
سیستم های پیشنهاد دهنده در جهان یادگیری ماشین بسیار محبوب شده اند و برای غول های فناوری مانند Netflix ، Amazon و بسیاری دیگر از شرکت ها مزایای بزرگ برای هدف قرار دادن محتوای خود به مخاطبان است. این موتورهای پیشنهادی به قدری در پیش بینی های خود قوی هستند که می توانند بر اساس تعامل کاربر با برنامه ، آنچه کاربر در صفحه خود می بیند را به صورت پویا تغییر دهند.

فیلتر مشارکتی مورد-محور
فیلترینگ مشارکتی مبتنی بر مورد روشی است كه توسط آمازون تهیه شده است و در سیستم های توصیه كننده استفاده می شود تا اساساً توصیه هایی را بر اساس شباهت بین موارد مختلف در یك مجموعه داده به كاربران ارائه دهد. توصیه ها بر اساس رتبه بندی کاربر برای آن مورد خاص محاسبه می شود.
یک سیستم توصیه دهنده فیلم
مجموعه داده ای که ما در این پروژه استفاده خواهیم کرد مربوط به MovieLens است.
کار خود را با وارد کردن به دیتا به محیط کاری شروع می کنیم. این پروژه در محیط Jupyter Notebook انجام شده است. امتیاز هر کاربر به فیلم را در r_cols و اطلاعات هر فیلم را در m_cols می ریزم.
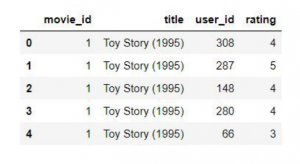
گام بعدی این است که یک ماتریس ایجاد کنیم که در این ماتریس مشخص است هر کاربر به هر فیلم چه امتیازی داده است. این جدول برای ما ایده این است که کدام کاربر چه فیلم هایی را تماشا کرده و چه نوع امتیازی داده است.

ما تجزیه تحلیل خود را بر روی فیلم جنگ ستارگان انجام می دهیم. پس مقادر مربوط به این فیلم را در یک متغییر می ریزیم.
لورم ایپسوم متن ساختگی با تولید سادگی نامفهوم از صنعت چاپ و با استفاده از طراحان گرافیک است. چاپگرها و متون بلکه روزنامه و مجله در ستون و سطر آنچنان که لازم است.

ما برای پیدا کردن همبستگی دوتایی بین همه ستون ها با توجه به فیلم جنگ ستارگان از تابع ()corr که در کتابخانه pandas قرار دارداستفاده خواهیم کرد.
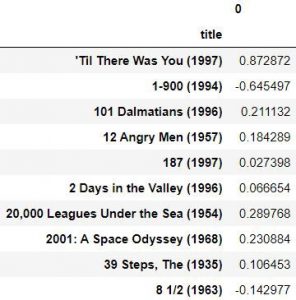
از این اطلاعات نمی توانی دانش مناسبی استخراج کنیم. علت آن است که بعضی از افراد هیچی فیلمی را رتبه بندی نکرده اند یا بعضی از فیلم ها توسط افراد کمی امتیاز دهی شده اند. برای همین باید بر روی داده ها عملیات دیگیری انجام دهیم.
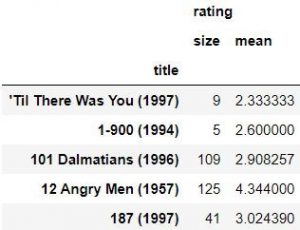
نمونه هایی که کمتر از ۱۰۰ نفر به آن امیتاز داده اند را حذف می کنیم. براین کار دستورات زیر را وارد می کنیم.
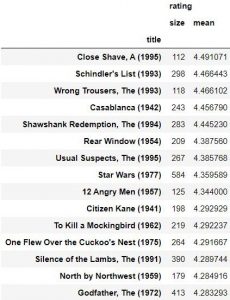
این داده را به مجموعه داده مشابهت با فیلم جنگ ستارگان join می کنیم.
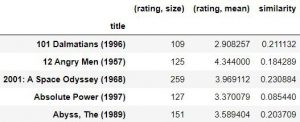
در اخر نمونه ها را بر اساس مقدار مشابهت به صورت نزولی مرتب می کینم.
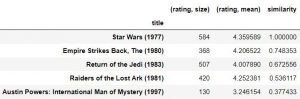
نتیجه
همان طور که می بینید که سه فیلم برتر در خروجی نهایی بدست آوردیم همگی فیلم های جنگ ستارگان هستند. چند فیلم بعدی براساس ژانرهای مشابه یعنی اکشن و ماجراجویی ساخته شده اند. ما یک سیستم توصیه کننده فیلم ساخته ایم که قادر است با دقت خوبی کاربر را به دیدن فیلمی مرتبط با آنچه در گذشته تماشا کرده است ، پیشنهاد دهد