
در سال های اخیر هوش مصنوعی شاهد رشد چشمگیری بوده است. محققان و علاقه مندان روی جنبه های مختلفی از این زمینه کار می کنند. یکی از از این جنبه ها بینایی ماشین (Computer Vision) است.
هدف ما این این است که ماشین ها بتوانند جهان را مانند انسان ها ببینند ، آن را به روشی مشابه درک کنند و حتی از از این دانش برای بسیاری از کارها مانند تشخیص تصویر و فیلم ، تجزیه و تحلیل و طبقه بندی تصویر ،سیستم های توصیه گر، پردازش زبان طبیعی ، و غیره استفاده کنند. بینایی کامپیوتر با یادگیری عمیق در طول زمان ساخته و کامل شده است که مهمترین الگوریتم آن شبکه عصبی کانولوشن(Convolutional Neural Network) است.
مقدمه

شبکه عصبی کانولوشن (ConvNet/CNN) یک الگوریتم یادگیری عمیق است که می تواند یک تصویر را به عنوان ورودی گرفته، به اجزا مختلف در تصویر اهمیت (وزن و بایاس قابل یادگیری) اختصاص دهد و بتواند یکی را از دیگری متمایز کند. پیش پردازش مورد نیاز در شبکه عصبی کانولوشن در مقایسه با الگوریتم های طبقه بندی دیگر بسیار کمتر است.
معماری CNN مشابه الگوی اتصال نورون ها در مغز انسان است و از قشر دیداری ( Visual Cortex )الهام گرفته است.هر نورون فقط در یک منطقه محدود از میدان دید که به عنوان میدان تاثیر (Receptive Field) شناخته می شود ، به محرک ها پاسخ می دهند. با روی هم قرار گرفتن این منطقه ها کل تصویر پوشش داده می شود.
برتری CNN نسبت به شبکه عصبی پیش خور (Feed-Forward Neural Nets)
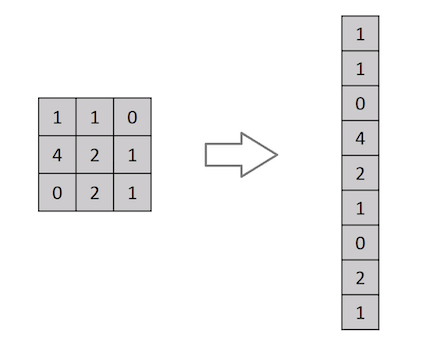
ک تصویر چیزی نیست جز ماتریسی از مقادیر پیکسل ، پس چرا فقط تصویر را مسطح نمی کنیم (به عنوان مثال ماتریس تصویر 3×3 در یک بردار 9×1) و آن را برای اهداف طبقه بندی به یک پرسپترون چند لایه ارائه نمی دهیم؟
در موارد تصاویر باینری بسیارساده (مانند تصویر سیاه و سفید) ، این روش ممکن است هنگام انجام پیش بینی کلاس ها ، به یک نمره متوسط دست یابد ، اما در مورد تصاویر پیچیده ای که در کل وابستگی به پیکسل دارند ، دقت چندانی ندارد.
CNN قادر است با استفاده از فیلترهای مربوطه وابستگی های مکانی و زمانی را در یک تصویر ثبت کند. این معماری به دلیل کاهش تعداد پارامترهای درگیر و قابلیت استفاده مجدد از وزن ها ، سازگاری بهتری با مجموعه داده های تصویر دارد. به عبارت دیگر ، می توان شبکه را آموزش داد تا پیچیدگی تصویر را بهتر درک کند.
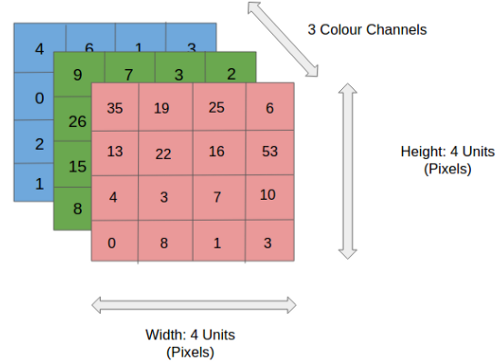
در شکل ، ما یک تصویر RGB داریم که توسط سه صفحه قرمز – سبز و آبی جدا شده است. تعدادی از این فضاهای رنگی وجود دار – Grayscale, RGB, HSV, CMYK و غیره
نقش CNN کاهش تصاویر به شکلی است که پردازش آن آسان تر باشد ، بدون از دست دادن ویژگی هایی که برای بدست آوردن پیش بینی ضروری است. و همچنین هنگامی که می خواهیم معماری را طراحی کنیم که نه تنها در یادگیری ویژگی ها خوب باشد بلکه در مجموعه داده های عظیم نیز مقیاس پذیر باشد .
