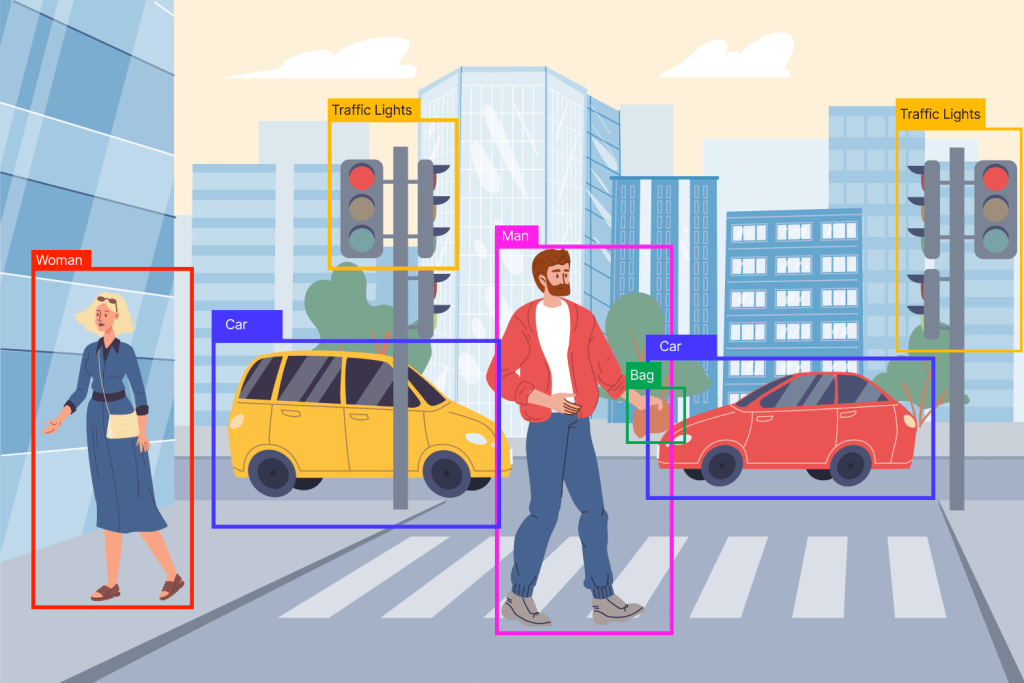
بهبود معماری یولو برای تشخیص اشیا در تصویر
روش یولو که مخفف عبارت you only look once می باشد در سال2015 ارائه شده است با استفاده از ترکیب candidate box generation و طبقهبندی بر اساس رگرشن توانست پروسه تشخیص اجسام را در یک مرحله انجام دهد. ساختار این …