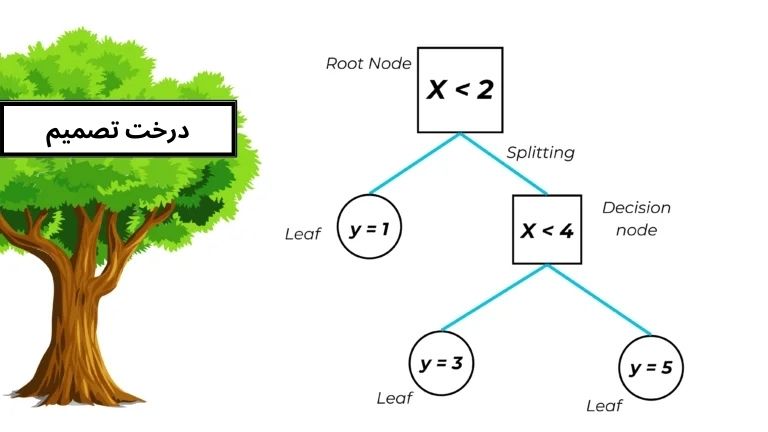
الگوریتم های یادگیری مبتنی بر درخت، یک خانواده گسترده و محبوب از روش های یادگیری با نظارت برای طبقه بندی یا دسته بندی داده ها و رگرسیون است. یکی از مزایای درخت تصمیم این است که ما می توانیم کل مدل train شده را رسم کنیم که به صورت وارونه با ریشه آن در بالا کشیده می شود. درخت تصمیم یکی از تفسیر پذیرترین مدل ها در یادگیری ماشین می باشد. اساس یادگیری آن درخت تصمیم گیری است (همانند فلوچارت می ماند) که در آن از یک سری قوانین تصمیم گیری استفاده می شود. با اولین قانون تصمیم گیری در بالا (ریشه درخت) و قوانین تصمیم گیری بعدی در زیر گسترش می یابد که گره یا node نامیده می شوند. در یک درخت تصمیم، در هر گره ی تصمیم گیری یک قانون تصمیم گیری اتفاق می افتد که منجر به گره های جدید می شوند در انتها هر درخت به برگ ‘leaf’ می رسد که هدف مسئله می باشد و کلاس را تعیین می کند.
انواع مختلفی از الگوریتم های درخت تصمیم وجود دارند: الگوریتم ID3، الگوریتم C4.5، الگوریتم CART، الگوریتم CHAID، الگوریتم MARS.
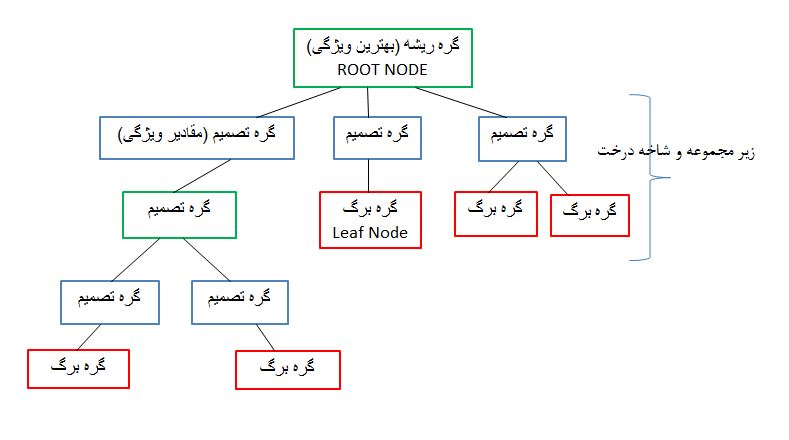
ساختار درخت تصمیم به صورت زیر است:
برای مثال فرض کنید شخصی برای شنا کردن و لذت بردن از آن می خواهد تصمیم بگیرد و فقط ویژگی های زیر در این تصمیم مورد بررسی قرار می گیرد:
ویژگی ها = آب و وهوا ( آفتابی، ابری، بارانی) – رطوبت هوا (نرمال، زیاد) – سرعت باد (قوی، ضعیف)
با توجه به ویژگی های بالا تصمیم می گیرد شنا کند یا خیر. پس مسئله دو کلاس دارد: شنا می کند: Yes شنا نمی کند: No
