آمار، استفاده از ریاضیات برای انجام تجزیه و تحلیل فنی داده ها است. در علم داده استفاده از آمار نقش اساسی در تجزیه داده ها دارد. یک مصورسازی مانند نمودار میله ای ممکن است اطلاعات سطح بالایی به شما بدهد که در بررسی عادی داده ها مشخص نباشد. با استفاده از آمار می توانیم داده ها را صورت هدفمندتری دسته بندی کنیم.
با استفاده از آمار ، می توانیم بینش دقیق تری در مورد نحوه ساخت داده های خود داشته باشیم. ما قصد داریم ۴ مفهوم آماری اساسی را که دانشمندان داده باید بدانند را بررسی کنیم.
۱.ویژگی های آماری
ویژگی های آماری احتمالاً پرکاربردترین مفهوم آمار در علم داده است. این مفهوم اغلب اولین روش آماری است که هنگام کاوش یک مجموعه داده استفاده می کنیم و شامل مواردی مانند بایاس ، واریانس ، میانگین ، میانه و بسیاری دیگر از روش هاست. شکل زیر را ببینید.
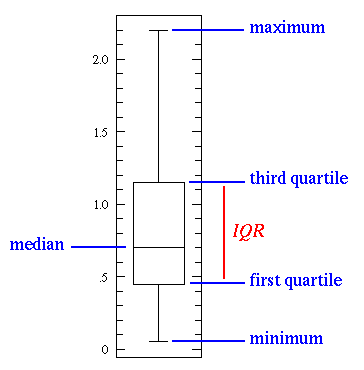
خط وسط نشان دهنده میانه(median) است. میانه از میانگین قوی تر از میانگین است چون تاثیر داده های پرت را بسیار کمتر می کند. این نمودار داده ها را به ۴ قسمت (چارک) تقسیم می کند و کمینه و بیشنه داده ها را به خوبی نمایش می دهد. همچنین نمی از داده ها در چارک ۲ و ۳ قرار دارند.
به این نمودار ، نمودار جعبه ای (BoX plot) می گویند. این نمودار می تواند اطلاعات اولیه و بسیار خوبی از داده ها به ما بدهد. در ادامه ویژگی های این نمودار را بررسی می کنیم:
- وقتی طول نمودار جعبه ای کوتاه است ، به این معنی است که بسیاری از داده ها مشابه هستند ، زیرا مقادیر زیادی در محدوده کوچک وجود دارد.
- وقتی نمودار جعبه ای بلند است ، به این معنی است که بسیاری از داده ها کاملاً متفاوت هستند ، زیرا مقادیر در دامنه وسیعی پخش شده اند
- اگر مقدار متوسط به پایین نزدیکتر باشد ، می دانیم که بیشتر داده ها مقادیر کمتری دارند. اگر مقدار متوسط به بالاترین قسمت نزدیک باشد ، می دانیم که بیشتر داده ها مقادیر بالاتری دارند. اساساً ، اگر خط میانه در وسط جعبه نباشد ، این نشانه ای از داده های غیر همگن است
- اگر نمودار خطوط بلندی دارد بدان معناست که داده های شما دارای انحراف و واریانس استاندارد بالایی هستند ، یعنی مقادیر پخش شده و بسیار متفاوت هستند. اگر در یک طرف جعبه خط های بلندی دارید اما طرف دیگر را ندارید ، ممکن است داده های شما فقط در یک جهت بسیار متفاوت باشد.
همه این اطلاعات از چند ویژگی ساده آماری بدست آمد. این اطلاعات در علم داده بسیار مفید هستند و در عین حال بسیار مفید هستند.
۲.توزیع های احتمال
در آمار احتمال را به عنوان درصد وقوع برخی از رویدادها تعریف کنیم. در علم داده این امر معمولاً در محدوده 0 تا 1 تعیین می شود که 0 به این معنی است که ما اطمینان داریم که این اتفاق نخواهد افتاد و 1 به این معنی است که اطمینان داریم که رخ خواهد داد. توزیع احتمال ، تابعی است که احتمالات تمام مقادیر ممکن را در آزمایش نشان می دهد.
توزیع نرمال
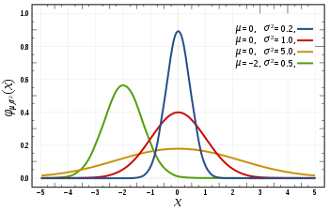
توزیع نرمال (Normal Distribution)، در آمار یکی از مهمترین توزیعهای احتمالی پیوسته در نظریه احتمالات است که شاید بسیار در علم داده با آن سر و کار داشته باشید. علت نامگذاری و اهمیت این توزیع، این است که بسیاری از مقادیر حاصل شده، هنگام نوسانهای طبیعی و فیزیکی پیرامون یک مقدار ثابت از این توزیع پیروی مینمایند.