لایه کانولوشن
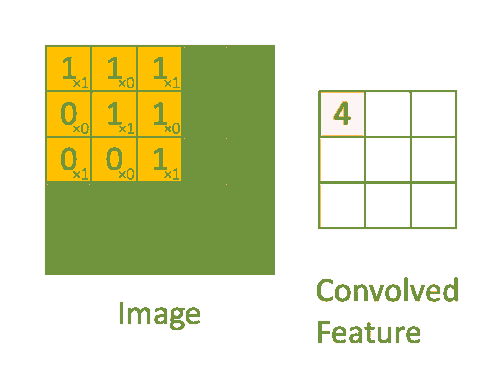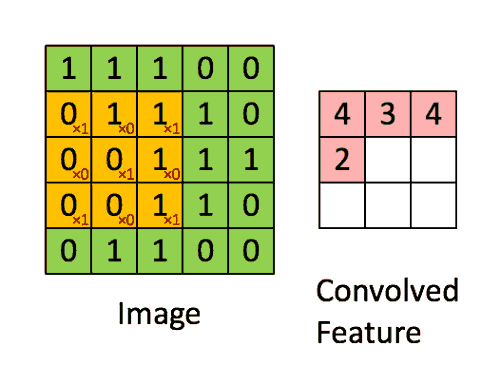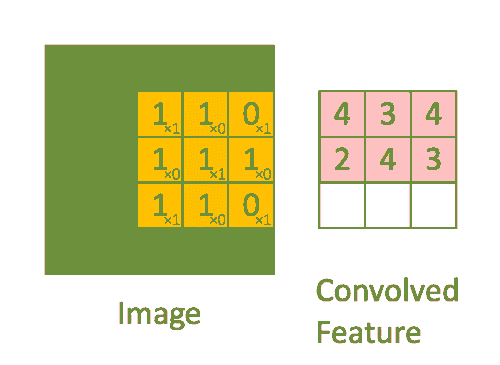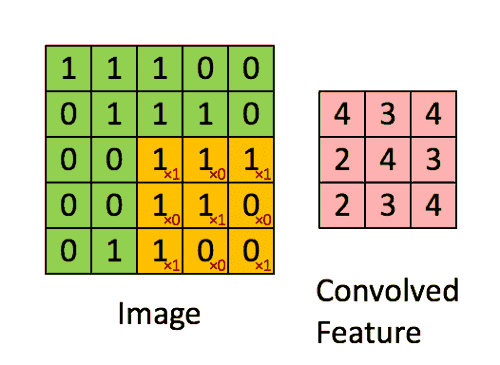
ابعاد تصویر = (ارتفاع) x (عرض) x (تعداد کانال ها ، به عنوان مثال RGB) – 5x5x1
در نمایش فوق ، قسمت سبز 5x5x1 است. عنصری که در انجام عملیات کانولوشن نقش دارد ، فیلتر/کرنل K است که با رنگ زرد نشان داده شده است. ما K را به عنوان ماتریس 3x3x1 انتخاب کرده ایم.
Kernel/Filter, K = 1 0 1 0 1 0 1 0 1
فیلتر ۹ بار تغییر مکان می دهد (طول گام ۱ است) ، هر بار یک عملیات ضرب ماتریس بین K و بخش P تصویر که فیلتر در آن است انجام می شود.

فیلتر با یک گام خاص (Stride) به سمت راست حرکت می کند تا اینکه عرض کامل را طی کند. با حرکت به سمت پایین ، با همان مقدار گام به ابتدای (سمت چپ) تصویر می پرد و روند را تکرار می کند تا کل تصویر پیموده شود.