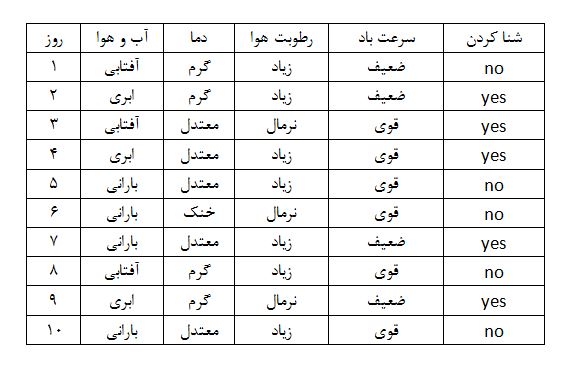
برای تصمیم گیری در مورد شنا کردن یا نکردن از این جدول می توانیم استفاده کنیم. درخت تصمیم تمام مسیرهای ممکن را که می توانند با پیروی از یک ساختار درخت مانند منجر به تصمیم نهایی شوند را در نظر می گیرد.
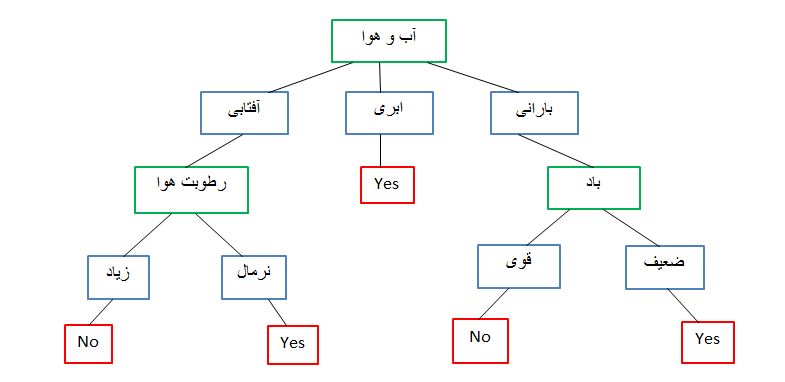
اگرچه، یک مجموعه داده واقعی ویژگی های بسیار بیشتری خواهد داشت و این فقط شاخه ای در یک درخت بسیار بزرگتر خواهد بود، اما این الگوریتم واقعا راحت و کاربردی می باشد. اهمیت ویژگی روشن است و روابط به راحتی قابل مشاهده است. توجه داشته باشین که بهترین ویژگی باید به عنوان ریشه درخت انتخاب شود، حالا سوالی که مطرح می شود این است که کدام ویژگی بهتر است؟
ویژگی ای که بیشترین کاهش ناخالصی را در یک گره ایجاد کند بهترین ویژگی است. از روش های پیدا کردن ناخالصی هر ویژگی می توان روش های Gini و Entropy را نام برد. که در اکثر کتابخانه های درخت تصمیم از Gini به صورت پیش فرض استفاده می شود.
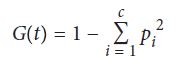
G(t) ناخالصی Gini در گره t است و pi نسبت مشاهدات کلاس c در گره t است. شاخص Gini با کسر جمع احتمالات مربع شده هر کلاس از یک محاسبه می شود. یک ویژگی با شاخص Gini پایین تر برای تقسیم انتخاب می شود. این روند یافتن قوانین تصمیم گیری که باعث ایجاد انشعابات برای افزایش ناخالصی می شود، به صورت بازگشتی تکرار می شود تا زمانی که همه گره های برگ خالص شوند (یعنی فقط شامل یک کلاس باشند).
الگوریتم ID3 از Entropy و الگوریتم CART از Gini برای ساخت درخت تصمیم استفاده می کند.