بسیاری از پدیدههای طبیعی مثل قد و وزن افراد، نمرات درسی، میزان محصول در طول سال و … از توزیع نرمال پیروی میکنند
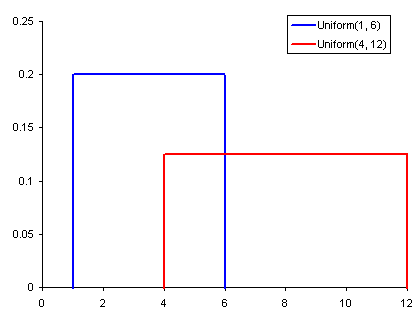
توزیع یکنواخت
یک مقدار واحد است که فقط در یک محدوده خاص اتفاق می افتد در حالی که هر چیزی خارج از آن محدوده فقط 0 است. همچنین می توانیم آن را به عنوان نشانه ای از یک متغیر طبقه ای با 2 دسته: 0 یا مقدار 1 در نظر بگیریم.
توزیع پواسون
مانند توزیع نرمال است با این تفاوت که دارای انحا و خمیدگی است. این انحنا می تواند هر از هر طرف نمودار باشد.
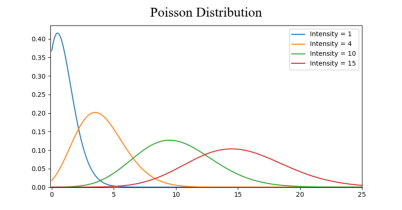
توزیع های مختلفی وجود دارد که می توان آن ها را بررسی کرد اما این سه توزیع در آمار بیشترین استفاده در علم داده را دارند. الگوریتم های زیادی وجود دارند که با توزیع نرمال کار می کنند. کافی است توزیع داده ها مشخص شود سپس الگوریتم مناسب آن ها را انتخاب کنیم.
۳.کاهش ابعاد
اگر تعداد ابعاد داده ها زیاد باشد می توانیم بدون از دست رفتن اثر داده ها ابعاد آن را کاهش دهیم. تصویر زیر مثال خوبی از تبدیل داده ها از ۳ بعد به ۲ بعد و ۱ بعد را نشان می دهد.
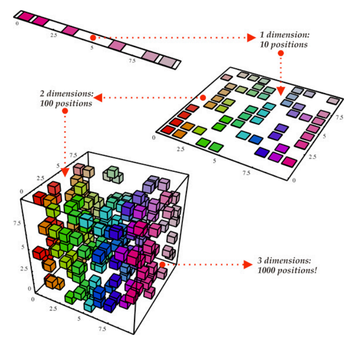
در این تصویر داده ها از ۳ بعد به ۲ بعد کاهش ابعاد داده شده اند. و در مرحله بعد به یک بعد تبدیل شده اند. در این مقاله به تفصیل راجع به کاهش ابعاد و پیاده سازی آن با پایتون صحبت کردیم.
۴.کم نمونه گیری و بیش نمونه گیری Over and Under Sampling
Over and Under Sampling تکنیک هایی هستند که برای مشکلات طبقه بندی استفاده می شوند. گاهی اوقات ، مجموعه داده های طبقه بندی ما ممکن است به شدت به یک طرف انحراف داشته باشند. به عنوان مثال ، ما 2000 نمونه برای کلاس 1 داریم ، اما فقط 200 مورد برای کلاس 2 داریم. این مشکل دقت طبقه بندی داده ها را کاهش می دهد. شکل زیر هر دو حالت را نمایش می دهد.
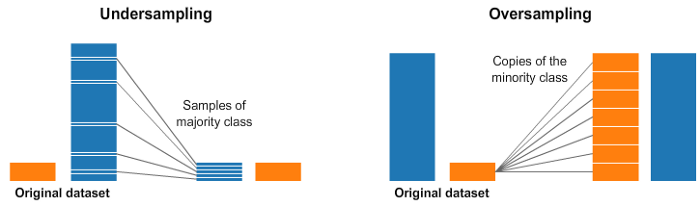
در تصویر بالا ، کلاس آبی ما نمونه های بسیار بیشتری نسبت به کلاس نارنجی دارد. در این حالت ، ما دو گزینه پیش پردازش داریم که می تواند در آموزش مدل های یادگیری ماشین ما کمک کند.
Undersampling یا کم نمونه گیری به این معنی است که ما فقط برخی از داده ها را از کلاس دارای نمونه بیشتر انتخاب خواهیم کرد. این انتخاب باید برای حفظ توزیع احتمال کلاس انجام شود. ما فقط با گرفتن کمتر نمونه ، مجموعه داده خود را یکنواخت کردیم.
Oversampling یا بیش نمونه گیری به این معنی است که ما کپی هایی از کلاس اقلیت خود ایجاد خواهیم کرد تا به همان تعداد مثال کلاس اکثریت داشته باشیم. نسخه ها به گونه ای ساخته می شوند که توزیع کلاس اقلیت حفظ شود.
مبحث آمار بخش مهمی از فرایند علم داده است. در این مطلب سعی کردیم اطلاعات اولیه مربوط به مباحث آماری مورد نیاز این علم را به شما معرفی کنیم. امیدوارم از این مقاله استفاده کرده باشید.
همجنین می توانید راهنمای کامل آمار در علم داده را نیز در این لینک مطالعه کنید