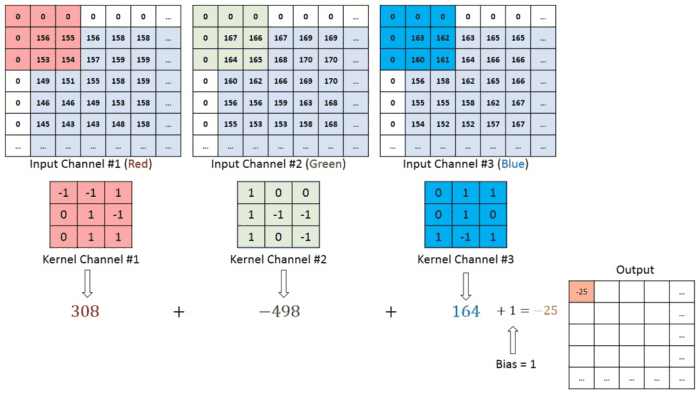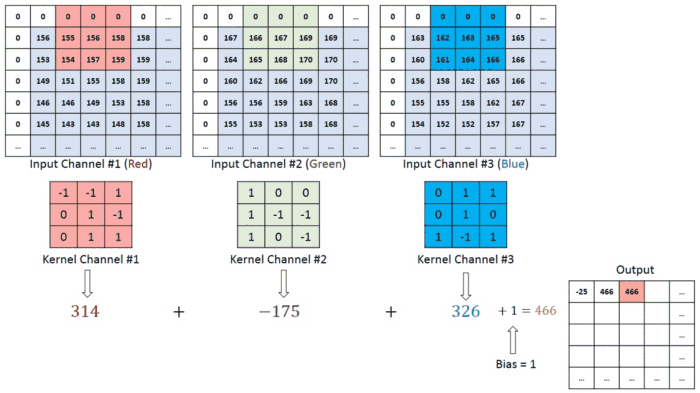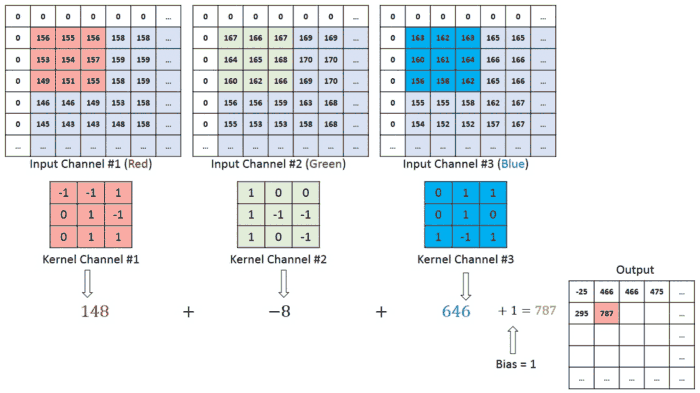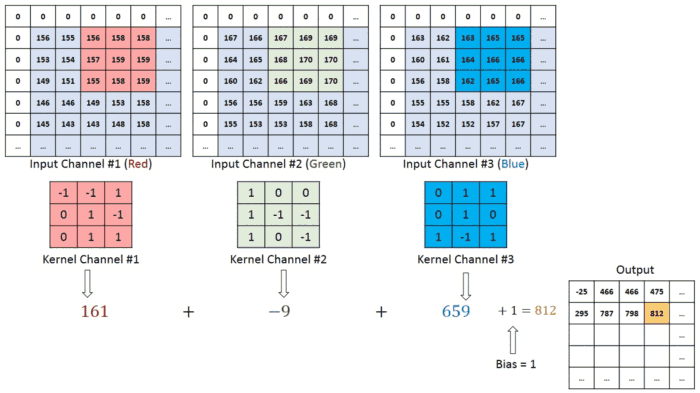
در مورد تصاویر با چندین کانال (به عنوان مثال RGB) ، فیلتر دارای همان عمق تصویر ورودی است. ضرب ماتریس بین Kn و In انجام می شود ([K1 ، I1] ؛ [K2 ، I2] ؛ [K3 ، I3]) و تمام نتایج به همراه بایاس باهم جمع می شوند تا به ما یك تصویر با عمق ۱ تحویل دهد.