پیاده سازی درخت تصمیم با استفاده از scikit-learn به صورت زیر می باشد:
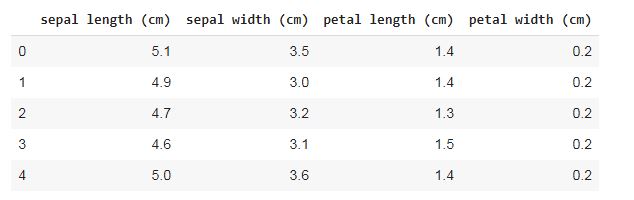
import sklearn.datasets as datasets import pandas as pd iris = datasets.load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) y = iris.target df.head()
from sklearn.tree import DecisionTreeClassifier dtree = DecisionTreeClassifier() dtree.fit(df, y)

در scikit-learn، ابزار DecisionTreeClassifier مانند سایر روش های یادگیری عمل می کند که طبق عکس بالا چندین پارامتر دارد. پس از آموزش مدل با استفاده از fit، می توانیم از مدل برای پیش بینی کلاس داده جدید استفاده کنیم.
from sklearn.externals.six import StringIO from IPython.display import Image from sklearn.tree import export_graphviz # https://pypi.org/project/pydotplus/ # pip install graphviz # conda install graphviz import pydotplus dot_data = StringIO() export_graphviz(dtree, out_file=dot_data, filled=True, rounded=True, special_characters=True) graph = pydotplus.graph_from_dot_data(dot_data.getvalue()) Image(graph.create_png())
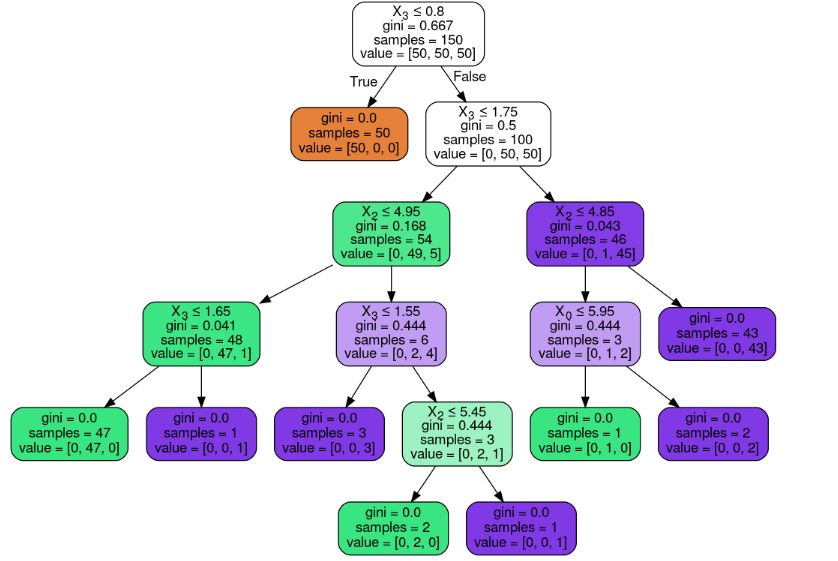
یکی از مزایای درخت تصمیم این است که می توانیم کل مدل آموزش دیده را به صورت گرافیکی رسم کنیم. مدل train شده را در قالب DOT (زبان توصیف گراف) بردیم و از آن برای ترسیم نمودار با گراف درخت تصمیم استفاده کردیم.
