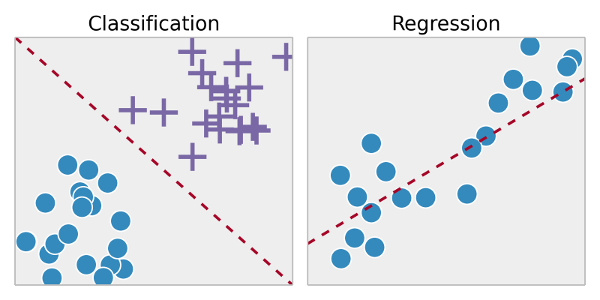
طبقه بندی(Classification):
در این الگوریتم ها نمونه ها به دو یا چند کلاس دسته بندی می شوند. ما می خواهیم با استفاده از نمونه ها و کلاس هایشان پیش کنیم نمونه های بدون کلاس در کدام دسته قرار می گیرند. برای مثال دست نوشته های عددی را در نظر بگیرید. هر دست نوشته عددی در بازه ۰ تا ۹ است. همچنین مشخص است که هر دست نوشته نشان دهنده چه عددی است(کلاس). حال با توجه به این مجموعه داده که شامل نمونه ها و کلاس ها است می توانیم نمونه های جدید بدون کلاس را دسته بندی کنیم. این یک مثال ساده از طبقه بندی است. در مثال کاربردی طبقه بندی داده ها با پایتون دقیقا همین مساله را به صورت عملی پیاده سازی کرده ایم.
رگرسیون(Regression):
رگرسیون نوعی از طبقه بندی است با این تفاوت که کلاس های ما به جای مقادیر گسسته دارای مقادیر پیوسته هستند. مثلا پیش بینی غلطت تولید شده در یک فرایند شیمایی.
سایکیت لرن از مدل های زیر پشتیبانی می کند:
- Generalized Linear Models
- Linear and Quadratic Discriminant Analysis
- Kernel ridge regression
- Support Vector Machines
- Stochastic Gradient Descent
- Nearest Neighbors
- Gaussian Processes
- Naive Bayes
- Decision Trees
- Ensemble methods
- Feature selection
- Semi-Supervised
- Probability calibration
- Neural network models
الگوریتم های بدون نظارت در کتابخانه Scikit Learn
این الگوریتم ها داده ها را بر اساس شباهت های ذاتی آن ها دسته بندی می کنند. هدف در این مسایل کشف نمونه های مشابه در یک مجموعه داده است. به این الگوریتم ها خوشه بندی هم گفته می شود.
سایکیت لرن از مدل های زیر برای یادگیری بدون نظارت استفاده می کند:
- Gaussian mixture models
- Manifold learning
- Clustering
- Biclustering
- Decomposing signals in components
- Covariance estimation
- Novelty and Outlier Detection
- Density Estimation
- Neural network models (unsupervised)
برای اطلاعات بیشتر راجع به الگوریتم های خوشه بندی مطلب 5 الگوریتم خوشه بندی (clustering) که متخصصین علم داده باید بدانند را مطالعه کنید.
انتخاب و ارزیابی مدل(Model Selection and Evaluation)
هر مدلی که طراحی می شود باید ارزیابی شود تا دقت عملکرد آن مشخص شود. اگر از داده هایی که برای طراحی مدل استفاده شده است برای ارزیابی هم استفاده شود ارزیابی به درستی صورت نگرفته است و طبیعتا دقت مدل بسیار زیاد خواهد بود. برای آنکه ارزیابی مدل بدرستی انجام شود بخشی از داده ها از داده اصلی جدا می کنیم تا فقط برای ارزیابی استفاده شود. داده ها را معمولا X_train و کلاس یا برچسب های آن را y_train می نامیم.
انتخاب مدل شامل موارد زیر است:
- اعتبار سنجی : ارزیابی عملکرد
- تنظیم پارامتر ها
- ارزیابی مدل: کمی سازی کیفیت پیش بینی ها
- پایداری مدل
- نمودار های اعتبار سنجی: محاسبه معیار ها برای ارزیابی مدل ها
تبدیل مجموعه داده – Dataset transformations
زمانی که با استفاده از یک الگوریتم یک مدل ساخته می شود باید این مدل بر روی مجموعه داده اعمال شود. اعمال مدل بر روی مجموعه داده با پارمتر fit و انتقال آن به مجموعه داده ای که عمل یادگیری روی آن صورت نگرفته است با پارمتر transform انجام می شود.
تبدیل مجموعه داده شامل موارد زیر است:
- استخراج ویژگی ها
- پیش پردازش داده ها
- کاهش ابعاد بدون نظارت
- تبدیل داده های هدف (Target)
مجموعه داده های موجود در سایکیت لرن
کتابخانه سایکیت لرن مجموعه داده های مفیدی در خود دارد. برای نمونه:
- The Olivetti faces dataset
- The 20 newsgroups text dataset
- Breast Cancer Wisconsin (Diagnostic) Database
- Boston House Prices dataset
- Iris Plants Database
کتابخانه scikit learn یکی از بزرگترین و مهم ترین کتابخانه های یادگیری ماشین و علم داده است. مباحث گفته شده در این بخش مقدمه و شروع کار با این کتابخانه است. در بخش های بعدی به تفصیل و جزیات بیشتر به این کتابخانه می پردازیم.
توضیحات تکمیلی درباره دیتاست های سایکیت لرن را اینجا بخوانید