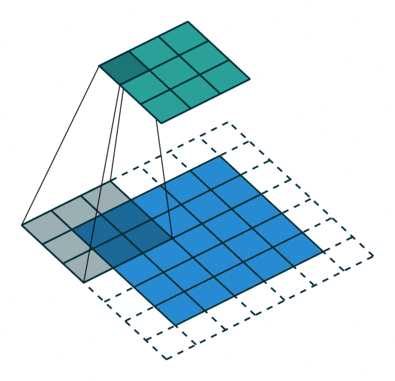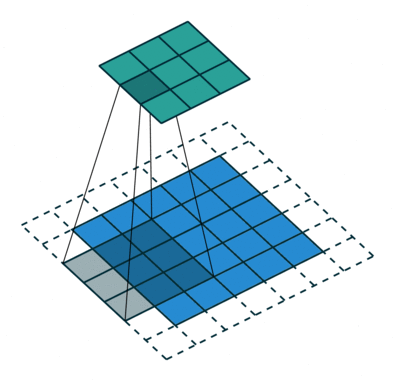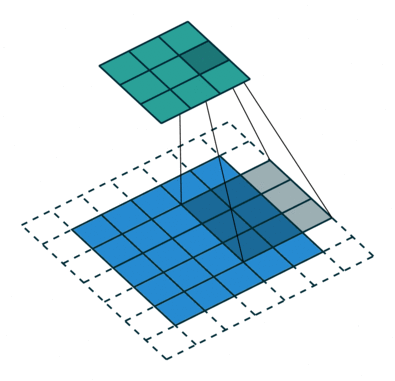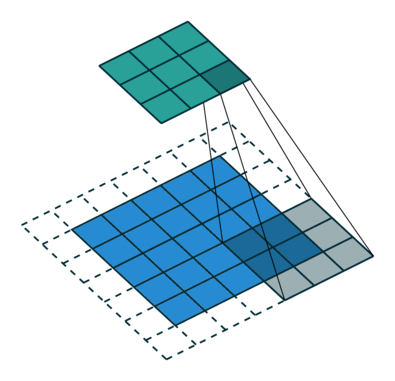
هدف از عملیات کانولوشن استخراج ویژگی های سطح بالا از تصویر ورودی است. CNN فقط به یک لایه کانولوشن محدود نمی شود. به طور معمول ، اولین لایه کانولوشن وظیفه ضبط ویژگی های سطح پایین مانند لبه ها ، رنگ ، جهت شیب و غیره را دارد. با اضافه شدن لایه ها ، معماری با ویژگی های سطح بالا(مانند تصویر یک عقاب) نیز سازگار می شود و به ما شبکه ای می دهد که درک کاملی از تصاویر موجود در مجموعه داده دارد.
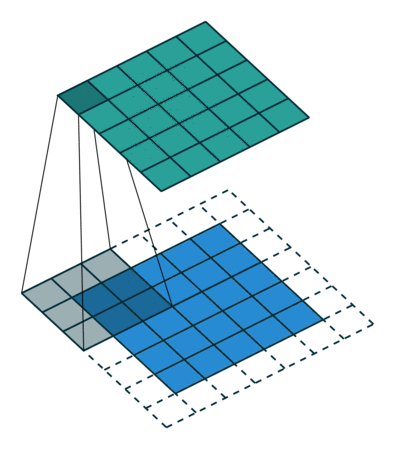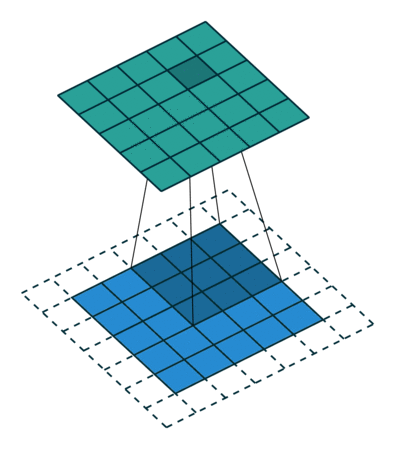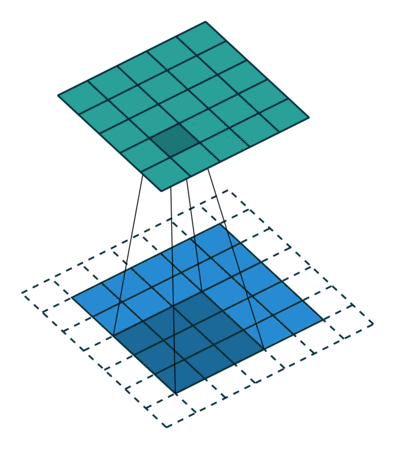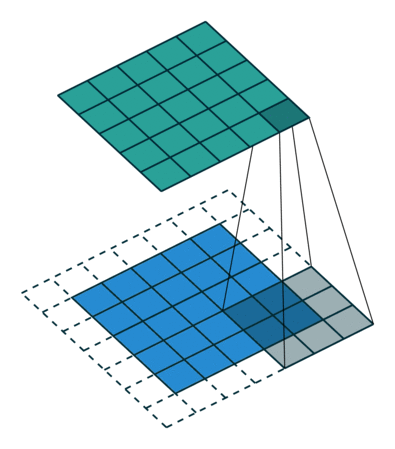
same padding و Valid Padding
وقتی تصویر 5x5x1 را به یک تصویر 6x6x1 افزایش می دهیم و سپس فیلتر 3x3x1 را روی آن اعمال می کنیم ، متوجه می شویم که ماتریس کانولود شده به ابعاد 5x5x1 در می آید. – Same Padding.