قبلا هم گفتیم که کتابخانه scikit-learn به صورت پیش فرض از Gini برای ساخت درخت تصمیم استفاده میکند، ولی میتوانیم با استفاده از پارامتر criterion آن را تغییر بدهیم و یک روش دیگر انتخاب کنیم:
# Create decision tree classifier object using entropy decisiontree_entropy = DecisionTreeClassifier(criterion='entropy', random_state=0) # Train model model_entropy = decisiontree_entropy.fit(features, target)
اگر بخواهیم از درخت تصمیم در برنامه ها یا گزارش های دیگر استفاده کنیم، می توانیم به راحتی آن را به صورت PDF یا تصویر PNG دربیاوریم:
# Create PDF
graph.write_pdf("iris.pdf")
True
# Create PNG
graph.write_png("iris.png")
True
همین طور که در ابتدای این بخش گفتیم از درخت تصمیم برای مسائل رگرسیون هم استفاده می شود. به مثال و کد پیاده سازی زیر توجه کنید:
# Load libraries from sklearn.tree import DecisionTreeRegressor from sklearn import datasets # Load data with only two features boston = datasets.load_boston() features = boston.data[:,0:2] target = boston.target # Create decision tree classifier object decisiontree = DecisionTreeRegressor(random_state=0) # Train model model = decisiontree.fit(features, target)
در scikit-learn برای پیاده سازی درخت تصمیم در مسائل رگرسیون از DecisionTreeRegressor استفاده می شود.
رگرسیون درخت تصمیم همانند مدل های classifiction درخت تصمیم می باشد. ولی به جای Gini یا Entropy، از MSE استفاده می شود که میانگین خطای مربع را کاهش می دهند.
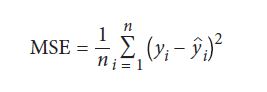
yi مقدار واقعی هدف است و yi مقدار پیش بینی شده است.
الگوریتم جنگل های تصادفی (Random Forest)
در ادامه، نحوه کار درختان تصمیم گیری، نحوه تصمیم گیری فردی درختان برای ایجاد یک جنگل تصادفی Random Forest را بررسی خواهیم کرد و در نهایت درک خواهیم کرد که جنگل های تصادفی در بسیاری از مسائل بسیار خوب و کاربردی است. نمودار زیر نحوه کار الگوریتم Random Forest را توضیح می دهد
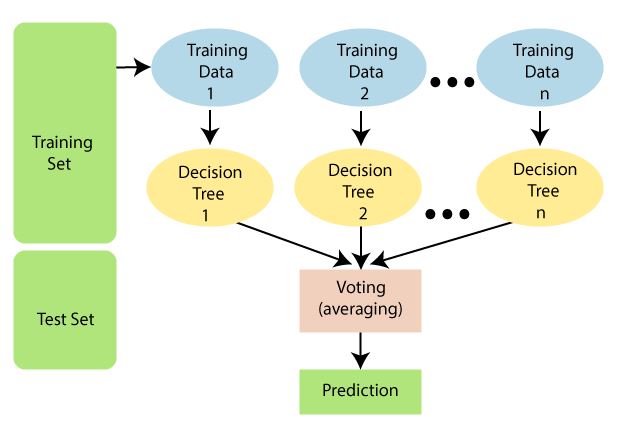
یکی از مشکلات درخت تصمیم این است که تمایل دارند که داده های آموزشی را خیلی خوب یاد بگیرند و کاملا با آن ها fit شود (که overfiting نامیده می شود). یک روش برای حل این مشکل استفاده از random forest می باشد. در random forest ، چندین درخت تصمیم tarin می شوند، اما هر درخت فقط یک نمونه از داده ها را دریافت می کند (به عنوان مثال، یک نمونه تصادفی از داده ها با جایگزینی که با تعداد اصلی داده ها مطابقت دارد) و هر گره فقط زیر مجموعه ای از ویژگی ها را هنگام تعیین بهترین تقسیم در نظر می گیرد. این جنگل از درختان تصمیم تصادفی برای تعیین کلاس پیش بینی شده انتخاب می کند. علاوه بر این Random Forest قابلیت مدیریت مجموعه داده های بزرگ با ابعاد بالا را دارد.
