
در این پروژه قصد داریم توییت های مردم آلمان در مورد سیل سال 2021 را بررسی کنیم تا از طریق یافتن الگوهای موجود در این توییت ها بتوانیم با رصد شبکه های اجتماعی وقوع حوادث طبیعی مانند سیل، زلزله، اتشفان و … را در کمترن زمان شناسایی تا بتوانیم به آسیب دیدگان کمک رسانی کنیم.
مهم ترین چالش های موجود در این پروژه جمع آوری دیتا از توییتر و استخراج دسته های با معنی از این توییت ها بود. برای این منظور از API توییتر برای جمع آوری داده ها و کتابخانه PyLDA برای مدلسازی موضوعی(Topic Modeling) داده ها استفاده شد.
جمع آوری توییت ها
در گام اول بایستی توییت ها در باز زمانی مقرر جمع آوری می شدند. کتابخانه tweepy بهترین ابزار برای این کار است. برای کار با این کتابخانه نیاز به Brear code توییتر است. با ثبت نام و درخواست در بخش توسعه دهنده های توییتر می توان این کد را بدست آورد.
برای جمع آوری داده ها بایستی هشتگ های مورد نظر به همراه زمان مورد در خواست را معیین کرد سپس اقدادم به جمع آوری داده ها نمود. از ۲ روز قبل از سیل تا روز واقعه توییت هایی که شامل هشتگ های که مروبط به سیل مانند: سیل، فاجعه، بارندگی و… جمع و در یک فایل اکسل به صورت زیر ذخیره شد. برای راحنی در درک متن توییت ها، تمامی آن ها با کمک گوگل ترنسلیت به زبان انگلیسی ترجمه شدند. به صورت زیر.
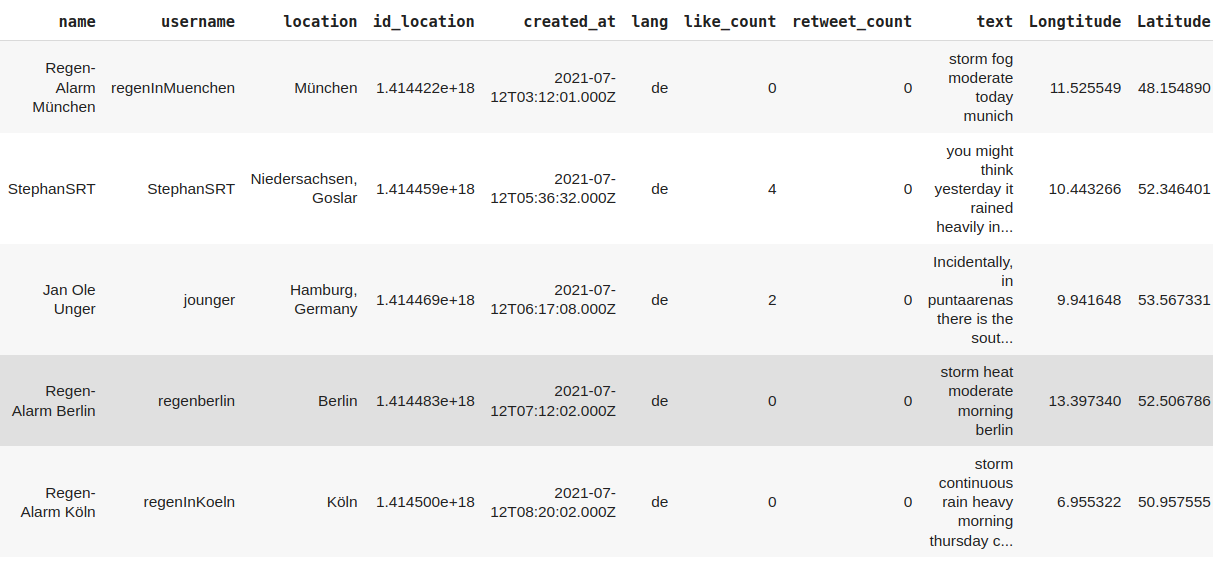
بخش مهم و دشوار کار جمع آوری داده ها اضافه کردن مختصات حدودی ارسال کنند توییت بود. چون نیاز بود مشخص شود مردمی که در گیر سیل هستند در چه نقاطی قرار دارند.
تمیز کردن توییت ها
در پروژه های مربوط به شبکه های اجتماعی به ویژه توییتر بخش قابل توجهی از کار به تمیز کردن داده ها اختصاص می یابد. در مرجله اول URL ها از متن داده ها حذف شد. در ادامه تگ های HTML، ایموجی ها، هشتگ ها و منشن ها، ایمیل هاو فضاهای خالی حذف شدند. خروجی این بخش متن اصلی توییت های کاربران است. نمونه توییت بعد از پاکسازی به صورت زیر است.