از طرف دیگر ، اگر همان کار را بدون padding انجام دهیم ، ماتریسی به ما ارائه می شود که دارای ابعاد (3x3x1) است – Valid Padding
لایه پولینگ – Pooling Layer
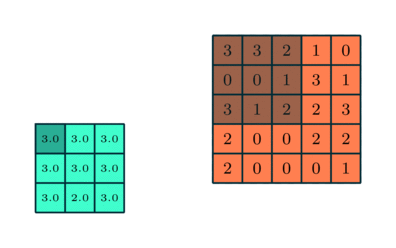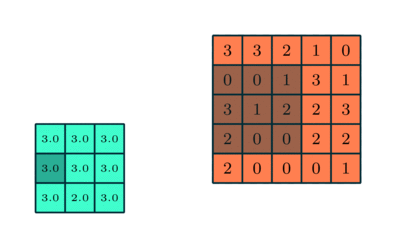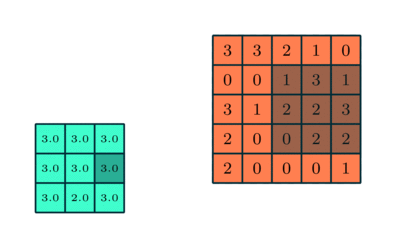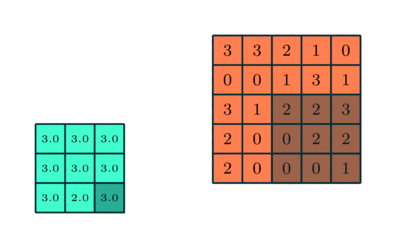
لایه Pooling وظیفه کاهش اندازه ویژگی های کانولود خورده را بر عهده دارد. این کار برای کاهش توان محاسباتی مورد نیاز برای پردازش داده ها از طریق کاهش ابعاد است. علاوه بر این برای استخراج ویژگی های برتر که از نظر دورانی و مکانی یکسان هستند ، مفید است و بنابراین روند آموزش موثر مدل را حفظ می کند.
دو نوع Pooling وجود دارد: Max Pooling حداکثر مقدار از تصویر پوشانده شده را برمی گرداند. از طرف دیگر ، Average Pooling میانگین تمام مقادیر را از بخش تحت پوشش برمی گرداند.
پس از طی مراحل بالا ، ما با موفقیت مدل را قادر به درک ویژگی ها کردیم. درادامه ، ما قصد داریم خروجی نهایی را مسطح کرده و آن را به یک شبکه عصبی منظم برای اهداف طبقه بندی تغذیه کنیم.
طبقه بندی – لایه کاملاً متصل (Fully Connected Layer)
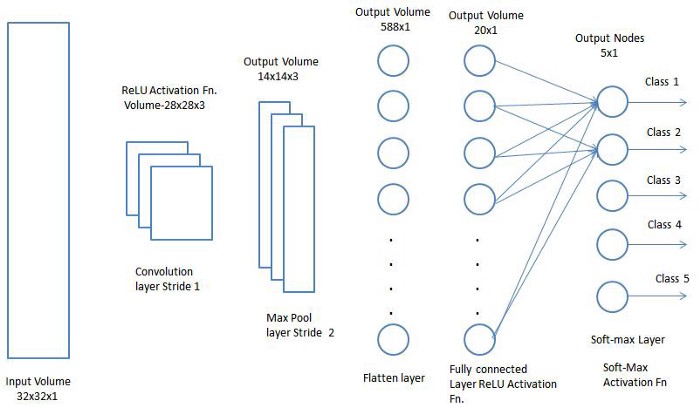
اکنون که تصویر ورودی خود را به فرم مناسبی برای پرسپترون چند سطحی تبدیل کرده ایم ، باید تصویر را به صورت بردار ستونی مسطح کنیم. خروجی مسطح شده به یک شبکه عصبی کاملا متصل شده داده می شود. این مدل قادر است با استفاده از روش طبقه بندی Softmax تصاویر را طبقه بندی کند.
معماری های CNN زیادی وجود دارد . برخی از آنها در زیر لیست شده است:
- LeNet
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
- ZFNet
سلام استاد
در مورد یک پروژه میخوام با شما مشورت کنیم
میتونید یه ایمیل برام بفرستید تا در این مورد صحبت کنیم؟
ممنون
سلام. راه های ارتباطی در قسمت تماس با ما قرار داده شده