برای پیاده سازی آن در scikit-learn از ابزار RandomForestClassifier استفاده میکنیم:
# Load libraries from sklearn.ensemble import RandomForestClassifier from sklearn import datasets # Load data iris = datasets.load_iris() features = iris.data target = iris.target # Create random forest classifier object randomforest = RandomForestClassifier(random_state=0, n_jobs=-1) # Train model model = randomforest.fit(features, target)
عملکردش مشابه درخت تصمیم می باشد و همین طور پارامتر ها با مدل قبلی کاملا یکی است، فقط چند تا پارامتر بیشتر دارد که مخصوص این الگوریتم می باشد. اولی، پارامتر max_features حداکثر تعداد ویژگی ها را در هر گره مشخص می کند و تعدادی آرگومان از جمله عدد صحیح (تعداد ویژگی ها) ، اعداد اعشاری (درصد ویژگی ها) و sqrt (ریشه مربع تعداد ویژگی ها) را می گیرد. به طور پیش فرض، max_features عمل sqrt است. دوم، پارامتر bootstrap به ما اجازه می دهد تعیین کنیم که آیا زیرمجموعه داده های در نظر گرفته شده برای یک درخت با استفاده از نمونه برداری با جایگزینی (تنظیم پیش فرض) ایجاد می شود یا بدون جایگزینی. سوم، پارامتر n_estimators تعداد درختان تصمیم را برای گنجاندن در جنگل تعیین می کند. در روش decisionTree با n_estimators به عنوان یک ابر پارامتر رفتار کردیم.سوم، پارامتر n_estimators تعداد درختان تصمیم را برای گنجاندن در جنگل تعیین می کند. در روش decisionTree با n_estimators به عنوان یک ابر پارامتر رفتار کردیم.
همانند درخت تصمیم از random forest برای مسائل رگرسیون هم استفاده می شود. برای این کار از RandomForestRegressor درscikit-learn استفاده می کنیم:
# Load libraries from sklearn.ensemble import RandomForestRegressor from sklearn import datasets # Load data with only two features boston = datasets.load_boston() features = boston.data[:,0:2] target = boston.target # Create random forest classifier object randomforest = RandomForestRegressor(random_state=0, n_jobs=-1) # Train model model = randomforest.fit(features, target)
در همه مدل های یادگیری ماشین پیدا کردن مهم ترین ویژگی ها در دقیق بودن و تفسیر پذیر بودن مدل حائز اهمیت است. در الگوریتم random forest باید بدانیم که کدام یک از ویژگی ها مهم هستند و اهمیت هر ویژگی را محاسبه و رسم کنیم.
الگوریتم Random Forest از اهمیت ویژگی داخلی برخوردار است که به روش زیر قابل محاسبه می باشد:
اهمیت Gini (یا کاهش ناخالصی متوسط)، که در ساختار جنگل تصادفی استفاده می شود. یک Random Forest از ده ها، صدها، حتی هزاران درخت تصمیم تشکیل شده است که این تصور، درک مدل Random Forest را عملی می کند و هر درخت تصمیم مجموعه ای از گره ها و برگ های داخلی است. در گره داخلی ، از ویژگی انتخاب شده برای تصمیم گیری در مورد نحوه تقسیم داده ها به دو مجموعه جداگانه با پاسخ های مشابه استفاده می شود. ویژگی های گره های داخلی با برخی از معیارها انتخاب می شوند، که برای مسائل طبقه بندی ناخالصی Gini یا information gain می باشد و برای رگرسیون کاهش واریانس است. می توانیم اهمیت نسبی هر ویژگی را مقایسه و رسم کنیم و اندازه بگیریم که چگونه هر ویژگی ناخالصی تقسیم را کاهش می دهد (ویژگی با بیشترین کاهش برای گره داخلی انتخاب می شود). این روش در scikit-learn برای random forest (برای طبقه بندی و رگرسیون) موجود است. شایان ذکر است ، در این روش باید مقادیر نسبی ورودی های محاسبه شده را بررسی کنیم. در scikit-learn می بایست ویژگی های عددی را به چندین ویژگی باینری تقسیم کنیم. این امر باعث گسترش اهمیت آن ویژگی در تمام ویژگیهای باینری می شود مزیت این روش سرعت محاسبات است. از معایب این روش تمایل به انتخاب ویژگی های عددی و ویژگی های طبقه ای به عنوان مهمترین ویژگی است. دوم، در مورد ویژگی های وابسته می تواند یکی از ویژگی ها را انتخاب کند و از اهمیت ویژگی دوم غافل شود (که می تواند منجر به نتیجه گیری غلط شود).