lemmatization کردن داده ها
منظور از lemmatization بازگرداندن کلمات به ریشه اصلی آن است. عمل ریشه یابی کمک می کند کلمات به ظاهر نگارشی متفاوت به یک کلمه با ریشه یکسان برسند. کلماتی مانند رفتن، رویم، برو، همگی یک ریشه دارند. با این کار از پیچیدگی متن کاسته و کمک می کنیم مدل انتهایی درک بهتری از متن داشته باشد. برای lemmatization کردن کلمات از کتابخانه spaCy کمک گرفتیم که یک کتابخانه بسیار قوی در زمینه کار با داده های متنی و پردازش زبان طبیعی است. خروجی متن بعد از ریشه یابی به صورت زیر است.

توکن بندی و حذف کلمات ناخواسته(Stop Words)
در مرحله بعدی با کمک کتابخانه NLTK توییت های توکن بندی شده و کلمات ناخواسته حذف می شوند. خروجی به صورت زیر است.

Bigram (بای گرم)
توکن بندی باعث می شود کلماتی که به صورت ترکیبی بایکدیگر استفاده می شوند به صورت جدا پردازش شوند که باعث پایین آمده دقت در نتایج می شود. برای مثال در زبان فارسی کلمه “جست و جو” به صورت ترکیبی استفاده می شود. با توکن بندی و حذف Stopwords تبدیل به “جست” و “جو” می شوند که به تنهایی بی معنی هستند. برای حل این مساله از روش Bigram استفاده می کنیم که به جای آن که هر یک کلمه مبنای محاسبات باشد واحد های دوتایی را هم حساب می کنیم. برای این کار از کتابخانه Gensim استفاده می کنیم.
TF-IDF
روشی است که در آن اهمیت یک کلمه در مقایسه با کل متن مورد محاسبه قرار می گیرد. با این روش وزن کلمات مشخص شده و کلماتی که وزن نزدیک به صفر دارند حذف می شوند.
LDA چیست؟
LDA خلاصه عبارت Latent Dirichlet Allocation یک روش برای مدلسازی موضوعی کلمات است. برای فهم این روش ابتدا معنی این کلمات را بررسی می کنیم. Latent به معنی مخفی و پنهان است. چیزی که باید کشف شود. Dirichlet نشان می دهد که مدل فرض می کند که موضوعات موجود در اسناد و کلمات در آن موضوعات از توزیع دیریکله پیروی می کنند. Allocation به معنای دادن چیزی است که در این مورد موضوعی است.
LDA فرض می کند که اسناد با استفاده از یک فرآیند تولیدی آماری تولید می شوند، به طوری که هر سند ترکیبی از موضوعات و هر موضوع ترکیبی از کلمات است. با کمک کتابخانه Gensim مدل LDA برای داده بدست آمد. خروجی LDA دسته هایی با نسبت عددی هستند که مهم ترین موضوعات و کلمات را مشخص می کند. این خروجی برای کاربران تفسیر پذیری کمی دارد. به همین دلیل کتابخانه ای معرفی شد که بتواند به صورت گرافیکی هم این دسته ها و کلمات را نشان دهد. این کتابخانه PyLDAvis نام دارد.
PyLDAvis مدل ساخت شده Gensim را دریافت و به صورت نمودار گرافیکی پویا تبدیل می کند. خروجی کار به صورت زیر است.
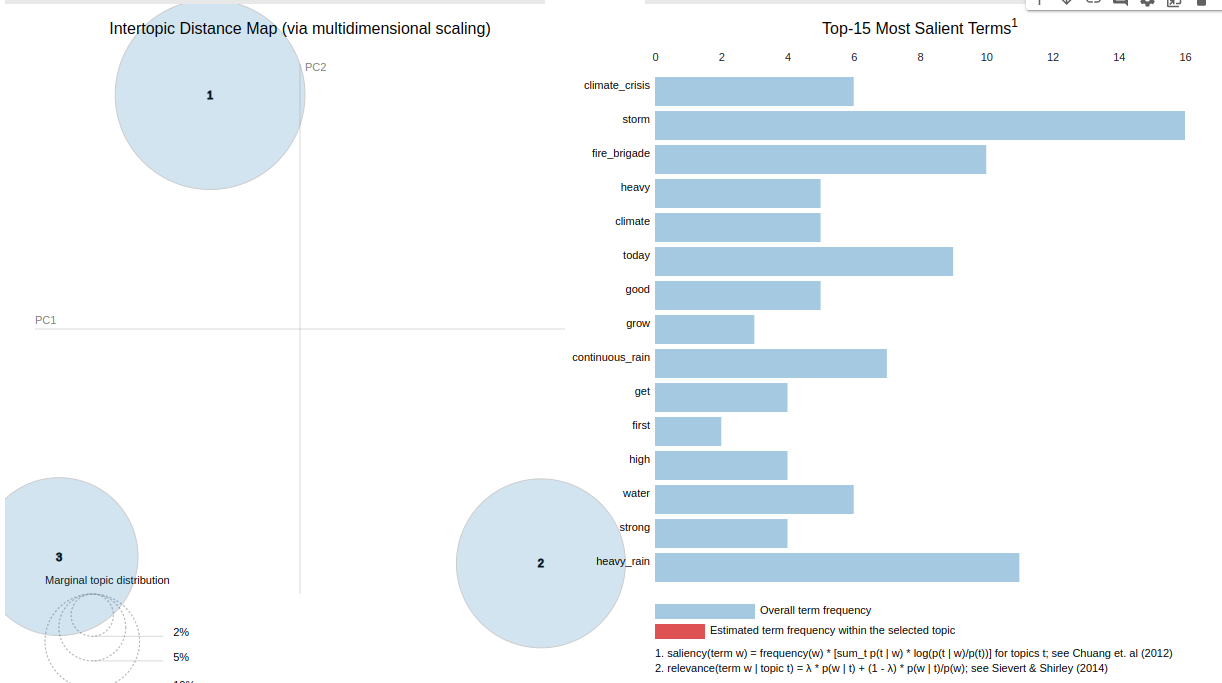
ما برای این پروژه تعداد موضوعات موجود در متن را ۳ انتخاب کردیم. فاصله زیاد این دسته ها با یکدیگر در نمودار نشان دهند عملکرد قابل قبول در پیاده سازی داده است. لیست مهم ترم کلمات در تصویر مشخص است. اگر بر روی هر یک از دایره ها(موضوعات) کلیک کنیم کلمات و موضوعات موجود در آن دسته مشخص می شود. به صورت زیر.
