مثال کاربردی طبقه بندی داده ها با پایتون
به طور کلی به مساله هایی که در داده های آن یک ستون کلاس وجود داشته باشد طبقه بندی می گویند. این ستون توسط شخصی که داده را آنالیز می کند مشخص می شود به همین دلیل در داده کاوی …
مرجع آموزش علم داده
Data Mining به کاربرد آمار در قالب تجزیه و تحلیل داده های اکتشافی و مدل های پیش بینی کننده برای یافتن الگوها و روند داده ها از داده های موجود استفاده می شود.
داده کاوی عموما توسط شرکتها برای تبدیل داده های خام به اطلاعات مفید استفاده می شود.با جستجوی الگوهای در دسته های بزرگ از داده ها ، مشاغل می توانند در مورد مشتریان خود اطلاعات بیشتری کسب کنند تا استراتژی های بازاریابی مؤثرتری را توسعه دهند ، فروش را افزایش دهند و هزینه های خود را کاهش دهند.
مشاغل مرتبط: دانشمند داده ، تحلیلگر تجارت ، آمارشناس
به طور کلی به مساله هایی که در داده های آن یک ستون کلاس وجود داشته باشد طبقه بندی می گویند. این ستون توسط شخصی که داده را آنالیز می کند مشخص می شود به همین دلیل در داده کاوی …
استفاده از سیستم های توصیه گر هر روز در حال افزایش است .دراین مقاله قصد داریم یک سیستم توصیه گر ساده بر روی مجموعه داده سایت MovieLens طراحی کنیم.
یکی از دلهره آورترین تصمیماتی که برنامه نویسان هنگام گرفتن یک پروژه جدید می گیرند انتخاب زبان برنامه نویسی مناسب است. Python و R بدون شک در هنگام انتخاب یک زبان برنامه نویسی برای یک پروژه علم داده (Data Science …
مقایسه زبان python و R برای کار در حوزره علم داده ادامه مطلب »
مهندس داده و دانشمند داده دوتا از پرمخاطب ترین شغل های حوزه علم داده هستند. ولی تفاوت این شغل ها برای بسیاری مبهم و نامشخص است. در این مطلب قصد داریم این دو شغل را بررسی کینم و تفاوت آن ها با هم مقایسه کنیم.
کلان داده یا بیگ دیتا زمینه است که هر روز در حال افزایش است. به همین جهت دانستن مفاهیم و الزامات این حوزه ضروری بنظر می رسد. در این مقاله قصد داریم ۵ نکته مهم در زمینه بیگ دیتا را با هم بررسی کنیم.
تحلیل رگرسیون از مجموعه ای از روش های یادگیری ماشین تشکیل شده است که برای پیش بینی یک مقدار پیوسته از مدل های رگرسیون استفاده می شود. پیش بینی قیمت های خانه با توجه به ویژگی های خانه مانند اندازه ، قیمت و غیره یکی از نمونه های متداول رگرسیون است. این یک تکنیک با نظارت است. رگرسیون خطی یکی از ساده ترین الگوریتم های یادگیری با نظارت در مجموعه ابزارها می باشد که دو نوع ساده و چند گانه دارد.
خوشه بندی یکی از بخش های هوش منصوعی است که شامل گروه بندی نقاط داده می شود. با توجه به مجموعه ای از نقاط داده ، می توان از یک الگوریتم خوشه بندی برای طبقه بندی هر نقطه داده به …
6 الگوریتم خوشه بندی (clustering) که متخصصین علم داده باید بدانند ادامه مطلب »
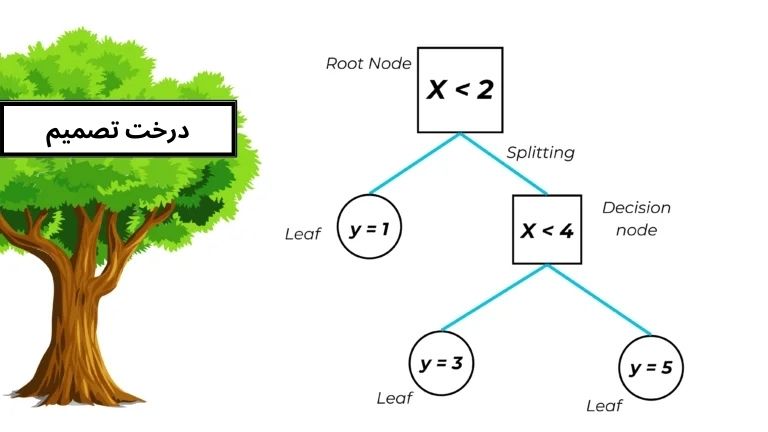
درخت تصمیم یکی از معروف ترین الگوریتم های یادگیری ماشین می باشد که بر یک منطقه وسیع از یادگیری ماشین تاثیر گذاشته است و هم در مسائل طبقه بندی و هم در مسائل رگرسیون کاربرد دارد و همان طور که از نام آن پیداس از الگوی تصمیم گیری درخت مانند استفاده می کند. درخت تصمیم یکی از تفسیر پذیرترین مدل ها در یادگیری ماشین می باشد و در پایتون با استفاده از scikit-learn میتواند آن را به راحتی پیاده سازی کرد.
انتخاب ویژگی ها و کاهش ابعاد به ما این امکان را می دهد تعداد ویژگی های یک مجموعه داده را فقط با حفظ ویژگی های مهم به حداقل برسانیم. مزایای مختلفی در انجام انتخاب ویژگی و کاهش ابعاد وجود دارد که شامل تفسیرپذیری مدل، به حداقل رساندن بیش از حد مناسب و همچنین کاهش اندازه مجموعه train و در نتیجه زمان train است.
مدل RFM یک روش محبوب و کارا برای تجزیه و تحلیل مشتریان است. در این روش از ۳ معیار اخرین خرید مشتری، تعداد دفعات خرید و مبلغ خرید استفاده می شود. با استفاده از این معیار ها مدل RFM طراحی می شود. با روش های مصور سازی داده اطلاعات بدست آمده از مدل نمایش داده می شود.