# Load libraries
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn import datasets
# Load data
iris = datasets.load_iris()
features = iris.data
target = iris.target
# Create random forest classifier object
randomforest = RandomForestClassifier(random_state=0, n_jobs=-1)
# Train model
model = randomforest.fit(features, target)
# Calculate feature importances
importances = model.feature_importances_
# Sort feature importances in descending order
indices = np.argsort(importances)[::-1]
# Rearrange feature names so they match the sorted feature importances
names = [iris.feature_names[i] for i in indices]
# Create plot
plt.figure()
# Create plot title
plt.title("Feature Importance")
# Add bars
plt.bar(range(features.shape[1]), importances[indices])
# Add feature names as x-axis labels
plt.xticks(range(features.shape[1]), names, rotation=90)
# Show plot
plt.show()
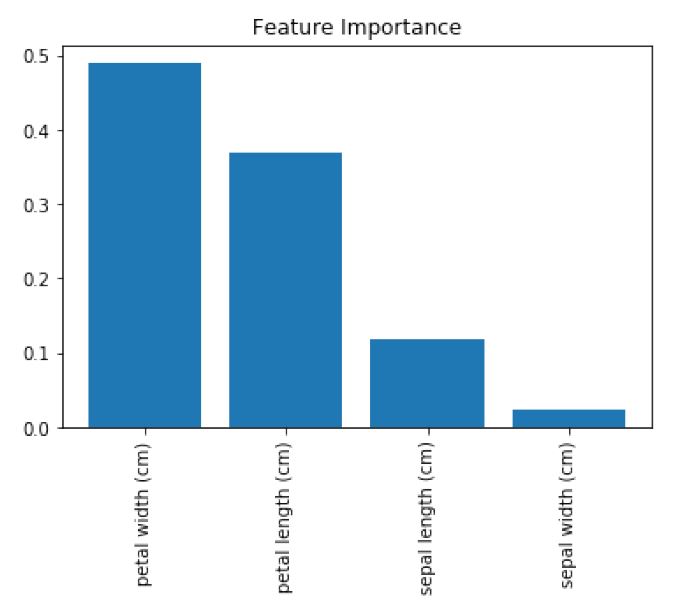
در scikit-learn ، طبقه بندی و رگرسیون decision tree و random forest می توانند اهمیت نسبی هر ویژگی را با استفاده از روش feature_importances_method گزارش دهند:
هرچه عدد بیشتر باشد، ویژگی مهمتر است (تمام نمرات اهمیت به 1 می رسد). با رسم این مقادیر می توان تفسیرپذیری را به مدل های random forest اضافه کرد.
# View feature importances model.feature_importances_ array([ 0.11896532, 0.0231668 , 0.36804744, 0.48982043])
در مواردی ممکن است بخواهیم تعداد ویژگی های مدل خود را کاهش دهیم. به عنوان مثال، ممکن است بخواهیم واریانس مدل را کاهش دهیم یا ممکن است بخواهیم تفسیر را فقط با درج مهمترین ویژگی ها بهبود بخشیم. روشی دیگر برای بهترین ویژگی این است که بیاییم ویژگی های مهم را شناسایی کنیم و فقط با استفاده از مهمترین ویژگی ها مدل را دوباره آموزش دهیم.