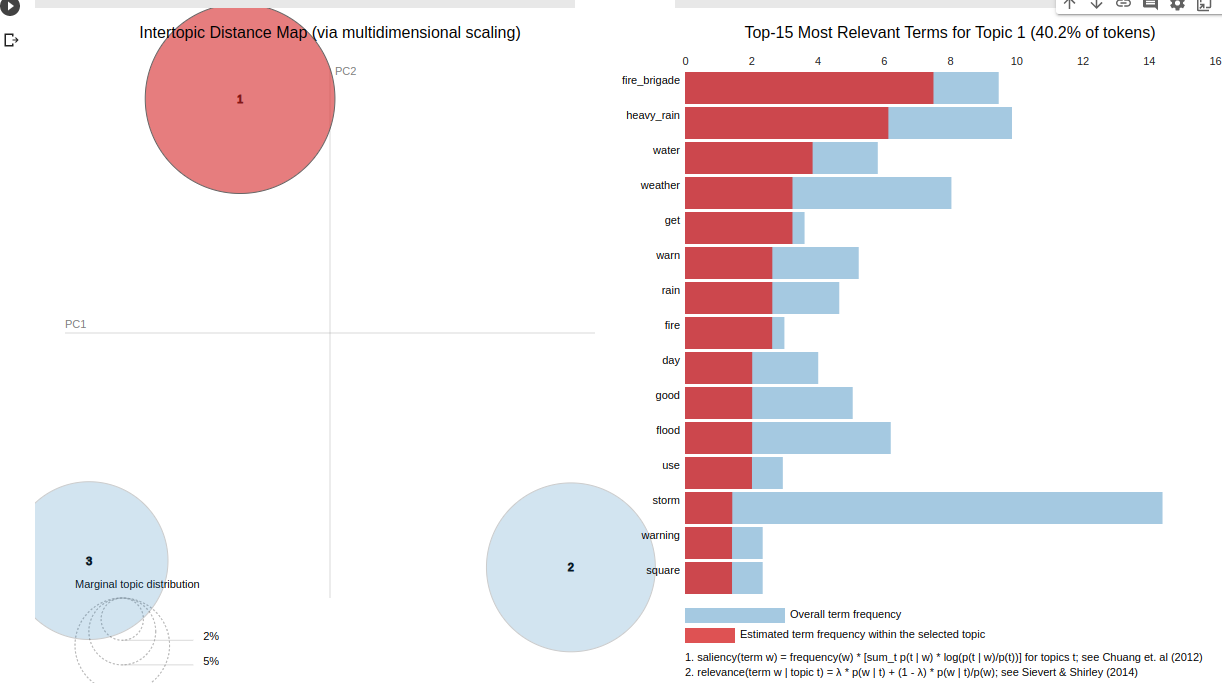
از کلمات موجود در هر دسته مشخص است که ارتباط معنایی خوبی بین این کلمات وجود دارد و عبارات هم معنی در یک دسته قرار گرفته اند.
تعداد دسته ها میزان حساسیت و یکتا بودن کلمات و همچنین تعداد کلمات قابل نمایش در هر دسته را می توان توسط پارامتر های ورودی تعیین و تغییر داد.
خلاصه و نتیجه گیری
هدف از انجام این پروژه دسته بندی موضوعی (Topic Modeling) بر روی داده های توییتر بود. برای این کار ابتدا داده ها را در بازه زمانی تعیین شده توسط API توییتر جمع آوری کردیم. داده جمع آوری شده را با فرمت اکسل ذخیره کردیم و اقدام به پاکسازی آن ها نمودیم. سپس با استفاده روش های پردازش متن آن ها را آماده کار نهایی کردیم. از کتابخانه Gensim برای Topic Modeling و کتابخانه PyLDAvis برای مصورسازی خروجی استفاده کردیم.