
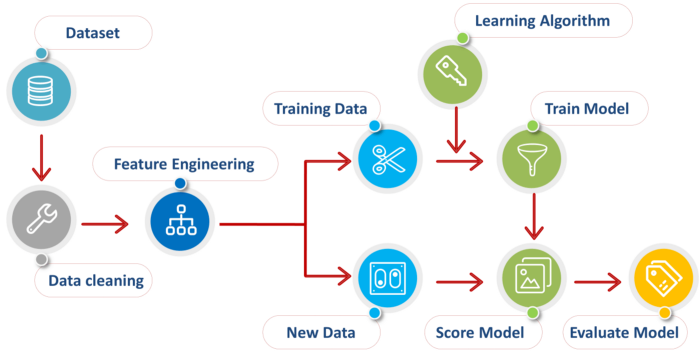
هسته اصلی یادگیری ماشین پردازش داده ها است. قبل از شروع کار با الگوریتم های یادگیری ماشین داده ها باید آماده شوند تا دقت و خروجی کار بالاتر رود. در این مطلب قصد داریم با یک مثال عملی پیش پردازش داده ها با زبان پایتون را توضییح دهیم. قبل از شروع کار روند کلی یک سیستم یادگیری ماشین را در تصویر زیر مشاهده می کنید.
دیتاست استفاده شده در این آموزش را از این اینجا می توانید دریافت کنید.
مراحل پیش پردازش داده ها به صورت زیر است:
گام اول: وارد کردن کتابخانه های مورد نیاز
زمانی که می خواهیم پیش پردازش داده ها انجام دهیم معمولا با کتابخانه pandas پایتون کار می کنیم. این کتابخانه برای وارد کردن داده ها و مدیریت آن ها بسیار پرکاربرد است.
import pandas as pd
گام دوم: وارد کردن مجموعه داده
مجموعه داده ما به فرمت CSV است. کتابخانه pandas به راحتی می تواند با این فرمت داده کار کند.
df = pd.read_csv('Data.csv')
پس از بررسی دقیق داده ها ، آن ها را به دو قسمت X (داده ها) و y(برچسب ها) تقسیم می کنیم. برای این کار از متد iloc در کتابخانه pandas استفاده می کنیم.
X = df.iloc[:, :-1].values y = df.iloc[:, 3].values
گام سوم: مدیریت داده های مفقود شده(Missing values)
داده هایی که به دست می آوریم بندرت همگن است. گاهی اوقات داده ها ممکن است دارای داده از دست رفته باشند و باید به آنها رسیدگی شود تا عملکرد مدل یادگیری ماشین ما را کاهش ندهد.
یکی از قسمت های مهم در پیش پردازش داده ها با پایتون مدیریت داده های گم شده می باشد.برای انجام این کار باید داده های از دست رفته را با میانگین یا میانگین کل ستون جایگزین کنیم. برای این منظور ما از کتابخانه sklearn.preprocessing استفاده خواهیم کرد که شامل یک کلاس به نام Imputer است که به ما در پر کردن داده های از دست رفته کمک می کند.
می تواند در قسمت مقالات مرتبط با مقادیر گم شده در پایتون در این مورد بیشتر مطالعه کنید.
from sklearn.preprocessing import Imputer imputer = Imputer(missing_values = "NaN", strategy = "mean", axis = 0)
یک شی از کلاس Imputer به همین نام ایجاد می کنیم. کلاس Imputer می تواند پارامتر های زیر را بگیرد:
- missing_values: نوع مقدار از دست رفته را مشخص می کند. در این مثال مقادیر از دست رفته با NaN مشخص شده است. به همین دلیل ما این مقدار را قرار می دهیم.
- strategy: این پارامتر روش پر کردن داده های از دست رفته را مشخص می کند. اگر برابر با “mean” روش محاسبه خانه ها بر اساس میانگین همان سطر یا ستون خواهد بود. روش های مختلفی برای پر کردن داده های از دست رفته وجود دارد. از دیگر روش های پر استفاده “median”(میانه) و “most_frequent”(بیشترین فراوانی) است.
- axis: می تواند ۰ یا ۱ باشد. اگر ۱ باشد تغییرات در راستای ستون خواهد بود. در صورت ۰ بودن تغییرات بر روی سطر ها اعمال می شود.