در scikit-learn می توانیم در دو مرحله برای ایجاد مدلی با ویژگی های کم این کار را انجام بدهیم. ابتدا یک مدل جنگل تصادفی را با استفاده از همه ویژگی ها آموزش می دهیم. سپس، از این مدل برای شناسایی مهمترین ویژگی ها استفاده می کنیم. بعد، یک ماتریس ویژگی جدید ایجاد می کنیم که فقط شامل این ویژگی ها است. در زیر، از روش SelectFromModel برای ایجاد یک ماتریس ویژگی استفاده کردیم که فقط شامل ویژگی هایی با اهمیت بیشتر یا مساوی برخی از آستانه ها است. در آخر، فقط با استفاده از این ویژگی ها مدل جدیدی ایجاد می کنیم. به کد زیر توجه کنید:
# Load libraries from sklearn.ensemble import RandomForestClassifier from sklearn import datasets from sklearn.feature_selection import SelectFromModel # Load data iris = datasets.load_iris() features = iris.data target = iris.target # Create random forest classifier randomforest = RandomForestClassifier(random_state=0, n_jobs=-1) # Create object that selects features with importance greater # than or equal to a threshold selector = SelectFromModel(randomforest, threshold=0.3) # Feature new feature matrix using selector features_important = selector.fit_transform(features, target) # Train random forest using most important featres model = randomforest.fit(features_important, target)
بررسی پارامترهای کاربردی در الگوریتم random forest:
- میتوانیم با استفاده از خطای Out-of-Bag مدل random forest را ارزیابی می کنیم که در این روش باید یک مدل جنگل تصادفی را بدون استفاده از اعتبار سنجی متقابل cross-validation ارزیابی کنیم.
در جنگل های تصادفی، هر درخت تصمیم با استفاده از زیر مجموعه داده های tarin شده آموزش می بیند. این بدان معنی است که برای هر درخت زیرمجموعه داده های جداگانه ای وجود دارد که برای tarin آن درخت استفاده نمی شود. این دادها Out-of-Bag (OOB) نامیده می شود. ما می توانیم از OOB به عنوان مجموعه آزمایشی برای ارزیابی عملکرد جنگل تصادفی خود استفاده کنیم.
برای هر داده ، الگوریتم یادگیری مقدار واقعی مشاهده را با پیش بینی زیر مجموعه ای از درختان train شده با استفاده از آن مشاهده مقایسه می کند. امتیاز کلی محاسبه می شود و اندازه گیری واحدی از عملکرد یک جنگل تصادفی را ارائه می دهد. برآورد مقدار OOB جایگزینی برای اعتبار سنجی متقابل است.
# Load libraries from sklearn.ensemble import RandomForestClassifier from sklearn import datasets # Load data iris = datasets.load_iris() features = iris.data target = iris.target # Create random tree classifier object randomforest = RandomForestClassifier( random_state=0, n_estimators=1000, oob_score=True, n_jobs=-1) # Train model model = randomforest.fit(features, target) # View out-of-bag-error randomforest.oob_score_ 0.95333333333333337
در scikit-learn ، می توانیم با تنظیم oob_score = True در RandomForestClassifier مقادیر OOB یک جنگل تصادفی را بدست آوریم. با استفاده از oob_score_ مقدار قابل بازیابی است.
2. یک مشکل رایج و معمول در مدل های یادگیری ماشینی عدم تعادل در کلاس ها ( Imbalanced classes نامیده می شود) می باشد. اکثر مسائل دنیای واقعی مانند بیماری ها، کشف تقلب و غیره به این شکل هستند. حضور کلاس های نامتعادل می تواند عملکرد مدل ما را کاهش دهد. این مورد در الگوریتم جنگا تصادفی هم صدق می کند که برای جلوگیری از آن در scikit-learn می توانیم RandomForestClassifier را برای کلاس های نامتعادل با استفاده از پارامتر class_weight تنظیم کنیم. کلاسی که کم تر و کوچک تر است وزن بیشتری به آن نسبت داده می شود. این پارمتر را در کد زییر میتوانید مشاهده کنید:
# Load libraries import numpy as np from sklearn.ensemble import RandomForestClassifier from sklearn import datasets # Load data iris = datasets.load_iris() features = iris.data target = iris.target # Make class highly imbalanced by removing first 40 observations features = features[40:,:] target = target[40:] # Create target vector indicating if class 0, otherwise 1 target = np.where((target == 0), 0, 1) # Create random forest classifier object randomforest = RandomForestClassifier( random_state=0, n_jobs=-1, class_weight="balanced") # Train model model = randomforest.fit(features, target)
3. scikit-learn این امکان را می دهد که به صورت دستی اندازه درخت تصمیم را تغییر دهید. طبق پارمتر های زیر:
max_depth : حداکثر عمق درخت. در صورت عدم وجود ، درخت رشد می کند تا زمانی که همه برگ ها خالص شوند. یک عدد صحیح می باشد که درخت تا آن عمق “هرس pruned” می شود.
