
الگوریتم ماشین های بردار پشتیبانی (SVM) دارای کاربردهای مختلفی برای مسایل رگرسیون و همچنین برای طبقه بندی به صورت خطی و غیر خطی است. در این مطلب قصد داریم به طبقه بندی SVM نگاهی می اندازیم و با زبان پایتون آن را پیاده سازی کنیم
SVM می تواند برای پیش بینی اینکه یک آهنگ توسط اهنگ سازی خاص ساخته شده ، مورد استفاده قرار گیرد. یا اینکه یک مقاله خبری جعلی است یاخیر. در این مقاله به بررسی موارد زیر خواهیم پرداخت:
- SVM چیست؟
- SVM ها چگونه کار می کنند؟
- نحوه اجرای SVM در پایتون.
ماشین بردار پشتیبان
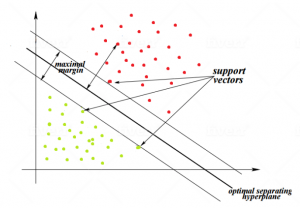
الگوریتم طبقه بندی SVM داده ها را به فضای n بعدی می برد. بدین صورت که اگر داده ها ۱۰ بعد یا ستون داشته باشد آن ها را در فضای ۱۰ بعدی ترسیم می کند. از آن جایی که ما نمی توانیم درکی از از آن فضا داشته باشیم داده ها را در یک فضای ۲ بعدی نمایش می دهیم. سپس الگوریتم با یک ابرصفحه(hyperplan) داده ها از یک دیگر جدا می کند.(در مثال ۲ بعدی یک خط این کار را انجام می دهد.) سوالی که ایجاد می شود این آن است که بیشتر خط یا صفحه می توان در فضا ایجاد کرد. چه خطی باید توسط الگوریتم رسم شود؟ این ابر صفحه باید بتواند بیشتر فاصله با نمونه ها را داشته باشد به طوری که آن ها را به دسته های مجزا تقسیم کند. مانند شکل بالا.
بردارهای پشتیبانی
نقاطی كه نزديك به ابرصفحه است ، بردارهاي پشتيباني هستند. این نقاط باعث می شود با محاسبه حاشیه ، مرز تصمیم گیری بهتر شود. این بردارهای پشتیبانی نقاط مهمی برای محاسبات تکراری مورد نیاز برای ساخت طبقه بندی کننده هستند.
ابرصفحه(hyperplan)
ابر صفحه یک بردار پشتبان است که فاصله اش از هر طرف بیشنیه است.
حاشیه(Margin)
فاصله بین دورترین بردار های پشتیبان است
نحوه کارکرد SVM
هدف اصلی SVM تقسیم داده های داده شده به بهترین روش ممکن در کلاسهای مختلف است. فاصله بین نزدیکترین نقاط داده هر کلاس به عنوان حاشیه شناخته شده است. هدف SVM انتخاب یک ابر صفحه با حداکثر حاشیه ممکن بین بردارهای پشتیبانی در داده های داده شده است. این کار را به روش های زیر انجام می دهد:
- چندین خط رسم می کند تا بتواند داده ها را به بهرین روش تقسیم کند.
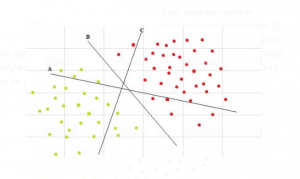
اکنون چندین خط برای انتخاب وجود دارد. کدام یک را باید انتخاب کرد. طبیعتا خطی که بتواند بیشترین فاصله را با نمونه ها ایجاد کند. در اینجا خط B این ویژگی را دارد پس به عنوان خط مورد نظر انتخاب می شود.
- در مرحله بعدی چندین خط در راستای خط انتخاب شده کشیده می شود تا بتوانیم بیشرین فاصله از نمونه ها را پیدا کنیم و آن خط به عنوان جدا کنند یا ابرصفحه مورد نظر انتخاب شود.
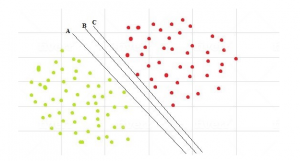
هسته SVM
همانطور که قبلا اشاره کردیم SVM ممکن است برای تقسیم بندی داده های غیرخطی استفاده شود در صورتی که برای داده های خطی طراحی شده است برای اینکه طبقه بندی بر روی داده های غیر خطی کار کند از پارامتری به نام هسته استفاده می کنیم.
هسته یک فضای داده ورودی را به فضای موردنیاز تبدیل می کند که در آن داده ها می توانند به صورت خطی از هم جدا شوند. انواع مختلف هسته وجود دارد ، از جمله عملکرد خطی ، چند جمله ای و عملکرد پایه شعاعی (rbf). الگوریتم SVM از تکنیکی به نام ترفند هسته استفاده می کند که توسط آن هسته فضای ورودی کم بعدی را در اختیار شما قرار می دهد و آن را به یک فضای بعدی بالاتر تبدیل می کند.
پیاده سازی SVM با استفاده از پایتون
حال که با مفاهیم الگوریتم ماشین بردار پشتیبان آشنا شدیم با یک مثال عملی با زبان پایتون آن را پیاده ساری می کنیم.
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn import svm
from sklearn.metrics import accuracy_score