حال شی imputer را با استفاده از پارامتر fit بر روی داده های خود قرار می دهیم.
imputer = imputer.fit(X[:, 1:3])
سپس مقادیر جدید را بر روی خانه های خالی قرار می دهیم.
X[:, 1:3] = imputer.transform(X[:, 1:3])
گام چهارم: تبدیل داده های کیفی(categorical)
هر داده ای که عددی نباشد کیفی یا categorical است. برای مدلسازی حتما باید داده ها به صورت عددی باشند. برای مثال رنگ، رشته تحصیلی، وضعیت زندگی همگی categorical هستند.
برای این کار کلاس “LabelEncoder” را از کتابخانه “sklearn.preprocessing” وارد کرده و یک شی labelencoder_X از کلاس LabelEncoder ایجاد می کنیم. پس از آن ما از روش fit_transform برای تبدیل داده ها استفاده می کنیم.
پس از تبدلی مقادیر باید باز هم تغییراتی روی اعداد انجام دهیم. فرض کنید به رنگ قرمز عدد ۱ و به رنگ سبز عدد ۲ را نسبت دهیم. در این حالت الگوریتم های یادگیری ماشین عدد ۲ را برتر از عدد ۱ در نظر می گیرند. در صورتی که ما همچین نیتی نداشتیم. برای آن که از نظر الگوریتم اعداد برتری نسبت به هم نداشته باشند از One-Hot Encoding استفاده می کنیم.
One-Hot Encoding در جایی که اعداد سلسلسه مراتبی نیستند کاربرد دارد. مثلا شماره تلفن یا کد پستی. این ها فقط اعدادی هستند که هیچ برتری بر دیگری ندارند. برای One-Hot Encoding از روش زیر استفاده می می کنیم.
from sklearn.preprocessing import LabelEncoder, OneHotEncoder labelencoder_X = LabelEncoder() X[:, 0] = labelencoder_X.fit_transform(X[:, 0]) onehotencoder = OneHotEncoder(categorical_features = [0]) X = onehotencoder.fit_transform(X).toarray() labelencoder_y = LabelEncoder() y = labelencoder_y.fit_transform(y)
شکل شیر تصویر خوبی از تبدیل مقادیر کیفی به مقادیر عددی مناسب برای داده کاوی ارایه می دهد.

گام پنجم: تقسیم بندی داده ها به دو قسمت آموزش و تست.
در این مرحله از پیش پردازش با پایتون ما داده های خود را به دو مجموعه تقسیم می کنیم ، یکی برای آموزش مدل خود به نام مجموعه آموزشی و دیگری برای آزمایش عملکرد مدل خود. تقسیم به طور کلی 70/30 است. برای این کار ما “train_test_split” را از کتابخانه “sklearn.model_selection” را وارد می کنیم.
from sklearn.model_selection import train_test_split
اکنون برای ساخت مجموعه های آموزشی و آزمایشی خود ، 4 مجموعه ایجاد خواهیم کرد:
- X_train:نمونه های قسمت آموزش
- X_test: نمونه های قسمت تست
- Y_train: برچسب های قسمت آموزش
- Y_test: برچسب های قست تست
تابع test_train_split نمونه ها و بر چسب ها به همراه نسبت آموزش به تست را در یافت می کند و آن را در ۴ متغییر می ریزد. ترتیب قرار داده متغییر ها باید به همین صورت باشد.
X_train, X_test, Y_train, Y_test = train_test_split( X , Y , test_size = 0.3, )
گام ششم: مقیاس بندی
بیشتر الگوریتم های یادگیری ماشین از فاصله اقلیدسی برای محاسات خود استفاده می کنند. به همین دلیل اگر چند نمونه مقدار خیلی زیاد یا خیلی کمی داشته باشند دقت مدلسازی کاهش می یابد. برای حل این مشکل از مقیاس بندی داده ها استفاده می شود. یکی از معروف ترین این مقایس بندی ها تبدیل Z است. تبدیل Z با استفاده از کلاس “StandardScaler” که در کتابخانه “sklearn.preprocessing است انجام می شود.
from sklearn.preprocessing import StandardScaler sc_X = StandardScaler() X_train = sc_X.fit_transform(X_train) X_test = sc_X.transform(X_test)
این مرحله اخرین مرحله از پیش پردازش داده ها بود. حال شما می توانید داده های خود را به الگوریتم های یادگیری ماشین تزریق کنید.
امیدوارم از این مطلب استفاده کرده باشید.