min_samples_split : حداقل تعداد داده ها در یک گره قبل از تقسیم آن گره. اگر عدد صحیح باشد حداقل را تعیین می کند، اگر یک اعشاری باشد، حداقل درصد کل داده ها است.
min_samples_leaf : حداقل تعداد داده های لازم برای یک برگ.
max_leaf_nodes : حداکثر تعداد برگها.
min_impurity_split : حداقل کاهش ناخالصی قبل از انجام تقسیم مورد نیاز است.
در کد زیر تمام این موارد استفاده شده است:
# Load libraries from sklearn.tree import DecisionTreeClassifier from sklearn import datasets # Load data iris = datasets.load_iris() features = iris.data target = iris.target # Create decision tree classifier object decisiontree = DecisionTreeClassifier(random_state=0, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0, max_leaf_nodes=None, min_impurity_decrease=0) # Train model model = decisiontree.fit(features, target)
در اکثر موارد از پارامتر های max_depth و min_impurity_split استفاده می کنیم چون درختان کم عمق مدل های ساده تری هستند و بنابراین واریانس کمتری دارند.
بهبود عملکرد درخت تصمیم و جنگل تصادفی از طریق AdaBoost:
AdaBoost مخفف Adaptive Boosting، متا الگوریتمی برای یادگیری ماشین است که می تواند همراه با بسیاری از انواع دیگر الگوریتم های یادگیری برای بهبود عملکرد استفاده شود. Boosting یک تکنیک است که سعی در ایجاد یک طبقه بندی کننده قوی از تعدادی طبقه بندی کننده ضعیف دارد. AdaBoost اولین الگوریتم تقویت کننده موفقیت آمیز برای طبقه بندی باینری بود. این کار با ساخت یک مدل از داده های آموزشی انجام می شود سپس یک مدل دوم که سعی در اصلاح خطاهای مدل اول دارد ایجاد می شود. مدل ها اضافه می شوند تا زمانی که مجموعه داده های آموزشی کاملاً پیش بینی شوند یا حداکثر تعداد مدل اضافه شود.
در scikit-learn، می توانیم AdaBoost را با استفاده از AdaBoostClassifier یا AdaBoostRegressor پیاده سازی کنیم. مهمترین پارامترها base_estimator ، n_estimators و learning_rate هستند:
base_estimator الگوریتم یادگیری است که برای آموزش مدل های ضعیف استفاده می شود. این تقریباً نیازی به تغییر نخواهد داشت زیرا معمولاً بیشترین استفاده AdaBoost درخت تصمیم است.
• n_estimators تعدادی مدل برای آموزش تکراری است.
• learning_rate کاهش میزان یادگیری به معنای کم یا زیاد شدن وزن ها است ، و این مدل را مجبور به تمرین کندتر می کند و پیش فرض 1 است.
# Load libraries from sklearn.ensemble import AdaBoostClassifier from sklearn import datasets # Load data iris = datasets.load_iris() features = iris.data target = iris.target # Create adaboost tree classifier object adaboost = AdaBoostClassifier(random_state=0) # Train model model = adaboost.fit(features, target)
در این بخش تقریبا همه موارد مربوط به درخت تصمیم و پیاده سازی آن با پایتون را بررسی کردیم. درخت تصمیم یکی از معروف ترین الگوریتم های یادگیری ماشین می باشد که بر یک منطقه وسیع از یادگیری ماشین تاثیر گذاشته است و هم در مسائل طبقه بندی و هم در مسائل رگرسیون کاربرد دارد و همان طور که از نام آن پیداست از الگوی تصمیم گیری درخت مانند استفاده می کند.